hugging face 官方文档——datasets、optimizer
文章目录
-
- 一、Load dataset
-
- 1.1 Hugging Face Hub
- 1.2 本地和远程文件
-
- 1.2.1 CSV
- 1.2.2 JSON
- 1.2.3 text
- 1.2.4 Parquet
- 1.2.5 内存数据(python字典和DataFrame)
- 1.2.6 Offline离线(见原文)
- 1.3 切片拆分(Slice splits)
-
- 1.3.1 字符串拆分(包括交叉验证)
- 1.4 Troubleshooting故障排除
-
- 1.4.1手动下载
- 1.4.2 Specify features指定功能
- 1.5 加载自定义或本地metric
-
- 1.5.2 Load configurations
- 1.6 分布式设置
- 二、Dataset数据处理
-
- 2.1 Sort, shuffle, select, split, and shard
-
- 2.1.1 sort
- 2.1.2 Shuffle(Dataset/DatasetDict可用)
- 2.1.3 Select 和 Filter(选择特定的行数据)
- 2.1.4 Split(划分测试验证集)
- 2.1.5 Shard分片
- 2.2 Rename, remove, cast, and flatten
-
- 2.2.1 Rename
- 2.2.2 Remove
- 2.2.3 Cast更改feature类型(还可以0/1和bool互换)
- 2.2.4 Flatten(嵌套feature拉平到同一层)
- 2.3 Map
-
- 2.3.2 多处理
- 2.3.3 批处理
- 2.3.4 Tokenization
- 2.3.5 Split long examples
- 2.3.6 数据增强
- 2.3.7 处理多个splits
- 2.3.8分布式使用
- 2.4 Concatenate连接
- 2.5 Format 格式
- 2.6 保存和导出
-
- 2.6.1 保存和加载dataset
- 2.6.2 Export导出
- 三、优化器
-
- 3.1 weight decay
-
- 3.1.2 weight decay 在 优化器中的实现:
- 3.2 关于学习率调度器:
-
- 3.2.1 trainer中设置学习率
- 3.2.2 get_scheduler具体参数
trainer参数设定参考: 《huggingface transformers使用指南之二——方便的trainer》
一、Load dataset
本节参考官方文档:Load
数据集存储在各种位置,比如 Hub 、本地计算机的磁盘上、Github 存储库中以及内存中的数据结构(如 Python 词典和 Pandas DataFrames)中。无论您的数据集存储在何处, Datasets 都为您提供了一种加载和使用它进行训练的方法。
本节将向您展示如何从以下位置加载数据集:
- 没有数据集加载脚本的 Hub
- 本地文件
- 内存数据
- 离线
- 拆分的特定切片
- 解决常见错误,以及如何加载指标的特定配置。
1.1 Hugging Face Hub
上传数据集到Hub数据集存储库。
- 使用datasets.load_dataset()加载Hub上的数据集。参数是存储库命名空间和数据集名称(epository mespace and dataset name)
from datasets import load_dataset
dataset = load_dataset('lhoestq/demo1')
- 根据revision加载指定版本数据集:(某些数据集可能有Git 标签、branches or commits多个版本)
dataset = load_dataset(
"lhoestq/custom_squad",
revision="main" # tag name, or branch name, or commit hash )
关如何在 Hub 上创建数据集存储库以及如何上传数据文件的更多说明,请参阅Add a community dataset 。
- 使用该data_files参数将数据文件映射到拆分,例如train,validation和test:(如果数据集没有数据集加载脚本,则默认情况下,所有数据都将在train拆分中加载。)
data_files = {"train": "train.csv", "test": "test.csv"}
dataset = load_dataset("namespace/your_dataset_name", data_files=data_files)
如果不指定使用哪些数据文件,load_dataset将返回所有数据文件。
- 使用data_files参数加载文件的特定子集:
from datasets import load_dataset
c4_subset = load_dataset('allenai/c4', data_files='en/c4-train.0000*-of-01024.json.gz')
- 使用split参数指定自定义拆分(见下一节)
1.2 本地和远程文件
本地或远程的数据集,存储类型为csv,json,txt或parquet文件都可以加载:
1.2.1 CSV
#多个 CSV 文件:
dataset = load_dataset('csv', data_files=['my_file_1.csv', 'my_file_2.csv', 'my_file_3.csv'])
#将训练和测试拆分映射到特定的 CSV 文件:
dataset = load_dataset('csv', data_files={'train': ['my_train_file_1.csv', 'my_train_file_2.csv'] 'test': 'my_test_file.csv'})
#要通过 HTTP 加载远程 CSV 文件,您可以传递 URL:
base_url = "https://huggingface.co/datasets/lhoestq/demo1/resolve/main/data/"
dataset = load_dataset('csv', data_files={'train': base_url + 'train.csv', 'test': base_url + 'test.csv'})
1.2.2 JSON
from datasets import load_dataset
dataset = load_dataset('json', data_files='my_file.json')
JSON 文件可以有多种格式,但我们认为最有效的格式是拥有多个 JSON 对象;每行代表一个单独的数据行。例如:
{"a": 1, "b": 2.0, "c": "foo", "d": false}
{"a": 4, "b": -5.5, "c": null, "d": true}
您可能会遇到的另一种 JSON 格式是嵌套字段,在这种情况下,您需要指定field参数,如下所示:
{"version": "0.1.0",
"data": [{"a": 1, "b": 2.0, "c": "foo", "d": false},
{"a": 4, "b": -5.5, "c": null, "d": true}]
}
from datasets import load_dataset
