Text to image论文精读CogView: Mastering Text-to-Image Generation via Transformers(通过Transformer控制文本生成图像)
目录
- 一、原文摘要
- 二、为什么提出CogView
- 2.1 文本生成图像的任务难度
- 2.2 现有模型的不足
- 三、模型结构
- 3.1 框架结构
- 3.2 理论推导
- 3.3 第一阶段:Tokenization
- 3.3.1 文本的tokenizer
- 3.3.2 图像的tokenizer
- 3.4 第二阶段:Auto-regressive Transformer
- 四、训练过程的维稳
- 4.1 Precision Bottleneck Relaxation (PB-Relax)
- 4.2 Sandwich LayerNorm (Sandwich-LN)
- 4.3 维稳结果
- 五、微调:Finetuning
- 六、实验
- 6.1 客观评估
- 6.2 主观评估
- 6.3 实验复现
- 七、存在的问题
- 扩展
CogView是清华大学和阿里巴巴达摩院共同研究开发的一款用Transformer来控制文本生成图像的模型。该论文已被NIPS(Conference and Workshop on Neural Information Processing Systems,计算机人工智能领域A类会议)录用,文章发表于2021年10月。
论文地址:https://arxiv.org/pdf/2105.13290v3.pdf
代码地址:https://github.com/THUDM/CogView
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
文本到图像的生成在一般领域一直是一个开放的问题,这需要一个强大的生成模型和跨模态的理解。我们提出了CogView,一个带有VQ-VAE标记器的40亿参数变压器来解决这个问题。我们还展示了各种下游任务的微调策略,例如风格学习、超分辨率、文本图像排名和时装设计,以及稳定预训练的方法,例如消除NaN损失。CogView在模糊的MS COCO数据集上实现了最先进的FID,优于之前基于GAN的模型和最近的类似工作DALL-E。
二、为什么提出CogView
2.1 文本生成图像的任务难度
目前的各种文本生成图像任务,我们期望模型具有
(1)从像素中分离形状、颜色、手势和其他特征;
(2)理解输入文本;
(3)将物体和特征与对应的单词及其同义词对齐;
(4)学习复杂的分布,以生成不同物体和特征的重叠和组合。
显然这些要求已经超出了基本的视觉功能,模型需要拥有更高水平的认知能力。
2.2 现有模型的不足
(1)基于GAN的模型可以在简单和特定领域的数据集中进行合理的合成,但在复杂场景中其效果远不如人意。
(2)基于Transformer的GPT模型虽然在自然语言生成和语言理解方面取得很大进展,但是无法承受图像生成的计算量(即使是最大的ImageGPT也仅仅达到96*96分辨率)
(3)VQ-VAE(Vector Quantized Variational AutoEncoders)框架训练一个编码器将图像压缩到一个低维离散潜在空间重振了 CV中的自回归模型,但是未曾在文本生成图像领域有所应用。
CogView就是使用VQ-VAE对文本(中文)和图像进行大规模生成性联合预训练,并通过提出的 Precision Bottleneck Relaxation 和 Sandwich Layernorm 解决大规模的文本到图像生成预训练中的不稳定问题,实现文本生成图像的任务的模型。
三、模型结构
3.1 框架结构
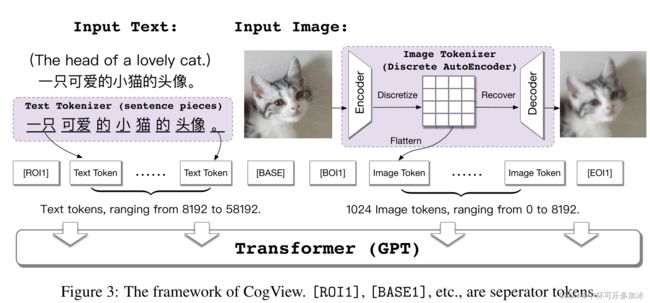
CogView整体思路为:
- 首先将文本部分转换成token,利用的是已经比较成熟的SentencePiece模型;
- 然后将图像部分通过一个离散化的AE(Auto-Encoder)转换为token
- 文本token和图像token拼接到一起,之后输入到GPT模型中学习生成图像。
- 训练后,在处理文本图像生成类任务时,模型会通过计算一个Caption Score对生成图像进行排序,从而选择与文本最为匹配的图像作为结果。
3.2 理论推导
模型对数似然和置信下界(ELBO)为:
