python 基金绩效归因
python 基金绩效归因
1 前言
随着社会经济的发展和投资意识的不断增强,人们已经不满足于银行存款和余额宝等低收益率的理财产品,开始将目光聚焦到基金上。
绩效评估可以分为三个部分,分别为择股、择时和交互作用。从最基本的使用定量指标刻画组合表现的绩效衡量到深层次的组合超额收益分解的绩效归因,最终形成成熟的绩效评价,对组合或基金的超额收益的可持续性进行评价。绩效归因有因子分析及回归拟合两类方法,本文介绍了几种简单的因子分析方法,对于策略尤其是基金的评价方面具有实践意义(回归拟合法以后有空再写)。
2 模型介绍
2.1 CAPM模型
CAPM,全称 Capital Asset Pricing Model,译为资本资产定价模型,是由 Treynor, Sharpe, Lintner, Mossin 几人分别提出。搭建于 Markowitz 的现代资产配置理论(MPT)之上,该模型用简单的数学公式表述了资产组合收益率与无风险利率以及市场组合收益率之间的关系。在这个公式中,任何风险资产组合的超额收益都可以被分为两个部分:非市场收益α和市场风险敞口收益β。
r s r_s rs - r f r_f rf = α + β( r m r_m rm - r f r_f rf) + ϵ
其中, r s r_s rs 表示投资组合收益率; r f r_f rf 表示无风险利率; r m r_m rm 表示市场组合收益率;α表示个股选择带来的超额收益,这部分收益无法由市场风险解释;β表示组合在市场中暴露的风险敞口。
因此,当α显著大于0时,说明该基金管理人具有正向的择股能力。当β>1时,说明资产组合的风险波动比市场组合大;当0<β<1时,说明资产组合的风险波动比市场组合小。
2.2 T-M模型
T-M,全称Treynor - Mazuy Model,是由Treynor和Mazuy于1966年共同提出。该模型在CAPM模型的基础上增加了市场超额收益的二阶项。
r s r_s rs - r f r_f rf = α + β 1 β_1 β1( r m r_m rm - r f r_f rf) + β 2 β_2 β2( r m r_m rm - r f r_f rf) 2 ^2 2+ ϵ
当α显著大于0时,说明该基金管理人具有正向的择股能力。当 β 2 β_2 β2显著大于0时,说明该基金管理人具有正向的择时能力。
2.3 H-M模型
H-M,全称Henriksson - Merton Model,是由Henriksson和Merton于1981年共同提出。该模型在T-M模型的基础上进行改进。
r s r_s rs - r f r_f rf = α + β 1 β_1 β1( r m r_m rm - r f r_f rf) + β 2 β_2 β2( r m r_m rm - r f r_f rf) I r m > r f I_{r_m>r_f} Irm>rf+ ϵ
其中:
I r m > r f = { 1 , 当 r m > r f 0 , 其 它 I_{r_m>r_f} = \begin{cases} 1, 当r_m>r_f\\ 0, 其它 \end{cases} Irm>rf={1,当rm>rf0,其它
当α显著大于0时,说明该基金管理人具有正向的择股能力。当 β 2 β_2 β2显著大于0时,说明该基金管理人具有正向的择时能力。
2.4 C-L模型
C-L,全称Chang - Lewellen Model,是由Chang和Lewellen于1984年共同提出。该模型与H-M模型对择时能力的定义一致。
r s r_s rs - r f r_f rf = α + β 1 β_1 β1( r m r_m rm - r f r_f rf) I r m < r f I_{r_m
当α显著大于0时,说明该基金管理人具有正向的择股能力。当 β 2 β_2 β2> β 1 β_1 β1时,说明该基金管理人具有正向的择时能力。
3 实证分析
3.1 数据说明
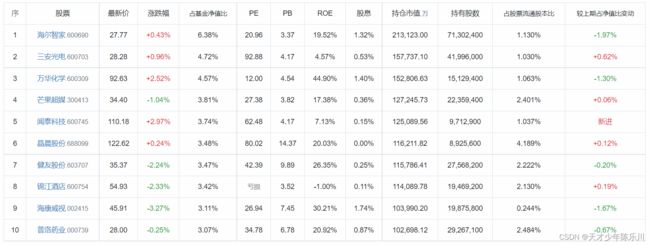
本文以兴全合润混合(LOF)基金(163406)为例,样本期为2019年12月1日到2020年2月29日共58个交易日。市场组合收益率为沪深300指数日收益率,无风险利率为国债指数日收益率,持有股票为下图所示的十只股票,仓位根据这十只股票占基金净值比按比例分配。数据来源于tushare数据库,官网链接:https://tushare.pro。
3.2 结果
| 模型名称 | α | β 1 β_1 β1 | β 2 β_2 β2 | R 2 R^2 R2 |
|---|---|---|---|---|
| CAPM | 0.3173** | 1.2452*** | 0.775 | |
| T - M | 0.3448** | 1.2009*** | -0.0109 | 0.776 |
| H - M | 0.4145** | 1.3032*** | -0.2076 | 0.778 |
| C - L | 0.4145** | 1.3032*** | 1.0957*** | 0.778 |
注: ∗ ∗ ∗ *** ∗∗∗、 ∗ ∗ ** ∗∗、 ∗ * ∗分别表示相应变量在 1%、5% 和 10% 水平下显著。
从上表可以看出,无论是什么模型,该基金管理人在样本期内具有正向的择股能力。在C - L模型中, β 2 β_2 β2小于 β 1 β_1 β1 ,且系数显著,说明该基金管理人在样本期内具有负向的择时能力。
4 总结
T-M模型、H-M模型以及C-L模型都是基于CAPM改良而来,采取的线性回归方法,其本质是将基金与市场基准比较,量化基金的选股及择时能力,缺点是分析维度较为单一,归因结果不够细致,对于基准的选择有较强依赖性。此外,本文所选基金持仓数据为2021年第四季度公布的信息,所选样本期为2019年12月1日至2020年2月29日,得到的结果并不能说明该基金经理水平较低。本文仅供交流学习参考,不构成任何投资建议。炒股有风险,投资需谨慎。
完整代码
import tushare as ts
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
pro = ts.pro_api('你的token')
data = pd.DataFrame()
df1 = pro.index_daily(ts_code='399300.SZ', start_date='20191201', end_date='20200229')
df2 = pro.index_daily(ts_code='000012.SH', start_date='20191201', end_date='20200229')
