花书《深度学习》代码实现:02 概率部分:概率密度函数+期望+常见概率分布代码实现
1 概率
1.1 概率与随机变量
- 频率学派概率 (Frequentist Probability):认为概率和事件发⽣的频率相关。
- 贝叶斯学派概率 (Bayesian Probability):认为概率是对某件事发⽣的确定程度,可以理解成是确信的程度。
- 随机变量 (Random Variable):⼀个可能随机取不同值的变量。例如:抛掷⼀枚硬币,出现正⾯或者反⾯的结果
2 概率分布
2.1 概率质量函数
2.1.1 定义
对于离散型变量,我们先定义⼀个随机变量,然后⽤~符号来说明它遵循的分布:x∼P(x),函数P是随机变量x的PMF。
2.1.2 举例
⼀个离散型x有k个不同的值,我们可以假设x是均匀分布的(也就是将它的每个值视为等可能的),通过将它的PMF设为
对于所有的i都成⽴。
2.2 概率密度函数
研究的对象是连续型时,可以引⼊同样的概念。
2.2.1 定义
如果⼀个函数 p 是概率密度函数:

2.2.2 举例
在 (a; b) 上的均匀分布:

分母表示在(a,b)内为1,否则为0。
2.3 累积分布函数(Cummulative Distribution Function)
累积分布函数表示对小于 x 的概率的积分:
2.4 代码实现:均匀分布
# 函数功能:返回范围内的均匀分布
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import uniform
# 生成样本
fig, ax = plt.subplots(1, 1)
r = uniform.rvs(loc=0, scale=1, size=1000)
ax.hist(r, density=True, histtype='stepfilled', alpha=0.5)
# numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
# (返回的是 [start, stop]之间的均匀分布)
# start:返回样本数据开始点
# stop:返回样本数据结束点
# num:生成的样本数据量,默认为50
# endpoint:True则包含stop;False则不包含stop
# retstep:即如果为True,则结果会给出数据间隔
# dtype:输出数组类型
# axis:0(默认)或-1
# 均匀分布 pdf
x = np.linspace(uniform.ppf(0.01), uniform.ppf(0.99), 100)
ax.plot(x, uniform.pdf(x), 'r-', lw=5, alpha=0.8, label='uniform pdf')
plt.show()
2.5 条件概率与条件独立
2.5.1 边缘概率 (Marginal Probability)
如果已知⼀组变量的联合概率分布,但想了解其中⼦集的概率分布。这种定义在子集上的概率分布被称为边缘概率分布。

2.5.2 条件概率(Conditional Probability)
在很多情况下,我们感兴趣的是某个事件,在给定其他事件发⽣时出现的概率。这种概率叫做条件概率。

2.5.3 条件概率的链式法则 (Chain Rule of Conditional Probability)
任何多维随机变量的联合概率分布,都可以分解成只有⼀个变量的条件概率相乘形式

2.5.4 独立性 (Independence)
两个随机变量 x 和 y,如果它们的概率分布可以表⽰成两个因⼦的乘积形式,并且⼀个因⼦只包含 x 另⼀个因⼦只包含y,我们就称这两个随机变量是相互独⽴的。

2.5.5 条件独立性 (Conditional Independence)
如果关于 x 和 y 的条件概率分布对于 z 的每⼀个值都可以写成乘积的形式,那么这两个随机变量 x 和y 在给定随机变量 z 时是条件独⽴的。

2.6 随机变量的度量
2.6.1 期望
期望(Expectation):函数f关于概率分布P(x)或p(x)的期望表⽰为由概率分布产⽣x,再计算f作⽤到x上后f(x)的平均值。
期望是线性的:
2.6.2 离散型随机变量的期望
通过求和得到:
2.6.3 连续型随机变量的期望
连续型随机变量可以通过求积分:
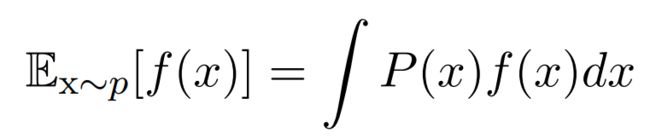
2.6.4 方差(Variance)
衡量的是当我们对 x 依据它的概率分布进⾏采样时,随机变量 x 的函数值会呈现多⼤的差异,描述采样得到的函数值在期望上下的波动程度:

2.6.5 标准差 (Standard Deviation)
将⽅差开平⽅即为标准差。
2.6.6 协方差
⽤于衡量两组值之间的线性相关程度:
独⽴⽐零协⽅差要求更强,因为独立还排除了非线性的相关。
2.7 代码实现:协方差
import numpy as np
x = np.array([1,2,3,4,5,6,7,8,9])
y = np.array([9,8,7,6,5,4,3,2,1])
Mean = np.mean(x)
Var = np.var(x) # 默认总体方差
Var_unbias = np.var(x, ddof=1) # 样本方差(无偏方差)
Cov = np.cov(x,y)
print("平均值:",Mean) # 5.0
print("总体方差:",Var) # 6.666666666666667
print("样本方差(无偏方差):",Var_unbias) # 7.5
print("协方差:",Cov) # [[ 7.5 -7.5] [-7.5 7.5]]3 常见概率分布
3.1 伯努利分布 (两点分布) (Bernoulli Distribution)
3.1.1 定义

3.1.2 代码实现:伯努利分布
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import bernoulli
def plot_distribution(X, axes=None):
""" 给定随机变量,绘制 PDF, PMF, CDF"""
if axes is None:
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
x_min, x_max = X.interval(0.99)
x = np.linspace(x_min, x_max, 1000)
if hasattr(X.dist, 'pdf'): # 判断有没有 pdf,即是不是连续分布
axes[0].plot(x, X.pdf(x), label="PDF")
axes[0].fill_between(x, X.pdf(x), alpha=0.5) # alpha 是透明度, alpha=0 表示 100% 透明, alpha=100 表示完全不透明
else: # 离散分布
x_int = np.unique(x.astype(int))
axes[0].bar(x_int, X.pmf(x_int), label="PMF") # pmf 和 pdf 是类似的
axes[1].plot(x, X.cdf(x), label="CDF")
for ax in axes:
ax.legend()
return axes
fig, axes = plt.subplots(1, 2, figsize=(10, 3)) # 画布
p = 0.3
X = bernoulli(p) # 伯努利分布
plot_distribution(X, axes=axes)
plt.show()
possibility = 0.3
def trials(n_samples):
samples = np.random.binomial(n_samples, possibility) # 成功的次数
proba_zero = (n_samples-samples)/n_samples
proba_one = samples/n_samples
return [proba_zero, proba_one]
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
# 一次试验, 伯努利分布
n_samples = 1
axes[0].bar([0, 1], trials(n_samples), label="Bernoulli")
# n 次试验, 二项分布
n_samples = 1000
axes[1].bar([0, 1], trials(n_samples), label="Binomial")
for ax in axes:
ax.legend()
plt.show()

3.2 范畴分布 (分类分布) (Multinoulli Distribution)
3.2.1 定义
范畴分布是指在具有 k 个不同值的单个离散型随机变量上的分布
3.2.2 代码实现:范畴分布 (分类分布)
import numpy as np
import matplotlib.pyplot as plt
def k_possibilities(k):
"""
随机产生一组 10 维概率向量
"""
res = np.random.rand(k)
_sum = sum(res)
for i, x in enumerate(res):
res[i] = x / _sum
return res
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
# 一次试验, 范畴分布
k, n_samples = 10, 1
samples = np.random.multinomial(n_samples, k_possibilities(k)) # 各维度“成功”的次数
axes[0].bar(range(len(samples)), samples/n_samples, label="Multinoulli")
# n 次试验, 多项分布
n_samples = 1000
samples = np.random.multinomial(n_samples, k_possibilities(k))
axes[1].bar(range(len(samples)), samples/n_samples, label="Multinomial")
for ax in axes:
ax.legend()
plt.show()
3.3 高斯分布 (正态分布)
3.3.1 定义

![]()
中⼼极限定理 (Central Limit Theorem) 认为,⼤量的独⽴随机变量的和近似于⼀个正态分布,因此可以认为噪声是属于正态分布的。
3.3.2 代码实现:正态分布
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
def plot_distribution(X, axes=None):
""" 给定随机变量,绘制 PDF, PMF, CDF"""
if axes is None:
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
x_min, x_max = X.interval(0.99)
x = np.linspace(x_min, x_max, 1000)
if hasattr(X.dist, 'pdf'): # 判断有没有 pdf,即是不是连续分布
axes[0].plot(x, X.pdf(x), label="PDF")
axes[0].fill_between(x, X.pdf(x), alpha=0.5) # alpha 是透明度, alpha=0 表示 100% 透明, alpha=100 表示完全不透明
else: # 离散分布
x_int = np.unique(x.astype(int))
axes[0].bar(x_int, X.pmf(x_int), label="PMF") # pmf 和 pdf 是类似的
axes[1].plot(x, X.cdf(x), label="CDF")
for ax in axes:
ax.legend()
return axes
fig, axes = plt.subplots(1, 2, figsize=(10, 3)) # 画布
mu, sigma = 0, 1
X = norm(mu, sigma) # 标准正态分布
plot_distribution(X, axes=axes)
plt.show()
3.4 多元高斯分布 (多元正态分布)
3.4.1 定义