log p ( X , T ; θ , ψ ) = ∑ i = 1 N log p ( t i ; θ ) + ∑ i = 1 N log p ( x i ∣ t i ; θ , ψ ) ≥ − ∑ i = 1 N ( − log p ( t i ; θ ) ⏟ NLL loss for text + E z i ∼ q ( z ∣ x i ; ϕ ) [ − log p ( x i ∣ z i ; ψ ) ] ⏟ reconstruction loss + KL ( q ( z ∣ x i ; ϕ ) ∥ p ( z ∣ t i ; θ ) ) ⏟ KL between q and (text conditional) prior ) . \begin{array}{l} \log p(\mathbf{X}, \mathbf{T} ; \theta, \psi)=\sum_{i=1}^{N} \log p\left(t_{i} ; \theta\right)+\sum_{i=1}^{N} \log p\left(x_{i} \mid t_{i} ; \theta, \psi\right) \\ \geq-\sum_{i=1}^{N}(\underbrace{-\log p\left(t_{i} ; \theta\right)}_{\text {NLL loss for text }}+\underbrace{\underset{z_{i} \sim q\left(\mathbf{z} \mid x_{i} ; \phi\right)}{\mathbb{E}}\left[-\log p\left(x_{i} \mid z_{i} ; \psi\right)\right]}_{\text {reconstruction loss }}+\underbrace{\operatorname{KL}\left(q\left(\mathbf{z} \mid x_{i} ; \phi\right) \| p\left(\mathbf{z} \mid t_{i} ; \theta\right)\right)}_{\text {KL between } q \text { and (text conditional) prior }}) . \end{array} logp(X,T;θ,ψ)=∑i=1Nlogp(ti;θ)+∑i=1Nlogp(xi∣ti;θ,ψ)≥−∑i=1N(NLL loss for text −logp(ti;θ)+reconstruction loss zi∼q(z∣xi;ϕ)E[−logp(xi∣zi;ψ)]+KL between q and (text conditional) prior KL(q(z∣xi;ϕ)∥p(z∣ti;θ))).
或者可以写为:
log p ( X , T ; θ , ψ ) = ∑ i = 1 N log p ( t i ; θ ) + ∑ i = 1 N log p ( x i ∣ t i ; θ , ψ ) ≥ − ∑ i = 1 N ( E z i ∼ q ( z ∣ x i ; ϕ ) [ − log p ( x i ∣ z i ; ψ ) ] ⏟ reconstruction loss − log p ( t i ; θ ) ⏟ NLL loss for text − log p ( z i ∣ t i ; θ ) ⏟ NLL loss for z ) . \begin{array}{l} \log p(\mathbf{X}, \mathbf{T} ; \theta, \psi)=\sum_{i=1}^{N} \log p\left(t_{i} ; \theta\right)+\sum_{i=1}^{N} \log p\left(x_{i} \mid t_{i} ; \theta, \psi\right) \\\end{array} \geq-\sum_{i=1}^{N}(\underbrace{\underset{z_{i} \sim q\left(\mathbf{z} \mid x_{i} ; \phi\right)}{\mathbb{E}}\left[-\log p\left(x_{i} \mid z_{i} ; \psi\right)\right]}_{\text {reconstruction loss }} \underbrace{-\log p\left(t_{i} ; \theta\right)}_{\text {NLL loss for text }} \underbrace{-\log p\left(z_{i} \mid t_{i} ; \theta\right)}_{\text {NLL loss for z }}) . logp(X,T;θ,ψ)=∑i=1Nlogp(ti;θ)+∑i=1Nlogp(xi∣ti;θ,ψ)≥−∑i=1N(reconstruction loss zi∼q(z∣xi;ϕ)E[−logp(xi∣zi;ψ)]NLL loss for text −logp(ti;θ)NLL loss for z −logp(zi∣ti;θ)).
