西瓜书学习笔记---第二章 模型评估与选择
目录
一、题目要求
二、数据集介绍
三、十折交叉验证
3.1 支持向量机模型
3.2 决策树模型
四、模型评估
4.1 混淆矩阵
4.2 查准率P
4.3 查全率
4.4 F1-Score
4.5 P-R曲线
4.6 ROC曲线
4.7 AUC值
五、交叉验证T检验
六、运行结果
七、附件
一、题目要求
- 选取某UCI分类数据集,划分数据集,用10折交叉验证,选用两个现成的分类算法(或者一个算法、参数不同),得到分类模型A和B,给出交叉验证预测结果。
- 对两模型的交叉验证预测结果,分别给出混淆矩阵、P、R和F1值,作出P-R曲线、ROC曲线,并求AUC。
- 应用paired t-test假设检验,比较两个模型性能的优劣。
二、数据集介绍
选用的数据集为UCI分类数据集中的糖尿病“Diabetes”数据集 https://archive.ics.uci.edu/ml/machine-learning-databases/00296/ 数据集共包含768条信息,每条信息对应一位可能患有糖尿病的患者的8个属性,并给出了该患者是否患有糖尿病的结果,“1”表示该患者确实患有糖尿病,“0”表该患者不患有糖尿病。“Diabetes”数据集的具体内容如下图所示。
https://archive.ics.uci.edu/ml/machine-learning-databases/00296/ 数据集共包含768条信息,每条信息对应一位可能患有糖尿病的患者的8个属性,并给出了该患者是否患有糖尿病的结果,“1”表示该患者确实患有糖尿病,“0”表该患者不患有糖尿病。“Diabetes”数据集的具体内容如下图所示。

三、十折交叉验证
3.1 支持向量机模型
给定训练样本集![]() ,分类学习的最基本得想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开。在样本空间中,划分超平面可以通过如下线性方程来描述:
,分类学习的最基本得想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开。在样本空间中,划分超平面可以通过如下线性方程来描述:

假设能将训练样本正确分类,则有:

利用距离超平面最近的几个训练样本点,使得上述不等式的等号成立,则它们被称为“支持向量”。在本实验中,我们调用了sklearn中的函数来实现支持向量机 :
1. clt = svm.SVC(C=1.5, kernel='rbf', probability=True) # SVM拟合训练数据3.2 决策树模型
决策树(decision tree)是一类常见的机器学习方法。以二分类任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,这个把样本分类的任务,可看作对“当前样本属于正类吗?”这个问题的“决策”或“判定”过程。顾名思义,决策树是基于树结构来进行决策的,这恰是人类在面临决策问题时一种很自然的处理机制。显然,决策过程的最终结论对应了我们所希望的判定结果,决策过程中提出的每个判定问题都是对某个属性的“测试”,而每个测试的结果或是导出最终结论,或是导出进一步的判定问题,并且其考虑范围是在上次决策结果的限定范围之内。
在本实验中,我们调用了sklearn中的函数来实现决策树。
1. clt = tree.DecisionTreeClassifier() 四、模型评估
分类算法如果用分类准确度来衡量好坏将会存在问题。在存在极度偏斜的数据中,应用分类准确度来评价分类算法的好坏是远远不够的。
4.1 混淆矩阵
对于二分类模型而言,其分类结果主要有以下四种:
·TP:True Positive,表示实际为正例,被预测为正例,预测正确
·FP:False Positive,表示实际为负例,被预测为正例,预测错误