df3 = pro.daily(ts_code='600690.SH', start_date='20191201', end_date='20200229')
df4 = pro.daily(ts_code='600703.SH', start_date='20191201', end_date='20200229')
df5 = pro.daily(ts_code='600309.SH', start_date='20191201', end_date='20200229')
df6 = pro.daily(ts_code='300413.SZ', start_date='20191201', end_date='20200229')
df7 = pro.daily(ts_code='600745.SH', start_date='20191201', end_date='20200229')
df8 = pro.daily(ts_code='688099.SH', start_date='20191201', end_date='20200229')
df9 = pro.daily(ts_code='603707.SH', start_date='20191201', end_date='20200229')
df10 = pro.daily(ts_code='600754.SH', start_date='20191201', end_date='20200229')
df11 = pro.daily(ts_code='002415.SZ', start_date='20191201', end_date='20200229')
df12 = pro.daily(ts_code='000739.SZ', start_date='20191201', end_date='20200229')
#600745.SH这只股票在样本期内有停牌
tt = df7['trade_date'].tolist()
dff3 = pd.DataFrame([[0 for x in range(11)]],columns=df3.columns.values)
for i in range(len(df3)):
if df3.iloc[i,1] not in tt:
dff1 = df7.loc[:i]
dff2 = df7.loc[i+1:]
df7 = dff1.append(dff3, ignore_index = True).append(dff2, ignore_index = True)
hr_rate = df3['pct_chg'].tolist()
sa_rate = df4['pct_chg'].tolist()
wh_rate = df5['pct_chg'].tolist()
mg_rate = df6['pct_chg'].tolist()
wt_rate = df7['pct_chg'].tolist()
jc_rate = df8['pct_chg'].tolist()
jy_rate = df9['pct_chg'].tolist()
jj_rate = df10['pct_chg'].tolist()
hk_rate = df11['pct_chg'].tolist()
pl_rate = df12['pct_chg'].tolist()
fenmu = 6.38+4.72+4.57+3.81+3.74+3.48+3.47+3.42+3.11+3.07
rs = np.array(hr_rate)*6.38/fenmu+np.array(sa_rate)*4.72/fenmu+np.array(wh_rate)*4.57/fenmu+\
np.array(mg_rate)*3.81/fenmu+np.array(wt_rate)*3.74/fenmu+np.array(jc_rate)*3.48/fenmu+\
np.array(jy_rate)*3.47/fenmu+np.array(jj_rate)*3.42/fenmu+np.array(hk_rate)*3.11/fenmu+\
np.array(pl_rate)*3.07/fenmu
data['time'] = df1['trade_date'].tolist()
data['rm'] = df1['pct_chg'].tolist() #市场基准收益率
data['rf'] = df2['pct_chg'].tolist() #无风险利率
data['rs'] = rs #投资组合收益率
data.to_excel('数据1.xlsx',index=False)
df = pd.read_excel('数据1.xlsx',engine='openpyxl',sheet_name='Sheet1')
data=pd.DataFrame()
rm = df['rm'].tolist()
rf = df['rf'].tolist()
rs = df['rs'].tolist()
y = np.array(rs)-np.array(rf)
x1 = np.array(rm)-np.array(rf)
x2 = [a**2 for a in x1]
I1 = []
for i in range(len(rm)):
if rm[i] > rf[i]:
I1.append(1)
else:
I1.append(0)
x3 = np.multiply(np.array(x1),np.array(I1))
I2 = []
for i in range(len(rm)):
if rm[i] < rf[i]:
I2.append(1)
else:
I2.append(0)
x4 = np.multiply(np.array(x1),np.array(I2))
data['y'] = y
data['x1'] = x1
data['x2'] = x2
data['x3'] = x3
data['x4'] = x4
est1 = smf.ols(formula='y ~ x1', data=data).fit() #CAPM
print(est1.summary())
est2 = smf.ols(formula='y ~ x1+x2', data=data).fit() #TM
print(est2.summary())
est3 = smf.ols(formula='y ~ x1+x3', data=data).fit() #HM
print(est3.summary())
est4 = smf.ols(formula='y ~ x4+x3', data=data).fit() #CL
print(est4.summary())