符号解释:
- ( X , T ) = { x i , t i } i = 1 N {(\mathbf{X}, \mathbf{T})=\left\{x_{i}, t_{i}\right\}_{i=1}^{N}} (X,T)={xi,ti}i=1N为数据集,其由N对独立同分布的图像变量x及其描述文本变量t的样本组成;
- 假设图像x可以通过涉及潜在变量z生成:首先由先验P(t;θ)生成 t i t_i ti,由 P ( z ∣ t = t i ; θ ) P(z|t=t_i ;θ) P(z∣t=ti;θ)生成 z i z_i zi,由 P ( x ∣ z = z i ; ψ ) P(x|z=z_i;ψ) P(x∣z=zi;ψ)生成 x i x_i xi;
- ϕ为编码器,ψ为解码器 ;
- q ( z ∣ x i ; φ ) q(z|x_i;φ) q(z∣xi;φ)是编码器ϕ的输出,为变分分布;
学习过程:
- 学习编码器ϕ 和解码器ψ 最小化重构损失(reconstruction loss);
- GPT通过学习token化的文本 t i t_i ti和 z i z_i zi序列最小化两个负对数似然损失(NLL loss for text 和NLL loss for z)
理论推导看不懂暂时也没关系。总之要知道:整个模型分成两个阶段
第一个阶段在做Tokenization(文本的tokenizer已经成熟,忽视他的重构损失,而图像的tokenizer是一个离散化的自编码器,其重构损失reconstruction loss为整体损失函数的第一个部分)
第二个阶段是一个transformer,用的是目前最强大的GPT模型,其输入为第一阶段文本和图像的Tokenization序列,其目的是最小化另一个损失(NLL loss)
3.3 第一阶段:Tokenization
3.3.1 文本的tokenizer
关于文本的tokenizer已经有很好地研究,在CogView中,使用的是SentencePiece,基础是一个大型中文语料库。
3.3.2 图像的tokenizer
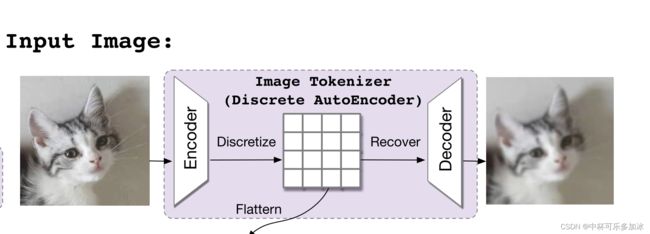
图像的tokenizer是离散化的自编码器,类似VQ-VAE。
编码器 ϕ 将维度为 H×W×3 的图像x映射到一个维度为 h×w×d 的Encoder中Enc(x)中,然后将每个d维向量量化为codebook { v 0 , … , v ∣ V ∣ − 1 } , ∀ v k ∈ R d \left\{v_{0}, \ldots, v_{|V|-1}\right\}, \forall v_{k} \in \mathbb{R}^{d} {v0,…,v∣V∣−1},∀vk∈Rd,量化的结构可以由h×w的嵌入索引来表示,最终编码器编码成 z ∈ { 0 , … , ∣ V ∣ − 1 } h × w \mathbf{z} \in\{0, \ldots,|V|-1\}^{h \times w} z∈{0,…,∣V∣−1}h×w。解码器ψ 将量化向量映射回(模糊的)图像以重建输入。
文章在分析了四种图像的tokenizer方法后,选择了由VQ-VAE思想转化来的最近邻映射的直通估计器,这种方法的一个问题就是当codebook太大时,会出现维数灾难,不过本文未碰见这种情况。
