动手学深度学习(MXNet)5:计算机视觉
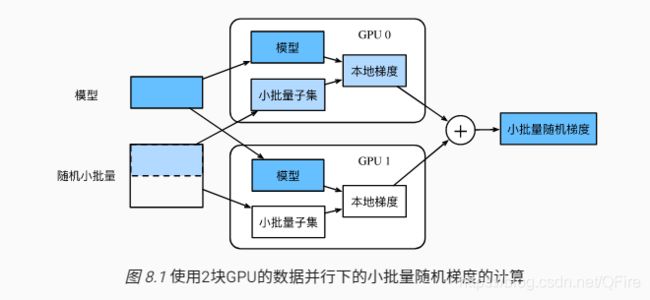
多GPU计算,需要考虑同步数据
图像增广
对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
%matplotlib inline
import d2lzh as d2l
import mxnet as mx
from mxnet import autograd, gluon, image, init, nd
from mxnet.gluon import data as gdata, loss as gloss, utils as gutils
import sys
import time常用的图像增广方法,实验样例
d2l.set_figsize()
img = image.imread('../img/cat1.jpg')
d2l.plt.imshow(img.asnumpy())
def show_images(imgs, num_rows, num_cols, scale=2):
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
for i in range(num_rows):
for j in range(num_cols):
axes[i][j].imshow(imgs[i * num_cols + j].asnumpy())
axes[i][j].axes.get_xaxis().set_visible(False)
axes[i][j].axes.get_yaxis().set_visible(False)
return axes
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
show_images(Y, num_rows, num_cols, scale)翻转和裁剪
apply(img, gdata.vision.transforms.RandomFlipLeftRight())
apply(img, gdata.vision.transforms.RandomFlipTopBottom())shape_aug = gdata.vision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)
通过对图像随机裁剪来让物体以不同的比例出现在图像的不同位置,这同样能够降低模型对目标位置的敏感性。
颜色变化,从4个方面改变图像的颜色:亮度、对比度、饱和度和色调。
apply(img, gdata.vision.transforms.RandomBrightness(0.5)) # 亮度
apply(img, gdata.vision.transforms.RandomHue(0.5)) # 色调
color_aug = gdata.vision.transforms.RandomColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)叠加多个图像增广方法
augs = gdata.vision.transforms.Compose([
gdata.vision.transforms.RandomFlipLeftRight(), color_aug, shape_aug])
apply(img, augs)微调(fine tuning)
迁移学习中的一种常用技术:微调由以下4步构成。
- 在源数据上预训练一个网络,即源模型
- 创建一个新的模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集上训练目标模型。
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
目标检测和边界框
很多时候图像里有多个我们感兴趣的目标,我们不仅想知道他们的类别,还想得到他们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。
边界框(bounding box)来描述目标位置。一个矩形框
锚框(anchor box)
目标检测通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框。不同的模型使用的区域采样方法可能不同。
这里我们介绍一种方法:以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框。
如何衡量锚框和真实边界框之间的相似度。我们知道,Jaccard系数可以衡量两个集合的相似度。
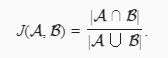
可以把边界框内的像素区域看成是像素的集合。这个Jaccard系统称为交并比(intersection over union, IoU)。

需要为每个锚框标注两类标签:一是类别;二是偏移量。在目标检测时,首先生成多个锚框,然后预测类别和偏移量。接着根据偏移量调整锚框位置从而得到预测边界框,最后筛选需要输出的预测边界框。
如何从多个锚框中分配出与其相似的真实边界框?
同一个目标可能会输出多个相似的预测边界框,如何输出最相似的预测边界框。非极大值抑制(non-maximum suppression, NMS)。
- 以每个像素为中心,生成多个大小和宽高比不同的锚框。
- 交并比是两个边界框相交面积与相并面积之比。
- 在训练集中,为每个锚框标注两类标签:一是锚框所含目标的类别;二是真实边界框相对锚框的偏移量。
- 预测时,可以使用非极大值抑制来移除相似的预测边界框,从而令结果简洁。
多尺度目标检测
如果每个像素生成5个不同形状的锚框,那么561x728的图像需要预测200多万个锚框。

既然我们已在多个尺度上生成了不同大小的锚框,相应地,我们需要在不同尺度上检测不同大小的目标。
基于CNN的方法,在某个尺度下,假设我们依据ci张形状为h×w的特征图生成h×w组不同中心的锚框,且每组的锚框个数为a。例如,在刚才实验的第一个尺度下,我们依据10(通道数)张形状为4×4的特征图生成了16组不同中心的锚框,且每组含3个锚框。 接下来,依据真实边界框的类别和位置,每个锚框将被标注类别和偏移量。在当前的尺度下,目标检测模型需要根据输入图像预测h×w组不同中心的锚框的类别和偏移量。
因此,我们可以将特征图在相同空间位置的ci个单元变换为以该位置为中心生成的a个锚框的类别和偏移量。 不难发现,本质上,我们用输入图像在某个感受野区域内的信息来预测输入图像上与该区域位置相近的锚框的类别和偏移量。
- 可以在多个尺度下生成不同数量和不同大小的锚框,从而在多个尺度下检测不同大小的目标。
- 特征图的形状能确定任一图像上均匀采样的锚框中心。
- 用输入图像在某个感受野区域内的信息来预测输入图像上与该区域相近的锚框的类别和偏移量。
目标检测数据集(皮卡丘)
MXNet提供的im2rec工具将图像转换成二进制的RecordIO格式。该格式既可以降低数据集在磁盘上的存储开销,又能提高读取效率。