dataset = load_dataset('json', data_files='my_file.json', field='data')
要通过 HTTP 加载远程 JSON 文件,您可以传递 URL:
base_url = "https://rajpurkar.github.io/SQuAD-explorer/dataset/"
dataset = load_dataset('json', data_files={'train': base_url + 'train-v1.1.json', 'validation': base_url + 'dev-v1.1.json'}, field="data")
1.2.3 text
逐行读取文本文件来构建数据集:
from datasets import load_dataset
dataset = load_dataset('text', data_files={'train': ['my_text_1.txt', 'my_text_2.txt'], 'test': 'my_test_file.txt'})
要通过 HTTP 加载远程 TXT 文件,您可以传递 URL:
dataset = load_dataset('text', data_files='https://huggingface.co/datasets/lhoestq/test/resolve/main/some_text.txt')
1.2.4 Parquet
与基于行的文件(如 CSV)不同,Parquet 文件以柱状格式存储。大型数据集可以存储在 Parquet 文件中,因为它更高效,返回查询的速度更快。
#加载 Parquet 文件,如下例所示:
from datasets import load_dataset
dataset = load_dataset("parquet", data_files={'train': 'train.parquet', 'test': 'test.parquet'})
要通过 HTTP 加载远程镶木地板文件,您可以传递 URL:
base_url = "https://storage.googleapis.com/huggingface-nlp/cache/datasets/wikipedia/20200501.en/1.0.0/"
data_files = {"train": base_url + "wikipedia-train.parquet"}
wiki = load_dataset("parquet", data_files=data_files, split="train")
1.2.5 内存数据(python字典和DataFrame)
datasets可以直接从Python字典或者DataFrames内存数据结构中读取数据,创建一个datasets.Dataset对象。
加载python字典(datasets.Dataset.from_dict:)
from datasets import Dataset
my_dict = {"a": [1, 2, 3]}
dataset = Dataset.from_dict(my_dict)
Pandas DataFrame(datasets.Dataset.from_pandas:)
from datasets import Dataset
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3]})
dataset = Dataset.from_pandas(df)
pandas.Series中的对象数据类型有时并不能让 Arrow 自动推断数据类型。
例如,如果 DataFrame 的长度为 0 或 Series 仅包含 None/nan 对象,则类型设置为 null。通过datasets.Features使用from_dict或from_pandas方法构造显式模式来避免潜在错误。有关如何明确指定您自己的功能的更多详细信息,请参阅故障排除( Troubleshooting)。
1.2.6 Offline离线(见原文)
1.3 切片拆分(Slice splits)
切片有两种选择:
- 字符串:简单的情况下使用,字符串更紧凑和可读
- datasets.ReadInstruction:更易于与可变切片参数一起使用
1.3.1 字符串拆分(包括交叉验证)
例如mrpc数据集,没拆分之前是:
from datasets import load_dataset
dataset = load_dataset('glue', 'mrpc', split='train')
dataset
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
- 拆分出train数据集:
dataset = load_dataset('glue', 'mrpc', split='train')
dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
'train+test’选择两个字段的数据集:
train_test_ds = load_dataset('glue', 'mrpc', split='train+test')
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 5393
})
- 选择train拆分的特定行:
train_10_20_ds =load_dataset('glue', 'mrpc', split='train[10:20]')#选择其中10 行数据
train_10pct_ds = load_dataset('glue', 'mrpc', split='train[:10%]')#选择10%的数据
train_10_80pct_ds =load_dataset('glue', 'mrpc', split='train[:10%]+train[-80%:]')#选择不同的拆分部分组合
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 10
})
#10%的拆分是367行
- 交叉验证的数据集拆分:
# 10 折交叉验证(另见下一节关于舍入行为):
# 验证数据集将分别为10%:,即[0%:10%], [10%:20%], ..., [90%:100%]。
# 每个训练数据集都将是互补的 90%:,[10%:100%](对应验证集[0%:10%]),
# [0%:10%] + [20%:100%](对于[10%:20%]的验证集),...,
# [0%:90%](对于 [90%:100%] 的验证集)。
vals_ds = load_dataset('glue', 'mrpc', split=[f'train[{k}%:{k+10}%]' for k in range(0, 100, 10)])
trains_ds = load_dataset('glue', 'mrpc', split=[f'train[:{k}%]+train[{k+10}%:]' for k in range(0, 100, 10)])
- 百分比切片和四舍五入
对于请求的切片边界没有被 100 整除的数据集,默认行为是将边界四舍五入到最接近的整数。因此,某些切片可能包含比其他切片更多的示例,如下例所示:
train_50_52_ds = datasets.load_dataset('bookcorpus', split='train[50%:52%]')