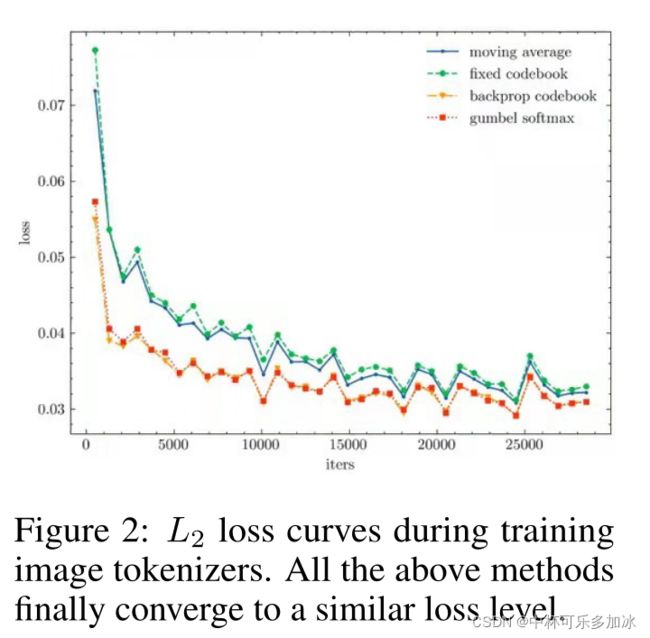
(四种图像的tokenizer方法均能收敛到相似的水平)
3.4 第二阶段:Auto-regressive Transformer
CogView的主网络是单向Transformer(GPT)。Transformer有48层,隐藏的大小为2560,40个注意力头和40亿个参数。

如图所示,在每个序列中添加四个分隔符标识,指示文本和图像的边界。
- [RO|1] :标识对应文本的开头
- [BASE]:标识对应文本的结束
- [BO|1]:标识图像的开头
- [EO|1]:标识图像的结束
预训练的pretext任务是从左到右预测字符,也称语言建模,在本模型中,文本和图像都以同样方式训练预测,在实验中,本文发现文本建模是文本到图像预训练成功的关键所在,如果文本标记的权重设置为零,模型将无法找到文本和图像之间的连接,并生成与输入文本完全无关的图像。
本文假设文本建模将知识抽象在隐藏层中,并在之后有效利用这些知识进行图像建模。
四、训练过程的维稳
在16位精度下,text-to-image任务预训练会非常不稳定,保持训练的稳定是CogView最具有挑战的部分。在分析模型训练后,发现有两种不稳定性:溢出(NAN loss)和下溢(loss 不收敛),因此提出以下维稳技术:
4.1 Precision Bottleneck Relaxation (PB-Relax)
在分析了训练的动态性之后,作者发现溢出(NAN loss)总是发生在两个瓶颈操作上,即最后一层LayerNorm或注意层。
- 在深层网络中,LayerNorm中输出的值可能会爆炸到10000+,导致溢出。解决的方法是令LayerNorm(x)=LayerNorm(x/max(x)),即通过除以x的最大值来减小爆炸。
- 注意力分数 Q T K / d Q^{T} K / \sqrt{d} QTK/d可能明显大于输入元素,故将计算顺序改为 Q T ( K / d ) Q^{T}( K / \sqrt{d}) QT(K/d),又由于 softmax ( Q T K / d ) = softmax ( Q T K / d − constant ) \operatorname{softmax}\left(Q^{T} K / \sqrt{d}\right)=\operatorname{softmax}\left(Q^{T} K / \sqrt{d}-\text { constant }\right) softmax(QTK/d)=softmax(QTK/d− constant ),故将注意力变更为: softmax ( Q T K d ) = softmax ( ( Q T α d K ) − max ( Q T α d K ) × α ) \operatorname{softmax}\left(\frac{Q^{T} K}{\sqrt{d}}\right)=\operatorname{softmax}\left(\left(\frac{Q^{T}}{\alpha \sqrt{d}} K\right)-\max \left(\frac{Q^{T}}{\alpha \sqrt{d}} K\right) \times \alpha\right) softmax(dQTK)=softmax((αdQTK)−max(αdQTK)×α)。如此,注意力分数被除以α来防止溢出。
