使用python爬取百度贴吧分页
本篇讲如何爬取百度贴吧,并翻页。
一、方法
按照爬取一个网页的步骤分为:
-
确定目标网址(url)
-
发送网络请求,(模拟正常用户),得到对应的响应数据
-
提取出特定的数据
-
保存,本地,入库
这里因为要爬取多个百度贴吧页面,所以使用for循环就可以使用url参数的规律变化,实现翻页。
在python中,本次爬取需要用到requests库
安装指令:
程序第一步,先引入requests库:
设置程序入口pycharm快捷指令main:
然后设置要爬取的贴吧内容以及要爬取的页数:

因为要爬取输入的相应页数,所以要使用到for循环:
然后找到目标网址,这里有两种方式
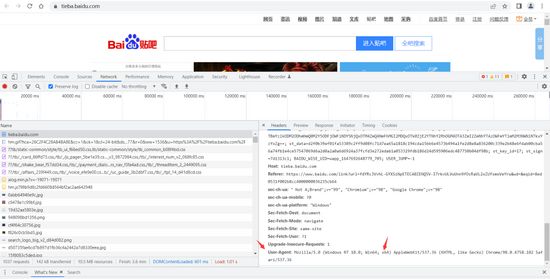
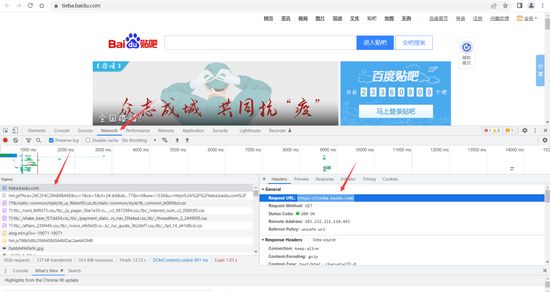
第一种就是百度贴吧的域名网址,但是使用域名网址可能会爬取失败,所以第二种就是:按电脑键盘F12检查网址,然后进入network,点击下面显示的第一个,右边的RequestsURL就是目标网址

找到目标网址之后要设置用户代理,这样爬取的时候,目标网址就会把你当成是一名正常的用户,而不是一名爬虫。
代理用户的找到方式如图:

在找到目标网址的最下面,有个user-agent,整个复制到python里面
然后在标红位置冒号两边都加上引号,就成了上面的效果,冒号后面的引号一定要加在数据之前,中间空格也不要删掉,不然程序会报错。

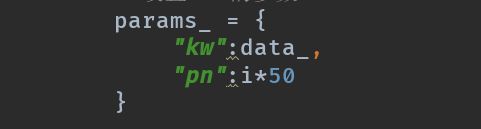
接下来就是设置url的参数了
Kw就是搜索到的结果,pn是页数,这里找到的规律是第二页是50,第三页是100,第四页是150,所以就找到规律,没翻一次页数都是上一页50的倍数加1,所以这里定义为i*50,因为是在循环里面,所以第一次循环,pn就为0就是第一页,第二次循环i=1,pn就为50,就是第二页,依次往后推。
然后就是发送网络请求,得到响应,定义一个response_来表示发送请求之后得到的数据,使用get方法发送请求,get方法里面就是目标网址,还有就是代理用户headers,然后就是url传入的参数。
得到response_之后,要获取到里面的内容,因为使用response_.content
获取到的内容是bytes(字节)类型,所以要转换成字符串类型。所以定义一个str_data = response_content.decode() 来接收解码成字符串之后的数据。因为网站的数据格式是utf-8,encoding默认是解码成utf-8,所以这里面不用写,如果是其他格式就要写了,可能会有gbk格式。
最后保存文件,使用格式化输出,文件名中{data_}表示要爬取的名字,{i+1}就代表爬取的页数,使用’w’,就是文件写入字符串

encoding=”utf-8”就是网站的数据格式是utf-8,最后将之前得到的数据写到该文件里面,保存为html文件。
最终代码如下:
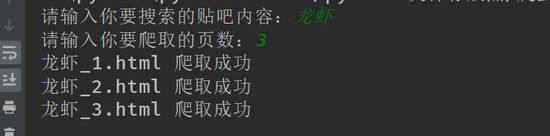
效果如下:
![]()
运行html文件之后就是如下页面:
二、实验结果与讨论
爬取百度贴吧完整代码 1
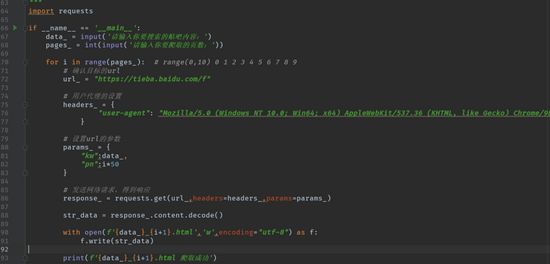
import requests
if __name__ == '__main__':
data_ = input('请输入你要搜索的贴吧内容:')
pages_ = int(input('请输入你要爬取的页数:'))
for i in range(pages_): # range(0,10) 0 1 2 3 4 5 6 7 8 9
# 确认目标的url
url_ = "https://tieba.baidu.com/f"
# 用户代理的设置
headers_ = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
}
# 设置url的参数
params_ = {
"kw":data_,
"pn":i*50
}
# 发送网络请求,得到响应
response_ = requests.get(url_,headers=headers_,params=params_)
str_data = response_.content.decode()
with open(f'{data_}_{i+1}.html','w',encoding="utf-8") as f:
f.write(str_data)
print(f'{data_}_{i+1}.html 爬取成功')
三、结语
本篇,分享一个爬取百度贴吧的案例,整个爬虫的流程就是上述步骤,爬取一个页面多页就是利用循环的思想,当然在输入爬取多少页的时候,不要一次性爬取太多,这样会被目标网址识别出来是爬虫,可能ip会被该目标网址封掉,然后每次访问的时候都会被该目标网址拒绝。