train_52_54_ds = datasets.load_dataset('bookcorpus', split='train[52%:54%]')
如果您想要大小相等的拆分,请改用pct1_dropremainder舍入。这会将指定的百分比边界视为 1% 的倍数:
train_50_52pct1_ds = datasets.load_dataset('bookcorpus', split=datasets.ReadInstruction( 'train', from_=50, to=52, unit='%', rounding='pct1_dropremainder'))
train_52_54pct1_ds = datasets.load_dataset('bookcorpus', split=datasets.ReadInstruction('train',from_=52, to=54, unit='%', rounding='pct1_dropremainder'))
train_50_52pct1_ds = datasets.load_dataset('bookcorpus', split='train[50%:52%](pct1_dropremainder)')
train_52_54pct1_ds = datasets.load_dataset('bookcorpus', split='train[52%:54%](pct1_dropremainder)')
1.4 Troubleshooting故障排除
有时,加载数据集时可能会得到意想不到的结果,接下来学习如何解决加载数据集时可能遇到的两个常见问题:手动下载数据集和指定数据集的特征。
1.4.1手动下载
由于许可不兼容,或者如果文件隐藏在登录页面后面,某些数据集需要您手动下载数据集文件。这将导致datasets.load_dataset()抛出一个AssertionError. 但是 Datasets 提供了下载丢失文件的详细说明。下载文件后,使用data_dir参数指定刚下载的文件的路径。
例如,如果您尝试从MATINF数据集下载配置:
dataset = load_dataset(“matinf”, “summarization”)
1.4.2 Specify features指定功能
当您从本地文件创建数据集时datasets.Features,Apache Arrow会自动推断。但是,数据集的特征可能并不总是符合您的期望,或者您可能想要自己定义特征。
以下示例显示了如何使用datasets.ClassLabel.
- 使用datasets.Features类定义您自己的标签:
class_names = ["sadness", "joy", "love", "anger", "fear", "surprise"]
emotion_features = Features({'text': Value('string'), 'label': ClassLabel(names=class_names)})
- 使用您刚刚创建的功能指定features参数datasets.load_dataset():
dataset = load_dataset('csv', data_files=file_dict, delimiter=';', column_names=['text', 'label'], features=emotion_features)
- 查看数据集features
dataset['train'].features
{'text': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=6, names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], names_file=None, id=None)}
1.5 加载自定义或本地metric
当 Datasets 不支持您要使用的指标时,您可以编写和使用您自己的指标脚本。通过提供本地指标加载脚本的路径来加载指标:
from datasets import load_metric
metric = load_metric('PATH/TO/MY/METRIC/SCRIPT')
# Example of typical usage
for batch in dataset:
inputs, references = batch
predictions = model(inputs)
metric.add_batch(predictions=predictions, references=references)
score = metric.compute()
1.5.2 Load configurations
度量标准可能具有不同的配置。配置存储在datasets.Metric.config_name属性中。加载指标时,请提供配置名称,如下所示:
from datasets import load_metric
metric = load_metric('bleurt', name='bleurt-base-128')
metric = load_metric('bleurt', name='bleurt-base-512')
1.6 分布式设置
当您在分布式或并行处理环境中工作时,加载和计算指标可能会很棘手,因为这些过程是在单独的数据子集上并行执行的。 Datasets 支持分布式使用,当你加载一个指标时,它带有一些额外的参数。
例如,假设您正在对八个并行流程进行培训和评估。以下是在此分布式设置中加载指标的方法:
- 使用num_process参数定义进程总数。
- 将过程设置rank为介于 0 和 之间的整数。num_process - 1
- datasets.load_metric()使用以下参数加载您的指标:
from datasets import load_metric
metric = load_metric('glue', 'mrpc', num_process=num_process, process_id=rank)
为分布式使用加载指标后,您可以照常计算指标。在幕后,datasets.Metric.compute()从节点收集所有预测和参考,并计算最终指标。
在某些情况下,您可能会在同一服务器和文件上同时运行多个独立的分布式评估。为了避免任何冲突,重要的是提供一个experiment_id区分单独的评估:
from datasets import load_metric
metric = load_metric('glue', 'mrpc', num_process=num_process, process_id=process_id, experiment_id="My_experiment_10")
二、Dataset数据处理
本节翻译自datasets-Process
Datasets 提供了许多用于修改数据集结构和内容的工具。您可以重新排列行的顺序或将嵌套字段提取到它们自己的列中。对于更强大的处理应用程序,您甚至可以通过将函数应用于整个数据集以生成新的行和列来更改数据集的内容。这些处理方法提供了很多控制和灵活性,可以将您的数据集塑造成具有适当特征的所需形状和大小。
本指南将向您展示如何:
- 重新排序行并拆分数据集。
- 重命名和删除列,以及其他常见的列操作。
- 将处理函数应用于数据集中的每个示例。
- 连接数据集。
- 应用自定义格式转换。
本指南中的所有处理方法都返回一个新的datasets.Dataset. 修改不是就地完成的。小心覆盖你以前的数据集!