4.2 Sandwich LayerNorm (Sandwich-LN)
Transformer中的 LayerNorm对于稳定训练至关重要。LayerNorm的输出为 ( x − x ~ ) d ∑ i ( x i − x ~ ) 2 γ + β \frac{(x-\tilde{x}) \sqrt{d}}{\sqrt{\sum_{i}\left(x_{i}-\tilde{x}\right)^{2}}} \gamma+\beta ∑i(xi−x~)2(x−x~)dγ+β,基本上与x的隐藏维度大小的平方根成比例,但有些维的输入值明显大于其他维,会导致对应维的输出值加大,在残差分支中,这些较大的值被放大并放回到主支中,加剧transformer层的现象,最后导致深层的value explosion。
因此,提出了Sandwich LayerNorm,**其在每个残差分支结束时添加一个新的LayerNorm。**该残差分支确保了每层的输入值的比例在一个合理范围内,帮助模型更好的收敛。
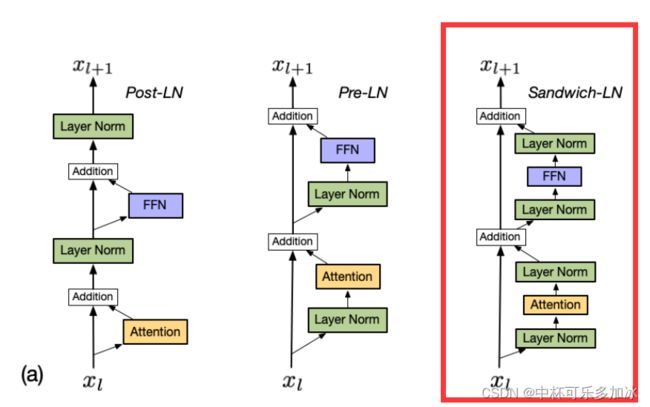
(Post-LN是原始transformert中的结构,Pre-LN是目前最流行的结构,Sandwich-LN是本文提出的结构)
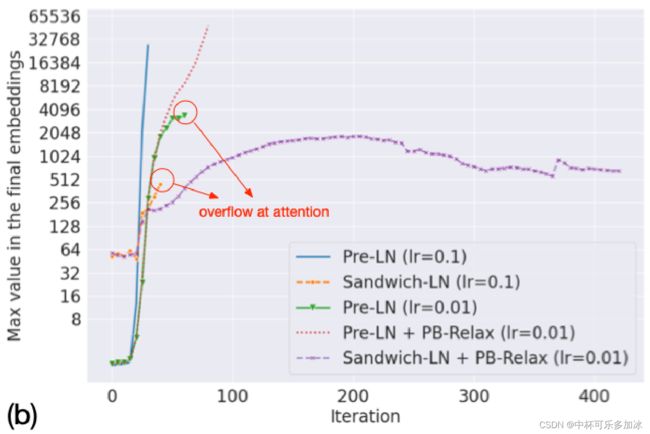
4.3 维稳结果
如图所示,PB-relax 和 Sandwich-LN的方案能够有效稳定训练过程,能促使模型收敛。
五、微调:Finetuning
通过微调,本模型还可以用于:
超分辨率重建:

图像标题生成:
风格学习:

工业服装设计:

六、实验
6.1 客观评估
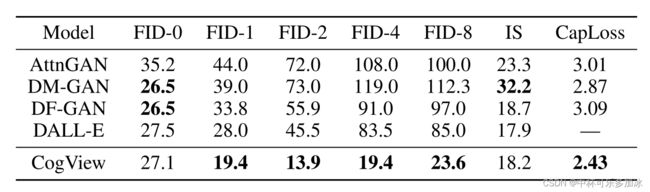
FID和IS旨在测量从相对简单的分布评价(通常是单个对象)无条件生成的质量。然而,文本到图像的生成应该成对地进行评估。Caption Loss是一个绝对分数,它可以在所有样本中取平均,对于这项任务来说,它是一个更好的衡量标准,并且更符合人类评估的总体分数。
6.2 主观评估
在文本到图像生成方面,人工评估比机器评估更有说服力,实验包括2950组由AttnGAN、DM-GAN、DF-GAN、CogView生成的图像与真实图像之间的比较。

结果显示,在总分、图像清晰度、纹理质量、与文本的相关度上,CogView均取得了仅次于真实图像的好成绩。
甚至在清晰度上,通过超分辨率优化后,甚至优于真实图像的水平。
6.3 实验复现
有计划复现。
七、存在的问题
局限性:CogView的一个缺点是生成速度慢,这在自回归模型中很常见,因为每个图像都是逐标记生成的。VQ-VAE带来的模糊性也是一个重要限制。
伦理问题 :与Deepfake类似,CogView易于被恶意使用,因为其可控且生成图像的能力强。另外存在生成图像公平性的问题(比如生成人的性别、肤色等等),在文章中另外提出了一种“word replacing”方法来解决这个问题。
扩展
知乎:对数损失函数是如何度量损失的?
深入浅出 通俗白话理解Transformer及其pytorch源码(零基础理解为什么是Transformer?什么是Transformer?)