·FN:False Negative,表示实际为正例,被预测为负例,预测错误
·TN:True Negative,表示实际为负例,被预测为负例,预测正确
根据上述四种分类结果,可以得到模型的混淆矩阵如下表所示:
| 混淆矩阵 |
真实值 |
||
| 结果为正(P) |
结果为负(N) |
||
| 预测值 |
预测为正(P) |
TP |
FP |
| 预测为负(N) |
FN |
TN |
|
4.2 查准率P
在真实值为正的样本中,预测正确的样本占比,其计算公式表示为:
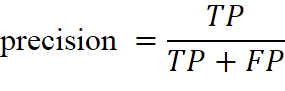
4.3 查全率
在预测值为正的样本中,预测为正的样本占比,其计算公式表示为:

4.4 F1-Score
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0,其公式为:
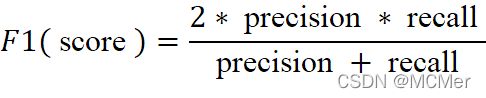
4.5 P-R曲线
获取分类器对每个测试样例属于某个类别的概率预测值,根据分类器的预测结果从大到小对样例进行排序,逐个把样例加入正例进行预测,算出此时的P、R值,得到查准率-查全率(P-R)曲线。
在本次实验中,为了更好的理解P-R曲线,我们并没有调用scikit-learn包中的precision_recall_curve()函数直接生成曲线,而是依据P-R曲线的绘制原理,自己实现了相关函数的功能。
def PR_curve(y, pred):
pos = np.sum(y == 1) # 样例中正例的个数
neg = np.sum(y == 0) # 样例中负例的个数
pred_sort = np.sort(pred)[::-1] # 从大到小排序
index = np.argsort(pred)[::-1] # 从大到小排序
y_sort = y[index] # 排好序的样例
Pre = [] # 用于记录一系列precision值
Rec = [] # 用于记录一系列recall值
for i, item in enumerate(pred_sort):
if i == 0: # 因为计算precision的时候分母要用到i,当i为0时会出错,所以单独列出
Pre.append(1)
Rec.append(0)
else:
Pre.append(np.sum((y_sort[:i] == 1)) / i) # 从大到小阈值排列,所以全部都预测为正例
Rec.append(np.sum((y_sort[:i] == 1)) / pos) # TP/实际正例的个数
首先使用np.sum函数统计了被测样本中正例和负例的数量,接着对被测样本按照其正例预测概率由大到小排序,按照已排好的顺序对样本逐个添加并计算precision值和recall值。 ,因为按照概率由大到小的顺序进行添加样本并设定阈值,所以每一个样本都是以正例预测被添加的,因此可以得到
,因为按照概率由大到小的顺序进行添加样本并设定阈值,所以每一个样本都是以正例预测被添加的,因此可以得到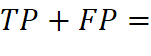 已添加的样本数i;
已添加的样本数i;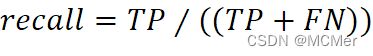 ,
, 真实的正例数量。计算得到precision和recall数组之后,使用matplotlib进行作图。
真实的正例数量。计算得到precision和recall数组之后,使用matplotlib进行作图。
4.6 ROC曲线
获取分类器对每个测试样例属于某个类别的概率预测值,根据分类器的预测结果从大到小对样例进行排序,设阈值为Inf,全判为反例,得到(0,0),逐个把样例加入正例进行预测,算出此时的TPR、FPR值,得到ROC曲线。