2.1 Sort, shuffle, select, split, and shard
2.1.1 sort
用于datasets.Dataset.sort()根据数值对列值进行排序。提供的列必须与 NumPy 兼容。
DatasetDict可用但是感觉有点问题
from datasets import load_dataset
dataset = load_dataset('glue', 'mrpc', split='train')
dataset['label'][:10]
[1, 0, 1, 0, 1, 1, 0, 1, 0, 0]
sorted_dataset = dataset.sort('label')
sorted_dataset['label'][:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
sorted_dataset['label'][-10:]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
2.1.2 Shuffle(Dataset/DatasetDict可用)
该datasets.Dataset.shuffle()方法随机重新排列values of a column。还可以设定一些参数控制Shuffle算法。
shuffled_dataset = sorted_dataset.shuffle(seed=42)
shuffled_dataset['label'][:10]
[1, 1, 1, 0, 1, 1, 1, 1, 1, 0]
Args:
seed: Union[int, NoneType] = None,
generator: Union[numpy.random._generator.Generator, NoneType] = None,#用于计算数据集行排列的Numpy随机生成器。
keep_in_memory: bool = False,#将混洗后的索引保存在内存中,而不是将其写入缓存文件。
load_from_cache_file: bool = True,#从缓存加载数据,而不是重新shuffle计算
indices_cache_file_name: Union[str, NoneType] = None,#提供缓存文件的路径名
writer_batch_size: Union[int, NoneType] = 1000,#缓存文件写入器每次写入操作的行数。较高的值使处理进行更少的查找,较低的值在运行 .map() 时消耗较少的临时内存。
new_fingerprint: Union[str, NoneType] = None,
2.1.3 Select 和 Filter(选择特定的行数据)
datasets.Dataset.select() 根据索引列表返回行:
small_dataset = dataset.select([0, 10, 20, 30, 40, 50])
small_dataset
#选择了dataset的0, 10, 20, 30, 40, 50这6行数据
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 6})
datasets.Dataset.filter() 返回匹配指定条件的行,例如选择数据集中第一句话开头是’Ar’的数据:
start_with_ar = dataset.filter(lambda example: example['sentence1'].startswith('Ar'))
len(start_with_ar)
start_with_ar['sentence1']
['Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
'Arison said Mann may have been one of the pioneers of the world music movement and he had a deep love of Brazilian music .',
'Arts helped coach the youth on an eighth-grade football team at Lombardi Middle School in Green Bay .',
'Around 9 : 00 a.m. EDT ( 1300 GMT ) , the euro was at $ 1.1566 against the dollar , up 0.07 percent on the day .',
"Arguing that the case was an isolated example , Canada has threatened a trade backlash if Tokyo 's ban is not justified on scientific grounds .",
'Artists are worried the plan would harm those who need help most - performers who have a difficult time lining up shows .']
with_indices=True也可以按索引过滤,比如选择隔一行选择数据:
even_dataset = dataset.filter(lambda example, indice: indice % 2 == 0, with_indices=True)
even_dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1834})
2.1.4 Split(划分测试验证集)
datasets.Dataset.train_test_split()可以使数据集分成train和test部分。使用test_size指定测试集比例:
dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668})
data=dataset.train_test_split(test_size=0.1)
data#必须设赋值给另一个变量
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3301
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 367
})
})
DatasetDict不能用,只能是Dataset。所以如果是DatasetDict只含有train部分可以设置:
data1=load_dataset('csv',sep='\t',data_files='E:/国内赛事/天池-入门NLP - 新闻文本分类/ptrain.csv',split='train')
data2=data1.train_test_split(test_size=0.1)
默认情况下,拆分是shuffle的,但您可以设置shuffle=False来防止shuffle。
2.1.5 Shard分片
shard:将一个非常大的数据集划分为预定义数量的块。
参数:
- num_shards:要将数据集拆分的分片数。
- index:与index参数一起返回的shard。
例如,imdb数据集有 25000 个示例,将其划分为4片:
划分时默认contiguous: bool = False,每片数据不连续。如果指定为contiguous=True,则就是连续切分。(比如下面第一片就是索引0-916条数据)
dataset.shard(num_shards=4, index=0)
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 917})
同样的,DatasetDict无法分片
2.2 Rename, remove, cast, and flatten
2.2.1 Rename
重命名时,与原始列关联的特征实际上移动到新列名下,而不是仅仅就地替换原始列:
dataset
Dataset({
features: ['sentenceA', 'sentenceB', 'label', 'idx'],
num_rows: 3668})
2.2.2 Remove
使用.remove_columns(),给出要删除的列名。可以是一个列表:
dataset = dataset.remove_columns(['sentence1', 'sentence2'])
dataset
Dataset({
features: ['idx'],
num_rows: 3668})
2.2.3 Cast更改feature类型(还可以0/1和bool互换)
此方法将 newdatasets.Features作为参数,更改一列或多列的feature类型(datasets.ClassLabel和datasets.Value):
from datasets import load_dataset
datasets = load_dataset('imdb', split='train')
dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
from datasets import ClassLabel, Value
new_features = dataset.features.copy()
new_features["label"] = ClassLabel(names=['negative', 'positive'])
new_features["idx"] = Value('int64')
dataset = dataset.cast(new_features)
dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['negative', 'positive'], names_file=None, id=None),
'idx': Value(dtype='int64', id=None)}
仅当原始特征类型和新特征类型兼容时,cast才有效。例如,您可以cast一列feature type,从Value(‘int32’)到Value(‘bool’),如果原始列只包含一和零。
2.2.4 Flatten(嵌套feature拉平到同一层)
有时,一列可以是多种类型的嵌套结构。Flatten将子字段提取到它们自己单独的列中。从 SQuAD 数据集中看一下下面的嵌套结构:
from datasets import load_dataset
dataset = load_dataset('squad', split='train')
dataset.features
{'answers': Sequence(feature={'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None),
'context': Value(dtype='string', id=None),
'id': Value(dtype='string', id=None),
'question': Value(dtype='string', id=None),
'title': Value(dtype='string', id=None)}
该answers字段包含两个子字段:text和answer_start。将它们压平datasets.Dataset.flatten():
flat_dataset = dataset.flatten()
flat_dataset
Dataset({
features: ['id', 'title', 'context', 'question', 'answers.text', 'answers.answer_start'],
num_rows: 87599})
请注意子字段现在如何成为它们自己的独立列:answers.text和answers.answer_start。
2.3 Map
datasets.Dataset.map()主要目的是加速处理功能。可单独或批量地将处理函数应用于数据集中的每个example。这个函数甚至可以创建新的行和列。
在以下示例中,您将为sentence1数据集中的每个值添加前缀’My sentence: '。
- 创建一个添加前缀函数。该函数需要接受并输出 a :'My sentence: ''My sentence: '字典
def add_prefix(example):
example['sentence1'] = 'My sentence: ' + example['sentence1']
return example
- map处理数据集
updated_dataset = small_dataset.map(add_prefix)
updated_dataset['sentence1'][:5]
['My sentence: Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
"My sentence: Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'My sentence: They had published an advertisement on the Internet on June 10 , offering the cargo for sale , he added .',
'My sentence: Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
]
第二个例子,删除列:
updated_dataset = dataset.map(lambda example: {'new_sentence': example['sentence1']}, remove_columns=['sentence1'])
updated_dataset.column_names
['sentence2', 'label', 'idx', 'new_sentence']
Datasets 也有一个datasets.Dataset.remove_columns()方法,它在功能上是相同的,但是速度更快,因为它不会复制剩余列的数据。
2.3.2 多处理
多处理可以通过并行化 CPU 上的进程来显着加快处理速度。设置num_proc参数datasets.Dataset.map()以设置要使用的进程数:
updated_dataset = dataset.map(lambda example, idx: {'sentence2': f'{idx}: ' + example['sentence2']}, num_proc=4)
2.3.3 批处理
datasets.Dataset.map()还支持批量处理。设置批量操作batched=True。默认批量大小为 1000,但您可以使用batch_size参数进行调整。可以应用于:okenization、将长句子分成较短的块和数据增强data augmentation。
2.3.4 Tokenization
首先,从 BERT 模型加载分词器:
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
将分词器应用于该sentence1字段的批次:
encoded_dataset = dataset.map(lambda examples: tokenizer(examples['sentence1']), batched=True)
encoded_dataset.column_names
encoded_dataset[0]
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0,
'input_ids': [ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
现在您有三个新列,input_ids, token_type_ids, attention_mask,它们包含该sentence1字段的编码。
2.3.5 Split long examples
当您的examples太长时,您可能希望将它们分成几个较小的片段。
- 首先创建一个函数:
- 将sentence1字段拆分为 50 个字符的片段。
- 将所有片段堆叠在一起以创建新数据集。
def chunk_examples(examples):
chunks = []
for sentence in examples['sentence1']:
chunks += [sentence[i:i + 50] for i in range(0, len(sentence), 50)]
return {'chunks': chunks}
- 应用函数datasets.Dataset.map():
chunked_dataset = dataset.map(chunk_examples, batched=True, remove_columns=dataset.column_names)
chunked_dataset[:10]
{'chunks': ['Amrozi accused his brother , whom he called " the ',
'witness " , of deliberately distorting his evidenc',
'e .',
"Yucaipa owned Dominick 's before selling the chain",
' to Safeway in 1998 for $ 2.5 billion .',
'They had published an advertisement on the Interne',
't on June 10 , offering the cargo for sale , he ad',
'ded .',
'Around 0335 GMT , Tab shares were up 19 cents , or',
' 4.4 % , at A $ 4.56 , having earlier set a record']}
请注意现在如何将句子拆分为更短的块,并且数据集中有更多行。
dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
chunked_dataset
Dataset(schema: {'chunks': 'string'}, num_rows: 10470)
2.3.6 数据增强
通过批处理,您甚至可以使用其它examples来扩充数据集。在以下示例中,您将为句子中的掩码标记生成其他单词。
- 加载RoBERTA模型以在 Transformer FillMaskPipeline 中使用:
from random import randint
from transformers import pipeline
fillmask = pipeline('fill-mask', model='roberta-base')
mask_token = fillmask.tokenizer.mask_token
smaller_dataset = dataset.filter(lambda e, i: i<100, with_indices=True)