单发多框检测(SSD)
主要由一个基础网络块和若干个多尺度特征块串联而成。其中基础网络块用来从原始图像中抽取特征。
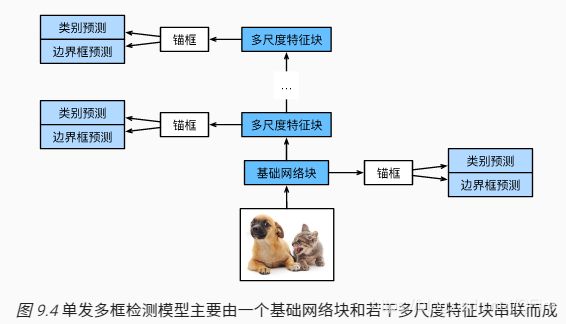
类别预测层:设目标的类别个数为q。每个锚框的类别个数将是q+1,其中类别0表示锚框只包含背景。在某个尺度下,设特征图的高和宽分别为h和w,如果以其中每个单元为中心生成a个锚框,那么我们需要对hwa个锚框进行分类。如果使用全连接层作为输出,很容易导致模型参数过多。
- 单发多框检测是一个多尺度的目标检测模型。该模型基于基础网络块和各个多尺度特征块生成不同数量和不同大小的锚框,并通过预测锚框的类别和偏移量检测不同大小的目标。
- 单发多框检测在训练中根据类别和偏移量的预测和标注值计算损失函数。
区域卷积神经网络(R-CNN)系列
(region-based CNN)的改进方法:快速的R-CNN(Fast R-CNN)、更快的(Faster R-CNN)以及掩码(Mask R-CNN)
R-CNN首先对图像选取若干提议区域(如锚框也是一种选取方法)并标注他们的类别和边界框。然后用CNN对提议区域提取特征。
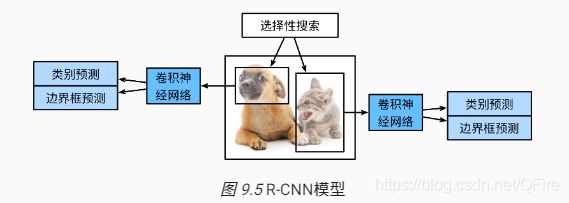
具体分以下4步:
- 对输入图像使用选择性搜索(selective search)来选取多个高质量的提议区域 [2]。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域将被标注类别和真实边界框。
- 选取一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向计算输出抽取的提议区域特征。
- 将每个提议区域的特征连同其标注的类别作为一个样本,训练多个支持向量机对目标分类。其中每个支持向量机用来判断样本是否属于某一个类别。
- 将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
R-CNN虽然通过预训练的CNN有效抽取了图像特征,但它的主要缺点是速度慢。想象一下,我们可能从一张图像中选出上千个提议区域,对该图像做目标检测将导致上千次的CNN前向计算。这个巨大的计算量令R-CNN难以在实际应用中被广泛采用。
Fast R-CNN:只对整个图像做CNN

Faster R-CNN:提出将选择性搜索替换区域提议网络,从而减少提议区域的生成数量,并保证目标检测的精度。

Mask R-CNN:如果训练数据还标注了每个目标在图像上的像素级位置,那么Mask R-CNN能有效利用这些详尽的标注信息进一步提升目标检测的精度。

语义分割和数据集
前面使用方形边界框来标注和预测图像中的目标。语义分割(semantic segmentation)问题,它关注如何将图像分割成属于不同语义类别的区域。可以看到,与目标检测相比,语义分割标注的像素级的边框显然更加精细。
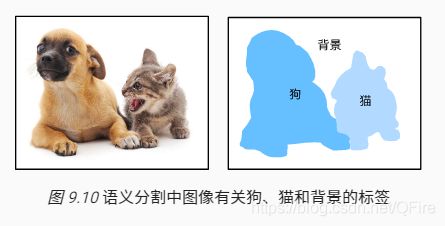
- 语义分割的一个重要数据集叫作Pascal VOC2012。
全卷积网络(FCN)
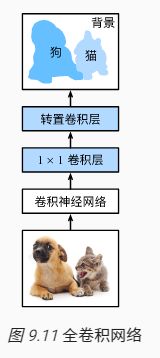
FCN实现了从图像像素到像素类别的变换。与前面介绍的CNN有所不同,FCN通过转置卷积层将中间层特征图的高和宽变换回输入图像的尺寸,从而令预测结果与输入图像在空间维上一一对应:给定空间维上的位置,通道维的输出即该位置对应像素的类别预测。
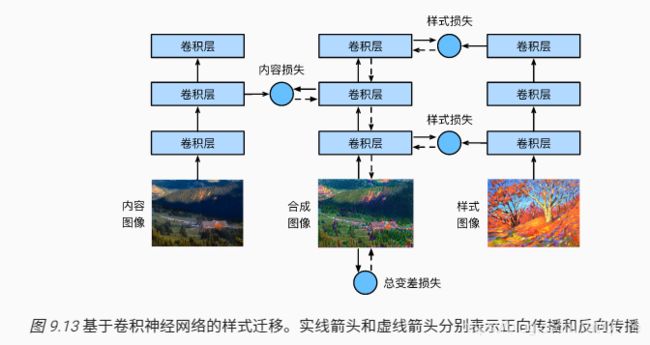
样式迁移