3.4.2 代码实现:
import numpy as np
from scipy.stats import multivariate_normal
import matplotlib.pyplot as plt
x, y = np.mgrid[-1:1:.01, -1:1:.01]
pos = np.dstack((x, y))
fig = plt.figure(figsize=(4,4))
axes = fig.add_subplot(111)
mu = [0.5, -0.2] # 均值
sigma = [[2.0, 0.3], [0.3, 0.5]] # 协方差矩阵
X = multivariate_normal(mu, sigma) # 多元高斯分布
axes.contourf(x, y, X.pdf(pos))
plt.show()
3.5 指数分布 (Exponential Distribution)
3.5.1 定义

是用于在x=0处获得最⾼的概率的分布,其中λ>0是分布的⼀个参数,常被称为率参数。
3.5.2 代码实现:指数分布
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import expon
def plot_distribution(X, axes=None):
""" 给定随机变量,绘制 PDF, PMF, CDF"""
if axes is None:
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
x_min, x_max = X.interval(0.99)
x = np.linspace(x_min, x_max, 1000)
if hasattr(X.dist, 'pdf'): # 判断有没有 pdf,即是不是连续分布
axes[0].plot(x, X.pdf(x), label="PDF")
axes[0].fill_between(x, X.pdf(x), alpha=0.5) # alpha 是透明度, alpha=0 表示 100% 透明, alpha=100 表示完全不透明
else: # 离散分布
x_int = np.unique(x.astype(int))
axes[0].bar(x_int, X.pmf(x_int), label="PMF") # pmf 和 pdf 是类似的
axes[1].plot(x, X.cdf(x), label="CDF")
for ax in axes:
ax.legend()
plt.show()
return axes
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
# 定义 scale = 1 / lambda
X = expon(scale=1)
# 指数分布
plot_distribution(X, axes=axes)

3.6 拉普拉斯分布(Laplace Distribution)
3.6.1 定义

这也是可以在⼀个点获得⽐较⾼的概率的分布。
3.6.2 代码实现:拉普拉斯分布
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import laplace
def plot_distribution(X, axes=None):
""" 给定随机变量,绘制 PDF, PMF, CDF"""
if axes is None:
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
x_min, x_max = X.interval(0.99)
x = np.linspace(x_min, x_max, 1000)
if hasattr(X.dist, 'pdf'): # 判断有没有 pdf,即是不是连续分布
axes[0].plot(x, X.pdf(x), label="PDF")
axes[0].fill_between(x, X.pdf(x), alpha=0.5) # alpha 是透明度, alpha=0 表示 100% 透明, alpha=100 表示完全不透明
else: # 离散分布
x_int = np.unique(x.astype(int))
axes[0].bar(x_int, X.pmf(x_int), label="PMF") # pmf 和 pdf 是类似的
axes[1].plot(x, X.cdf(x), label="CDF")
for ax in axes:
ax.legend()
plt.show()
return axes
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
mu, gamma = 0, 1
X = laplace(loc=mu, scale=gamma)
plot_distribution(X, axes=axes)
3.5 Dirac 分布

4 常用函数的有用性质
4.1 logistic sigmoid 函数

logistic sigmoid函数通常⽤来产⽣伯努利分布中的参数ϕ,因为它的范围是(0;1),处在ϕ的有效取值范围内。
sigmoid函数在变量取绝对值⾮常⼤的正值或负值时会出现饱和现象,意味着函数会变得很平,并且对输⼊的微⼩改变会变得不敏感。
4.2 softplus 函数

softplus函数可以⽤来产⽣正态分布的β和σ参数,因为它的范围是(0,∞)。当处理包含sigmoid函数的表达式时它也经常出现。
softplus函数名来源于它是另外⼀个函数的平滑(或软化)形式,这个函数是:

4.3 代码实现: logistic sigmoid函数 + softplus函数
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 100)
sigmoid = 1/(1 + np.exp(-x))
softplus = np.log(1 + np.exp(x))
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
axes[0].plot(x, sigmoid, label='sigmoid')
axes[1].plot(x, softplus, label='softplus')
for ax in axes:
ax.legend()
plt.show()