- 创建一个函数来随机选择要在句子中屏蔽的单词。该函数还应返回原始句子和 RoBERTA 生成的前两个替换。
def augment_data(examples):
outputs = []
for sentence in examples['sentence1']:
words = sentence.split(' ')
K = randint(1, len(words)-1)
masked_sentence = " ".join(words[:K] + [mask_token] + words[K+1:])
predictions = fillmask(masked_sentence)
augmented_sequences = [predictions[i]['sequence'] for i in range(3)]
outputs += [sentence] + augmented_sequences
return {'data': outputs}
map整个数据集:
augmented_dataset = smaller_dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, batch_size=8)
augmented_dataset[:9]['data']
['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'Amrozi accused his brother, whom he called " the witness ", of deliberately withholding his evidence.',
'Amrozi accused his brother, whom he called " the witness ", of deliberately suppressing his evidence.',
'Amrozi accused his brother, whom he called " the witness ", of deliberately destroying his evidence.',
"Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'Yucaipa owned Dominick Stores before selling the chain to Safeway in 1998 for $ 2.5 billion.',
"Yucaipa owned Dominick's before selling the chain to Safeway in 1998 for $ 2.5 billion.",
'Yucaipa owned Dominick Pizza before selling the chain to Safeway in 1998 for $ 2.5 billion.'
]
对于每个原始句子,RoBERTA 用三个备选方案增加了一个随机单词。在第一句话中,distorting这个词用withholding、suppressing和destroying 进行了数据增强。
2.3.7 处理多个splits
from datasets import load_dataset
dataset = load_dataset('glue', 'mrpc')
encoded_dataset = dataset.map(lambda examples: tokenizer(examples['sentence1']), batched=True)
encoded_dataset["train"][0]
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0,
'input_ids': [ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
2.3.8分布式使用
当您datasets.Dataset.map()在分布式环境中使用时,您还应该使用torch.distributed.barrier。这样可以确保主进程执行映射,而其他进程加载结果,从而避免重复工作。
以下示例显示了如何使用torch.distributed.barrier同步进程:
from datasets import Dataset
import torch.distributed
dataset1 = Dataset.from_dict({"a": [0, 1, 2]})
if training_args.local_rank > 0:
print("Waiting for main process to perform the mapping")
torch.distributed.barrier()
dataset2 = dataset1.map(lambda x: {"a": x["a"] + 1})
if training_args.local_rank == 0:
print("Loading results from main process")
torch.distributed.barrier()
2.4 Concatenate连接
如果不同的数据集共享相同的column types,则可以连接它们:
from datasets import concatenate_datasets, load_dataset
bookcorpus = load_dataset("bookcorpus", split="train")
wiki = load_dataset("wikipedia", "20200501.en", split="train")
wiki = wiki.remove_columns("title") # only keep the text
assert bookcorpus.features.type == wiki.features.type
bert_dataset = concatenate_datasets([bookcorpus, wiki])
您还可以通过从每个数据集交替示例来创建新数据集,从而将多个数据集混合在一起。这称为交错,您可以将它与datasets.interleave_datasets(). 双方datasets.interleave_datasets()并datasets.concatenate_datasets()会定期工作datasets.Dataset和datasets.IterableDataset对象。有关如何使用它的示例,请参阅Interleave部分
您还可以水平连接两个数据集(axis=1),只要它们具有相同的行数:
from datasets import Dataset
bookcorpus_ids = Dataset.from_dict({"ids": list(range(len(bookcorpus)))})
bookcorpus_with_ids = concatenate_datasets([bookcorpus, bookcorpus_ids], axis=1)
2.5 Format 格式
format方法将返回一个datasets.Dataset具有您指定格式的新对象:
dataset.with_format(type='tensorflow', columns=['input_ids', 'token_type_ids', 'attention_mask', 'label'])
如果你需要对数据集恢复到原来的格式,使用datasets.Dataset.reset_format():
dataset.format
{'type': 'torch', 'format_kwargs': {}, 'columns': ['label'], 'output_all_columns': False}
dataset.reset_format()
dataset.format
{'type': 'python', 'format_kwargs': {}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}
格式转换
datasets.Dataset.set_transform()允许您即时应用自定义格式转换。这将替换任何先前指定的格式。例如,您可以使用此方法即时标记和填充标记:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
def encode(batch):
return tokenizer(batch["sentence1"], padding="longest", truncation=True, max_length=512, return_tensors="pt")
dataset.set_transform(encode)
dataset.format
{'type': 'custom', 'format_kwargs': {'transform': <function __main__.encode(batch)>}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}
dataset[:2]
{'input_ids': tensor([[ 101, 2572, 3217, ... 102]]), 'token_type_ids': tensor([[0, 0, 0, ... 0]]), 'attention_mask': tensor([[1, 1, 1, ... 1]])}
在这种情况下,仅在访问示例时应用标记化。(the tokenization is applied only when the examples are accessed.)