在本次实验中,为了更好的理解ROC曲线,我们并没有调用scikit-learn包中的roc_curve()函数直接生成曲线,而是依据P-R曲线的绘制原理,自己实现了相关函数的功能。
def ROC_curve(y, pred):
pos = np.sum(y == 1) # 样例中正例的个数
neg = np.sum(y == 0) # 样例中负例的个数
pred_sort = np.sort(pred)[::-1] # 从大到小排序
index = np.argsort(pred)[::-1] # 从大到小排序
y_sort = y[index] # 排好序的样例
tpr = []
fpr = []
thr = []
for i, item in enumerate(pred_sort):
tpr.append(np.sum((y_sort[:i] == 1)) / pos)
fpr.append(np.sum((y_sort[:i] == 0)) / neg)
thr.append(item)
auc_value = get_auroc(fpr, tpr) # 计算AUC值
对于ROC曲线首先使用np.sum函数统计了被测样本中正例和负例的数量,接着对被测样本按照其正例预测概率由大到小排序,按照已排好的顺序对样本逐个添加并计算TPR值和FPR值, ,
,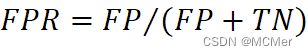 ,计算得到TPR和FPR数组之后,使用matplotlib库进行画图。
,计算得到TPR和FPR数组之后,使用matplotlib库进行画图。
4.7 AUC值
ROC (Receiver Operating Characteristic)曲线下面的面积越大,模型就越好。这个曲线下面积就称为AUC(Area Under the Curve)。假设ROC曲线由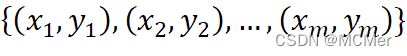 的点按序连接而形成
的点按序连接而形成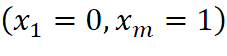 ,则AUC可估算为:
,则AUC可估算为:
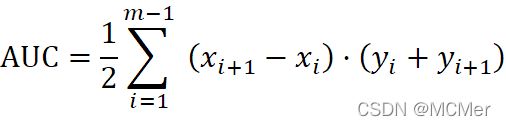
# 计算AUROC值
get_auroc(fpr, tpr):
auc_value = 0.0
for ix in range(len(fpr[:-1])):
x_right, x_left = fpr[ix], fpr[ix + 1]
y_top, y_bottom = tpr[ix], tpr[ix + 1]
temp_area = abs(x_right - x_left) * (y_top + y_bottom) * 0.5
auc_value += temp_area
return auc_value
五、交叉验证T检验
我们利用交叉验证T检验来对不同学习器的性能进行比较,对两个学习器A和B,若k折交叉验证得到的测试错误率分别为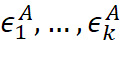 和
和 ,可用k折交叉验证“成对t检验”进行比较检验。若两个学习器的性能相同,则他们使用相同的训练/测试集得到的测试错误率应相同,即
,可用k折交叉验证“成对t检验”进行比较检验。若两个学习器的性能相同,则他们使用相同的训练/测试集得到的测试错误率应相同,即 。
。
先对每对结果求差, ,若两个学习器性能相同,则差值应该为0,继而用
,若两个学习器性能相同,则差值应该为0,继而用 来对“学习器A与B性能相同”这个假设做t检验。
来对“学习器A与B性能相同”这个假设做t检验。
在本实验中,我们对于同一组十折交叉验证训练数据集在“SVM模型”和“决策树模型”上的错误率进行交叉验证T检验。主要使用sklearn中的函数实现。
