【DataWhale打卡】1. 数据加载及探索性数据分析
read_csv和read_table都是是加载带分隔符的数据,每一个分隔符作为一个数据的标志,但二者读出来的数据格式还是不一样的,
read_csv的默认分隔符是逗号,read_table是以制表符 \t 作为数据的标志,也就是以行为单位进行存储。
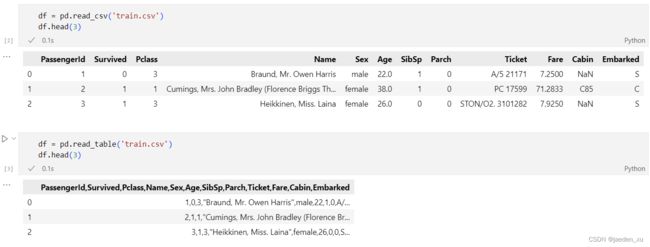
read_csv读完后是一个有多行多列的数组,每一个字符串作为一列用read_table读完后每个字符串之间有逗号相隔,表明每一行作为一个维度进行了存储,每一行字符串为一列而不是每一个字符串。
数据文件的格式很多,最常用的是 .csv,.xls 和 .txt 文件,以及 sql 数据库文件的读取。
不同格式的使用案例
(1)读取 .csv 文件:
df = pd.read_csv("./example.csv", engine="python", encoding="utf_8_sig")
# engine="python"允许处理中文路径,encoding="utf_8_sig"允许读取中文数据
(2)读取 .xls 文件:
df = pd.read_excel("./example.xls", sheetname='Sheet1', header=0, encoding="utf_8_sig")
# sheetname 表示读取的sheet,header=0 表示首行为标题行, encoding 表示编码方式
(3)读取 .txt 文件:
df = pd.read_table("./example.txt", sep="\t", header=None)
# sep 表示分隔符,header=None表示无标题行,第一行是数据
(4)读取.json文件
import json
#读取文件全部内容,并以字典的形式返回
file = open("./example.json")
t = json.load(file)
逐块读取:将数据分成小块按块读入,得到的对象指向了多个分块对象,但并没有将实际数据先读入,而是在提取数据时才将数据提取进来。
原因:在处理很⼤的⽂件时,可将大文件拆分成小块按块读入后,这样可减少内存的存储与计算资源。数据的处理和清洗经常使用分块的方式处理,这能大大降低内存的使用量,但相比会更耗时一些。
chunker
![]()
for data in chunker:
print(data)

# 替换
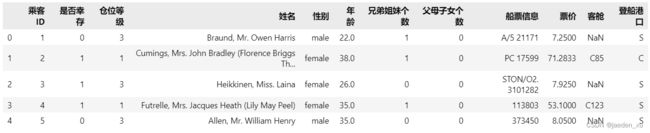
df.columns =['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口']
df.head(5)
df.describe()

#思考回答
test_1.drop(['a'],axis=1,inplace=True)
test_1.head()
reset_index()
使用索引重置生成一个新的DataFrame或Series,可以把索引用作列
pandas以类似字典的方式来获取某一列的值,比如df[‘A’],这会得到df的A列。如果我们对某一行感兴趣呢?这个时候有两种方法,一种是iloc方法,另一种方法是loc方法。loc是指location的意思,iloc中的i是指integer。这两者的区别如下:
loc:works on labels in the index.
iloc:works on the positions in the index (so it only takes integers).
也就是说loc是根据index来索引,比如下边的df定义了一个index,那么loc就根据这个index来索引对应的行。iloc并不是根据index来索引,而是根据行号来索引,行号从0开始,逐次加1。
text.sort_values(by=['票价', '年龄'], ascending=False).head(3)