想要 save数据集到云存储提供商?阅读云存储指南,了解如何将您的数据集保存到 AWS 或 Google 云存储!
2.6 保存和导出
2.6.1 保存和加载dataset
encoded_dataset.save_to_disk("path/of/my/dataset/directory")
from datasets import load_from_disk
reloaded_encoded_dataset = load_from_disk("path/of/my/dataset/directory")
2.6.2 Export导出
| 文件类型 | 导出方式 |
|---|---|
| CSV | datasets.Dataset.to_csv() |
| json | datasets.Dataset.to_json() |
| Parquet | datasets.Dataset.to_parquet() |
| 内存中的 Python 对象 | datasets.Dataset.to_pandas() 或者 datasets.Dataset.to_dict() |
例如导出为csv文件:
encoded_dataset.to_csv("path/of/my/dataset.csv")
三、优化器
3.1 weight decay
本节参考张贤笔记

- 对比不使用weight decay的训练策略,使用了 weight decay 的模型虽然在训练集的 loss 更高,但是更加平滑,泛化能力更强。
- 加上了 weight decay 后,随便训练次数的增加,权值的分布逐渐靠近 0 均值附近,这就是 L2 正则化的作用,约束权值尽量靠近 0。
3.1.2 weight decay 在 优化器中的实现:
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
...
...
...
p.data.add_(-group['lr'], d_p)
- dp 是计算得到的梯度,如果 weight decay 不为 0,那么更新 dp=dp+weight decay *p.data,对应公式: ( ∂ L o s s ∂ w i + λ ∗ w i ) \left(\frac{\partial L o s s}{\partial w{i}}+\lambda * w_{i}\right) (∂wi∂Loss+λ∗wi)
weight_decay (float, optional, defaults to 0) – The weight decay to apply (if not zero) to all layers except all bias and LayerNorm weights in AdamW optimizer.
这里trainer是默认不对layernorm和所有layer的biase进行weight decay的,因为模型通过大量语料学习到的知识主要是保存在weights中,这也是实际finetune bert的时候一个会用到的技巧,即分层weight decay(其实就是l2正则化),biase和layernorm的参数无所谓,但是保存了重要知识的weight我们不希望它变化太大,weight decay虽然是限制weight的大小的,但是考虑到一般良好的预训练模型的权重都比较稳定,所以也可以间接约束权重太快发生太大的变化。
3.2 关于学习率调度器:
参考transformers.optimization代码、Schedules参数和图像
3.2.1 trainer中设置学习率
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
from transformers import get_scheduler
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps)
trainer = Trainer(
model,
args,
train_dataset=datasets1 ,
eval_dataset=datasets2,
tokenizer=tokenizer,
optimizers=(optimizer,lr_scheduler))
3.2.2 get_scheduler具体参数
def get_scheduler(
name: Union[str, SchedulerType],#学习率策略名称
optimizer: Optimizer,
num_warmup_steps: Optional[int] = None,#要执行的热身步骤数
num_training_steps: Optional[int] = None,#要执行的训练步骤数
):
调度器策略名:
SchedulerType(value,names=None,*,module=None,qualname=None,type=None,start=1,)
Docstring: An enumeration.