wrong_tree = [1 - x for x in acc_tree]
wrong_svm = [1 - x for x in acc_svm]
m = scipy.stats.ttest_ind(wrong_tree, wrong_svm, equal_var=False)
六、运行结果
6.1 选取某UCI分类数据集,划分数据集,用10折交叉验证,选用两个现成的分类算法(或者一个算法、参数不同),得到分类模型A和B,给出交叉验证预测结果。
(1)支持向量机SVM的十折交叉验证预测结果
 SVM十折交叉验证预测结果
SVM十折交叉验证预测结果
(2)决策树的十折交叉验证预测结果
 决策树十折交叉验证预测结果
决策树十折交叉验证预测结果
6.2 对两模型的交叉验证预测结果,分别给出混淆矩阵、P、R和F1值,作出P-R曲线、ROC曲线,并求AUC。
(1)支持向量机SVM的模型评估
模型评估代码结果输出为:

根据输出结果可以得到SVM模型的混淆矩阵、P、R和F1值,作出P-R曲线、ROC曲线及其AUC如下所示:
| 混淆矩阵 |
真实值 |
||
| 结果为正(P) |
结果为负(N) |
||
| 预测值 |
预测为正(P) |
TP=451 |
FP=49 |
| 预测为负(N) |
FN=135 |
TN=133 |
|
| P值 |
R值 |
F1 |
| 0.770 |
0.902 |
0.831 |
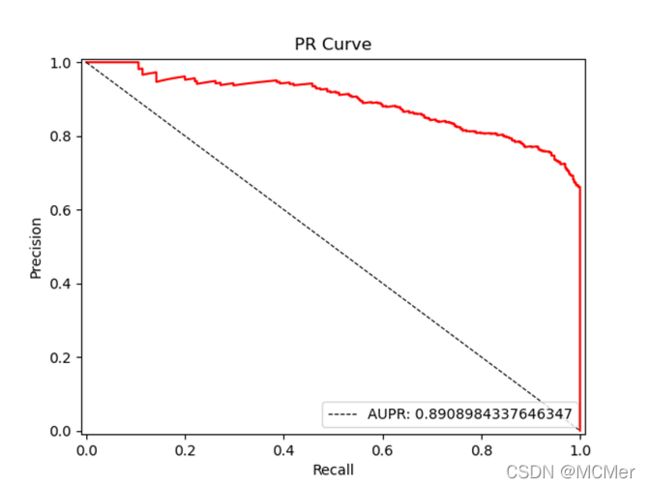 SVM模型的P-R曲线
SVM模型的P-R曲线
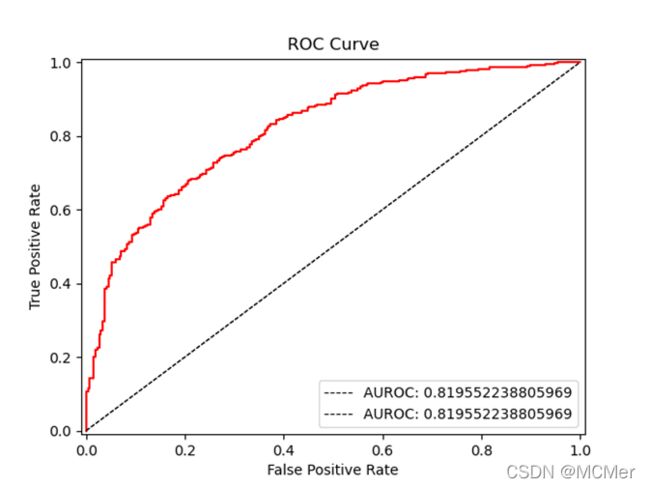 SVM模型的ROC曲线
SVM模型的ROC曲线
(2)决策树的模型评估
模型评估代码结果输出为:
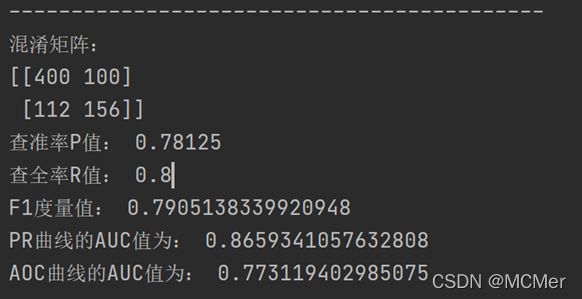
根据输出结果可以得到决策树模型的混淆矩阵、P、R和F1值,作出P-R曲线、ROC曲线及其AUC如下所示:
| 混淆矩阵 |
真实值 |
||
| 结果为正(P) |
结果为负(N) |
||
| 预测值 |
预测为正(P) |
TP=400 |
FP=100 |
| 预测为负(N) |
FN=112 |
TN=156 |
|
| P值 |
R值 |
F1 |
| 0.781 |
0.8 |
0.791 |
 决策树模型的P-R曲线
决策树模型的P-R曲线
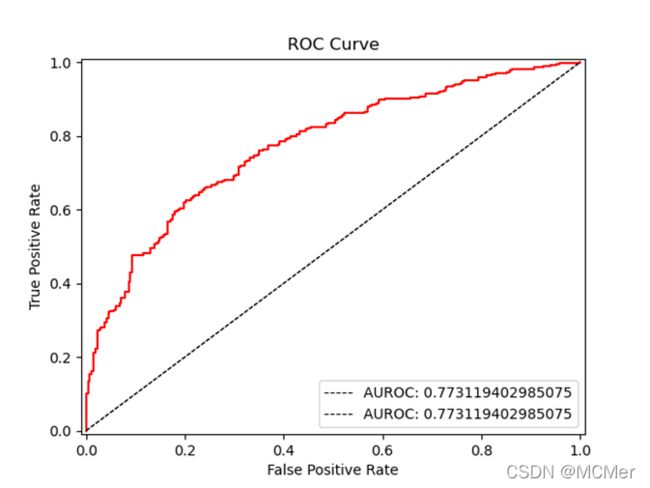 决策树模型的ROC曲线
决策树模型的ROC曲线
6.3 应用paired t-test假设检验,比较两个模型性能的优劣。
应用paired t-test假设检验,比较两个模型性能的优劣。
Paired t-test假设检验输出结果如下:
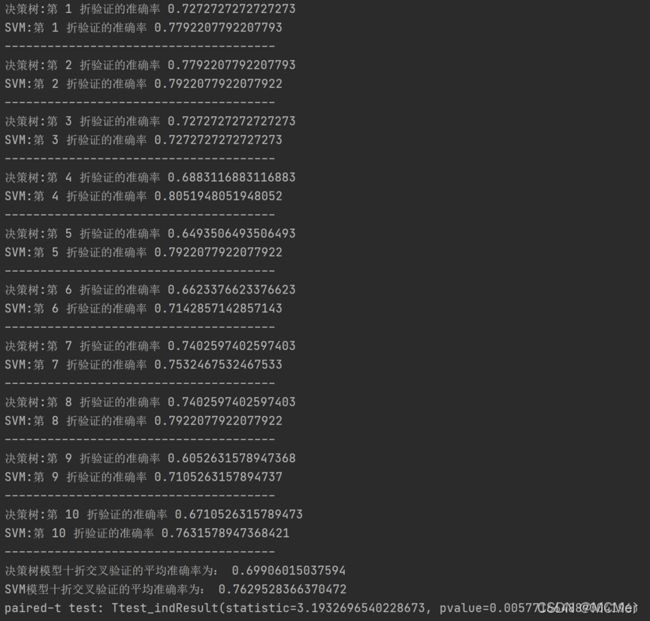 SVM模型和决策树模型的paired t-test假设检验
SVM模型和决策树模型的paired t-test假设检验
原假设H0两个机器学习的泛化性能相同,得出p值=0.0058,非常小,因此原假设不成立,两个模型的泛化性能不同。
七、附件
(1)1_svm.py:利用“支持向量机SVM”模型对数据集进行十折交叉验证的预测结果;
(2)1_tree.py:利用“决策树”模型对数据集进行十折交叉验证的预测结果;
(3)2_svm.py:对“支持向量机SVM”模型的交叉验证预测结果,分别给出混淆矩阵、P、R和F1值,绘制P-R曲线、ROC曲线,并求AUC;
(4)2_tree.py:对“决策树”模型的交叉验证预测结果,分别给出混淆矩阵、P、R和F1值,绘制P-R曲线、ROC曲线,并求AUC;
(5)3_svm+tree.py:应用paired t-test假设检验,比较“支持向量机SVM”模型和“决策树”模型性能的优劣。