Source:
class SchedulerType(ExplicitEnum):
LINEAR = "linear"#预热期线性增加到lr,之后线性减少到0
COSINE = "cosine"#预热余弦lr策略
COSINE_WITH_RESTARTS = "cosine_with_restarts"#预热余弦estart策略
POLYNOMIAL = "polynomial"#预热后从初始学习率到end lr的多项式衰减学习率
CONSTANT = "constant"#学习率保持不变
CONSTANT_WITH_WARMUP = "constant_with_warmup"#预热期lr是0到lr线性增加,之后lr恒定
所谓线性就是current_step/num_training_steps这种正比或者反比变化
策略名对应的策略函数
TYPE_TO_SCHEDULER_FUNCTION = {
SchedulerType.LINEAR: get_linear_schedule_with_warmup,#预热期线性增加到lr,之后线性减少到0
SchedulerType.COSINE: get_cosine_schedule_with_warmup,#预热余弦lr策略
SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_hard_restarts_schedule_with_warmup,#预热余弦estart策略
SchedulerType.POLYNOMIAL: get_polynomial_decay_schedule_with_warmup,
SchedulerType.CONSTANT: get_constant_schedule,#学习率保持不变
SchedulerType.CONSTANT_WITH_WARMUP: get_constant_schedule_with_warmup,#预热期lr是0到lr线性增加,之后lr恒定
}
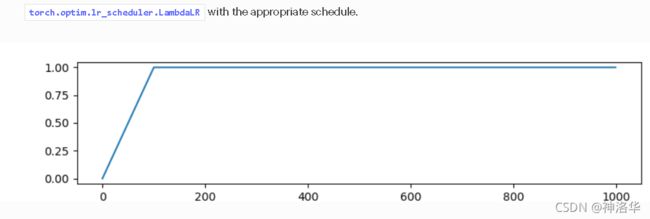
- constant_with_warmup函数:(预热后恒定)
def get_constant_schedule_with_warmup(optimizer: Optimizer, num_warmup_steps: int, last_epoch: int = -1):
def lr_lambda(current_step: int):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1.0, num_warmup_steps))
return 1.0
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
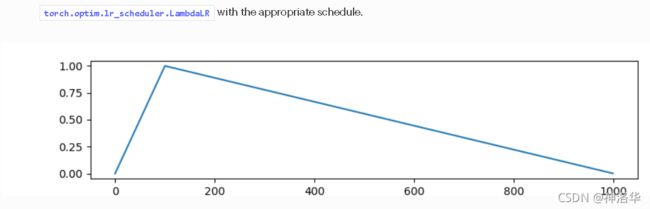
- linear函数(get_linear_schedule_with_warmup)(预热后线性减少)
def lr_lambda(current_step: int):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
return max(
0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))
)#剩余步数/预热外步数
return LambdaLR(optimizer, lr_lambda, last_epoch)
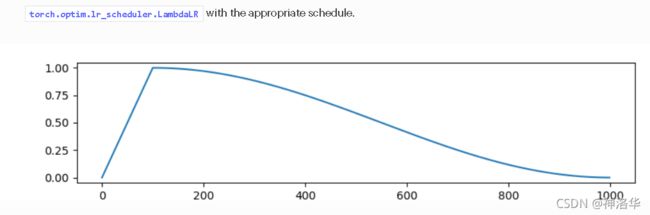
- cosine(预热余弦函数)
def get_cosine_schedule_with_warmup(
optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1
):
def lr_lambda(current_step):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
#0.5+0.5cos(2pi*cycles*(steps-预测步数)/(总步数-预热步数))
return LambdaLR(optimizer, lr_lambda, last_epoch)
- cosine_with_restarts()
def get_cosine_with_hard_restarts_schedule_with_warmup(
optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: int = 1, last_epoch: int = -1
):
def lr_lambda(current_step):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
if progress >= 1.0:
return 0.0
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * ((float(num_cycles) * progress) % 1.0))))
return LambdaLR(optimizer, lr_lambda, last_epoch)
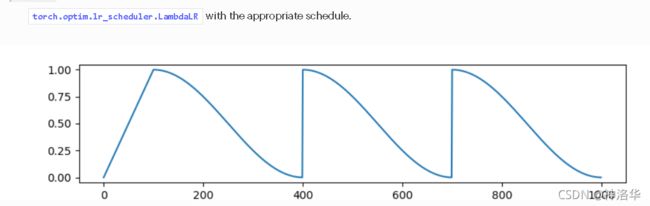
5. polynomial
def get_polynomial_decay_schedule_with_warmup(
optimizer, num_warmup_steps, num_training_steps, lr_end=1e-7, power=1.0, last_epoch=-1
):
"""
Create a schedule with a learning rate that decreases as a polynomial decay from the initial lr set in the
optimizer to end lr defined by `lr_end`, after a warmup period during which it increases linearly from 0 to the
initial lr set in the optimizer.
"""
lr_init = optimizer.defaults["lr"]
if not (lr_init > lr_end):
raise ValueError(f"lr_end ({lr_end}) must be be smaller than initial lr ({lr_init})")
def lr_lambda(current_step: int):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
elif current_step > num_training_steps:
return lr_end / lr_init # as LambdaLR multiplies by lr_init
else:
lr_range = lr_init - lr_end
decay_steps = num_training_steps - num_warmup_steps
pct_remaining = 1 - (current_step - num_warmup_steps) / decay_steps
decay = lr_range * pct_remaining ** power + lr_end
return decay / lr_init # as LambdaLR multiplies by lr_init
return LambdaLR(optimizer, lr_lambda, last_epoch)
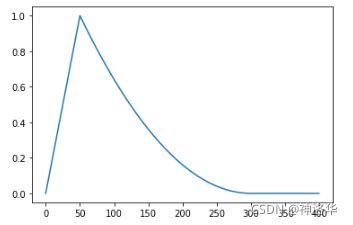
lr_init = 10,num_warmup_steps=50,num_training_steps=300
lr_end=1e-7,power=2.0,last_epoch=-1的图像为: