论文阅读《Meta-FDMixup:Cross-Domain Few-Shot Learning Guided by Labeled Target Data》
Background & Motivation
之前看的小样本论文大部分是目标域和源域属于同一个域,比如 COCO 数据集里的小样本设定:60类为 Base,20类为 Novel。Base 和 Novel 都属于同一个数据集,同一个域内。
而对于底片缺陷检测(类似于下图中的医学射线图像),与传统数据集相比我主观上认为不属于同一个域,因此就涉及到了域适应 Domain Adaptation、域泛化 Domain Generation 和跨域 Cross Domain。数
据集间是否属于同一个域目前还没有看到有客观的证明方法,有这方面的研究,但是还没看的及看。在另一篇跨域学习的论文《A Broader Study of Cross-Domain Few-Shot Learning》里有这样一段论述(觉得有道理但还是有些不妥:因为这个判断标准也是主观的看法):

将在此之前的 Domain Adaptation 分为三类:discrepancy based methods、adversarial based methods 和 reconstruction based methods。但本文的方法与之前的不同点是类别的集合不同,并且只有少量的目标域数据。
文章也提到了数据增强方法 Mixup 及其变体:CutMix、Manifold Mixup、AugMix 和 PuzzleMix,以及同样是跨域的数据增强方法:Xmixup。
一一比较了在此之前的小样本跨域学习方法及其不足之处:
- FWT、LRP-GNN 和 SB-MTL,第一个需要用多个数据集来满足元学习的需求,同时这三者的精度都不如本文的方法。
- STARTUP,这篇论文里的方法需要用大量无标签的目标域数据,在一些情况下也是不能满足的。
本文针对上述小样本跨域学习方法的不足,提出了改进:不需要多个数据集和大量数据。
Meta-FDMixup Network
模型结构如下:
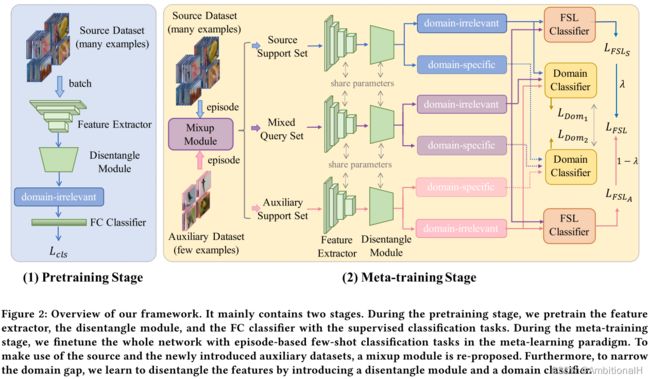
网络的任务为小样本类别分类和域分类。
源域和目标域数据中物体类别没有交集,将源域的数据分为 Sbase、Seval 和 Snovel,目标域的数据分为 Tbase、Teval 和 Tnovel,base、eval 和 novel 之间物体类别也没有交集。接下来的实验中 Sbase 作为训练集,Seval 作为验证集,Tnovel 作为测试集。并从目标域的 Tbase 中每个类别分别抽出固定数量的数据作为 auxiliary dataset(Daux)。
有点绕,其实就是源域数据 Sbase、Seval 用来训练和验证,目标域的数据 Tbase 用来辅助,同时目标域的数据 Tnovel 用来测试。训练和验证、辅助和测试这四种类别都不交叉。

采用元学习的策略,在一个数据集内。训练时每个 episode 从 Sbase 中采样一个 Source,从 Daux 采样一个 Auxiliary。Source episode 又分为 Source Support Set 和 source query set,Auxiliary episode 又分为 Auxiliary Support Set 和 auxiliary query set(论文这里写的很不清楚...看代码)。
'''Source episode'''
base_datamgr = SetDataManager(image_size, n_query = n_query, **train_few_shot_params)
base_loader = base_datamgr.get_data_loader( source_base_file , aug = params.train_aug)
'''Auxiliary episode'''
labeled_base_file_dict = {}
labeled_base_file_dict['cub'] = 'sources/labled_base_cub_' + str(params.target_num_label)+'.json'
labeled_base_file_dict['cars'] = 'sources/labled_base_cars_' + str(params.target_num_label)+'.json'
labeled_base_file_dict['places'] = 'sources/labled_base_places_' + str(params.target_num_label)+'.json'
labeled_base_file_dict['plantae'] = 'sources/labled_base_plantae_' + str(params.target_num_label)+'.json'
labeled_base_file = labeled_base_file_dict[params.target_set]
labeled_target_datamgr = SetDataManager(image_size, n_query = n_query, **train_few_shot_params)
labeled_target_loader = labeled_target_datamgr.get_data_loader(labeled_base_file, aug = params.train_aug)
model = MetaFDMixup(model_dict[params.model], tf_path=params.tf_dir, **train_few_shot_params)
model = train(base_loader, val_loader, model, start_epoch, stop_epoch, params, labeled_target_loader)
total_it = model.train_loop(epoch, base_loader, labeled_target_loader, optimizer, total_it)
def train_loop(self, epoch, train_loader, labeled_target_loader, optimizer, total_it):
for (i,(x_1,_)), (j,(x_2,_)) in zip(enumerate(train_loader), enumerate(labeled_target_loader)):
loss_FSL, loss_domain_fusion, loss_domain_CLS = self.set_forward_loss_for_train(x_1, x_2)
def set_forward_loss_for_train(self, x_1, x_2):
'''Source Support Set'''
x_1_support = x_1[:,:self.n_support,:,:,:]
# source query set
x_1_query = x_1[:,self.n_support:,:,:,:]
'''Auxiliary Support Set'''
x_2_support = x_2[:,:self.n_support,:,:,:]
# auxiliary query set
x_2_query = x_2[:,self.n_support:,:,:,:]
'''得到 Mixed Query Set'''
mixed_query, lamda = mixup_data(x_1_query, x_2_query)对 source query set 和 auxiliary query set 执行 Mixup 操作,生成一个 Mixed Query Set。这三个数据集 Source Support Set、Auxiliary Support Set 和 Mixed Query Set 为最终网络的输入。
x_1_S_fea = self.set_forward_feature_extractor(x_1_support)
x_2_S_fea = self.set_forward_feature_extractor(x_2_support)
mix_Q_fea = self.set_forward_feature_extractor(mixed_query)
# forward disentangle module
input_fea_concat_1 = torch.cat((x_1_S_fea, x_2_S_fea), dim=0)
input_fea_concat = torch.cat((input_fea_concat_1, mix_Q_fea), dim=0)
a_code, b_code= self.set_forward_disentangle_module(input_fea_concat)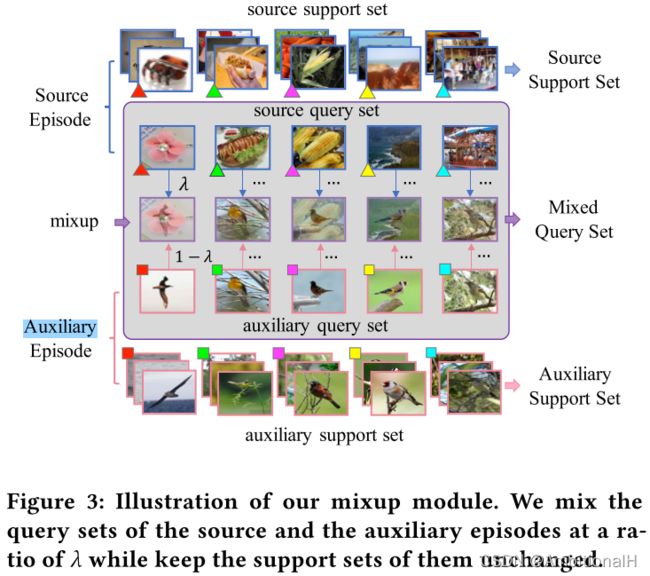
将数据依次经过 feature extractor 和 disentangle module 后分别得到 domain-irrelevant features 和 domain-specific features,disentangle module 结构如下:
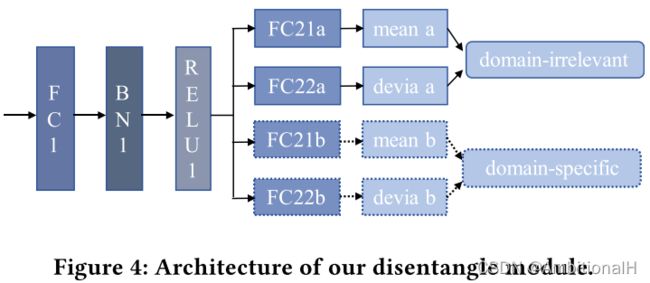
由 FC 层、BN 层和 ReLU 层构成,图中 FC1 用来提取通用特征,FC21a、FC22a 和 FC21b、FC22b 分别用来提取 domain-irrelevant features 和 domain-specific features。features 这里定义为标准差和均值,实际上就是 domain-irrelevant 和 domain-specific 的分布或者说是一个 latant vector:
class Disentangle(nn.Module):
def __init__(self):
super(Disentangle, self).__init__()
#encoder
self.fc1 = nn.Linear(512, 256)
self.bn1 = nn.BatchNorm1d(256, momentum=0.1)
self.fc21a = nn.Linear(256, 64)
self.fc22a = nn.Linear(256, 64)
self.fc21b = nn.Linear(256, 64)
self.fc22b = nn.Linear(256, 64)
def encode(self, x):
h1 = F.relu(self.bn1(self.fc1(x)))
# a encoder: domain irrelevant
a_mean, a_logvar = self.fc21a(h1), self.fc22a(h1)
# b encoder: domain specific
b_mean, b_logvar = self.fc21b(h1), self.fc22b(h1)
return a_mean, a_logvar, b_mean, b_logvar
def reparametrize(self, mu,logvar):
std = logvar.mul(0.5).exp_()
if torch.cuda.is_available():
eps = torch.cuda.FloatTensor(std.size()).normal_()
else:
eps = torch.FloatTensor(std.size()).normal_()
eps = Variable(eps)
return eps.mul(std).add_(mu)
def forward(self, x):
a_mu, a_logvar, b_mu, b_logvar = self.encode(x)
a_fea = self.reparametrize(a_mu, a_logvar) # domain-irrelevant (H1)
b_fea = self.reparametrize(b_mu, b_logvar) # domain-specific (H2)
return a_fea, b_feadisentangle module 用来缓解跨域小样本中的 domain shift。
再之后利用三个数据集各自的 domain-irrelevant features 通过聚合来完成小样本类别分类任务,将 Mixed Query Set 分别聚合到 Source Support Set 和 Auxiliary Support Set 上输入到小样本分类器中得到分类结果,这两个结果与 gt 计算损失后乘以 Mixup 的标签置信得分再相加得到最终的分类损失:
![]()
x_1_S_len = x_1_S_fea.size()[0]
x_2_S_len = x_2_S_fea.size()[0]
mix_Q_len = mix_Q_fea.size()[0]
x_1_F, x_2_F, mix_F = x_1_S_a_code, x_2_S_a_code, mix_Q_a_code
x_1_F = x_1_F.view(self.n_way, -1, x_1_F.size()[1])
x_2_F = x_2_F.view(self.n_way, -1, x_2_F.size()[1])
mix_F = mix_F.view(self.n_way, -1, mix_F.size()[1])
'''这几行代码完成聚合'''
mixup_x_1 = torch.cat((x_1_F, mix_F), 1)
mixup_x_2 = torch.cat((x_2_F, mix_F), 1)
mixup_x_1 = mixup_x_1.view(-1, mixup_x_1.size()[2])
mixup_x_2 = mixup_x_2.view(-1, mixup_x_2.size()[2])
'''分类得分'''
scores_FSL_1 = self.set_forward_FSL_classifier(mixup_x_1)
scores_FSL_2 = self.set_forward_FSL_classifier(mixup_x_2)
'''ground-truth for FSL classification,从0开始到self.n_way-1,每个数重复 self.n_query 次'''
y_query_1 = torch.from_numpy(np.repeat(range( self.n_way ), self.n_query))
y_query_2 = torch.from_numpy(np.repeat(range( self.n_way ), self.n_query))
y_query_1 = y_query_1.cuda()
y_query_2 = y_query_2.cuda()
'''calculate the loss_FSL'''
loss_FSL_1 = self.loss_fn(scores_FSL_1, y_query_1)
loss_FSL_2 = self.loss_fn(scores_FSL_2, y_query_2)
loss_FSL = lamda*loss_FSL_1 + (1-lamda)*loss_FSL_2 # lamda 为 Mixup 的置信得分文章中定义 source domain 的 gt 为1,target domain 的 gt 为0。代码中可以看出将 domain-irrelevant features 的标签全部设为了0.5,domain-specific features 中 source domain 的 gt 为1,target domain 的 gt 为0。
'''ground truth'''
episode_batch = x_1_S_a_domain_scores.size()[0]
y_1_S_a = Variable(torch.ones(episode_batch, 2)/2.0).cuda() #[0,5, 0.5]
y_1_S_b = Variable(torch.ones(episode_batch).long()).cuda() #[1.0, 1.0]
y_2_S_a = Variable(torch.ones(episode_batch, 2)/2.0).cuda() #[0.5, 0.5]
y_2_S_b = Variable(torch.zeros(episode_batch).long()).cuda() #[0.0, 0.0]
episode_batch_mix = mix_Q_a_domain_scores.size()[0]
y_mix_a = Variable(torch.ones(episode_batch_mix, 2)/2.0).cuda() #[0.5,0.5]
y_mix_b_1 = Variable(torch.ones(episode_batch_mix).long()).cuda() #[1.0,1.0] with a ratio of lamda
y_mix_b_2 = Variable(torch.zeros(episode_batch_mix).long()).cuda() #[0.0,0.0] with a ratio of (1-lamda)这是因为对于域分类,我们希望域分类器用 domain-specific features 可以轻易分出域的类别,而 domain-irrelevant features 则是希望会让域分类器困惑。那么就对 domain-specific features “赏罚分明”,而这里还加入了 domain-irrelevant features,我认为作用是增强模型整体性能。
至于为什么要让它学习 [0.5, 0.5],有点想不通。如果是为了排除这部分特征的影响,完全可以不用这一部分特征呀。还有一种理解是尽可能地将所有的特征都利用起来,那么让它学习 [0.5, 0.5] 也即将这部分特征固定住,不影响其他地方的学习?
-----------------2022.05.10
最近在学习 GAN,突然就理解了这里为什么是0.5,跟 GAN 的收敛条件一样。因为是0.5的话相当于域分类器躺平,无法分辨出两个域的数据。
文章后面写的看不懂...看代码吧:
self.domain_model = DomainClassifier()
'''损失函数'''
self.loss_fn = nn.CrossEntropyLoss()
self.loss_KLD = nn.KLDivLoss()
...
class DomainClassifier(nn.Module):
def __init__(self):
super(DomainClassifier, self).__init__()
# classifier
self.domain_fc = nn.Linear(64, 2)
def forward(self, x):
out = self.domain_fc(x)
return out
...
'''disentangle module 输出的特征'''
x_1_S_a_code, x_1_S_b_code = a_code[0:x_1_S_len, :], b_code[0:x_1_S_len, :]
x_2_S_a_code, x_2_S_b_code = a_code[x_1_S_len: x_1_S_len+x_2_S_len, :], b_code[x_1_S_len: x_1_S_len+x_2_S_len, :]
mix_Q_a_code, mix_Q_b_code = a_code[x_1_S_len + x_2_S_len:, :], b_code[x_1_S_len + x_2_S_len:, :]
'''再经过一层全连接层,得到域分类得分'''
x_1_S_a_domain_scores = self.domain_model(x_1_S_a_code)
x_1_S_b_domain_scores = self.domain_model(x_1_S_b_code)
x_2_S_a_domain_scores = self.domain_model(x_2_S_a_code)
x_2_S_b_domain_scores = self.domain_model(x_2_S_b_code)
mix_Q_a_domain_scores = self.domain_model(mix_Q_a_code)
mix_Q_b_domain_scores = self.domain_model(mix_Q_b_code)需要注意的是,域分类器输出的 shape 是 [1, 2]。按照前面说的,FC21a、FC22a 和 FC21b、FC22b 分别用来提取 domain-irrelevant features 和 domain-specific features。
先看可以轻易分出域的类别的 domain-specific features,即上面的 x_1_S_b_domain_scores、x_2_S_b_domain_scores 和 mix_Q_b_domain_scores。
loss_domain_CLS_1 = self.loss_fn(x_1_S_b_domain_scores, y_1_S_b)
loss_domain_CLS_2 = self.loss_fn(x_2_S_b_domain_scores, y_2_S_b)
loss_domain_CLS_mix = lamda*self.loss_fn(mix_Q_b_domain_scores, y_mix_b_1) + (1-lamda)*self.loss_fn(mix_Q_b_domain_scores, y_mix_b_2)
loss_domain_CLS = (loss_domain_CLS_1 + loss_domain_CLS_2 + loss_domain_CLS_mix)/3.0 这里的 loss_fn 就是交叉熵损失,可以看到这里又将 Mixed Query Set 的标签分为了两类 y_mix_b_1 和 y_mix_b_2,也是因为使用了 Mixup 的缘故。对应下列公式:

再看会让域分类器困惑的 domain-irrelevant features,也就是上面的 x_1_S_a_domain_scores、x_2_S_a_domain_scores、mix_Q_a_domain_scores。
loss_domain_fusion_1 = self.loss_KLD(F.log_softmax(x_1_S_a_domain_scores, dim=1), y_1_S_a)
loss_domain_fusion_2 = self.loss_KLD(F.log_softmax(x_2_S_a_domain_scores, dim=1), y_2_S_a)
loss_domain_fusion_mix = self.loss_KLD(F.log_softmax(mix_Q_a_domain_scores, dim=1), y_mix_a)
loss_domain_fusion = (loss_domain_fusion_1 + loss_domain_fusion_2 + loss_domain_fusion_mix)/3.0对应公式如下:

这里使用了 KL 散度作为损失函数,KL 散度损失可以缩小分布间的距离并且是使第一个带 log 的分布靠近第二个。KL 散度也称为相对熵,其公式如下,公式等号后的第一部分是变量 A 的熵,第二部分就是交叉熵。

对应到代码里 F.log_softmax(mix_Q_a_domain_scores, dim=1) 为上式中的 B,y_1_S_a 等为 A。
这里 y_1_S_a 为常数,所以变量 A 的熵为定值,在优化时与交叉熵的效果是一样的。不太理解为什么使用 KL 散度作为损失,完全可以跟上面一样使用交叉熵呀。
------------------------22.05.10
应该要从分布来解释,希望公式中交叉熵那一项学习到变量 A 的分布,而不是将其最小化为0。
至此完成一整个训练过程,最终的损失函数定义为:
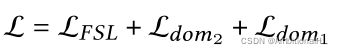
Experiment
Source Dataset 为 Mini-Imagenet,Target Dataset 为 CUB、Cars、Places 和 Plantae。



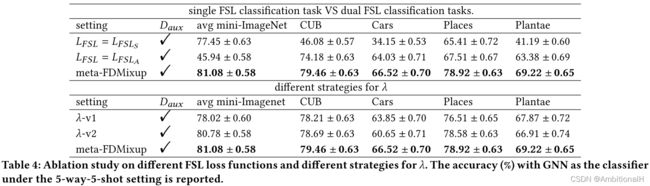
An interesting phenomenon is that the single task mechanism is inferior to our multi-task mechanism even on its goal dataset. This observation in turn indicates that our multi-task mechanism makes the source and the target datasets promote each other mutually.
For “λv1", if the value of λ is higher than 0.5, we adjust it to 0.5, which means we want to ensure more than half of the auxiliary data will be maintained in the mixed data.
Similarly, for “λ-v2", we set the λ to 0.5 if it is smaller than 0.5.
v1 保留更多的目标域数据,精度下降的原因是 mixed data 的多样性下降了。v2 保留更多的源域数据。
Baseline 是只在 mini-ImageNet 上训练的模型,Ours 是本文的方法。
Conclusion
这一篇和 FTW 的跨域学习的方法都用到了均值和方差,来模拟/提取跨域的特征。文章好多地方写的不清不楚,不看代码很难弄明白。这篇是自己看的第二篇 Cross Domain 的文章,第一篇是 FTW,有空补个笔记。使用源域数据和目标域数据 Mixup,提取 domain-irrelevant 特征和 domain-specific 特征,来强化最后的特征。
感觉自己踏进了 Cross Domain 的新手村...之前看的同一个域内小样本学习的文章似乎能跟这个结合一下,借着最近开题把之前看过的文章整理一下,加油吧。
论文笔记 | ACM MM 2021: Meta-FDMixup: Cross-Domain Few-Shot Learning Guided by Labeled Target Data - 知乎
GitHub - lovelyqian/Meta-FDMixup: Repository for the paper : Meta-FDMixup: Cross-Domain Few-Shot Learning Guided byLabeled Target Data
附加
- Domain Adaptation、Domain Generation、Cross Domain
对于前两者,现在大部分学者采用的定义是是否有目标域的数据可以拿来训练,如果有就是 Domain Adaptation,没有就是 Domain Generation,Cross Domain 跟前两个比起来更像一个动词。
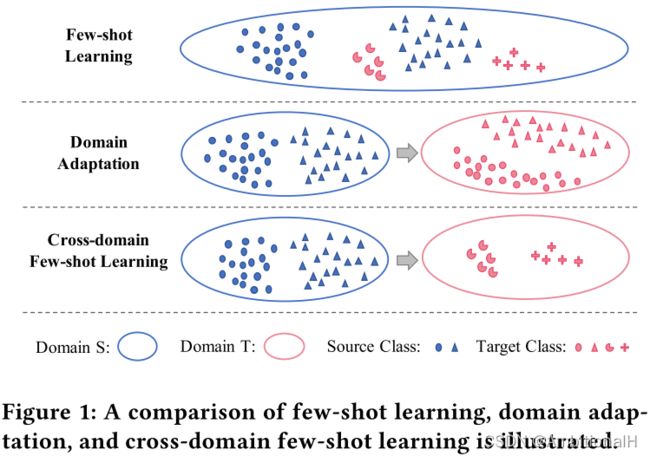
上图中 Domain Adaptation 源域和目标域的特征空间也可以部分重合。
- Mixup
将两张图像按一定比例逐像素相乘,得到输入到网络中的图像,模型的输出分别与两个 ground truth 计算损失,之后也按相同的比例处理后得到最终的损失。
# randperm返回1~images.size(0)的一个随机排列
index = torch.randperm(images.size(0)).cuda()
inputs = lam * images + (1 - lam) * images[index, :]
targets_a, targets_b = target, target[index]
outputs = model(inputs)
loss = lam * criterion(outputs, targets_a) + (1 - lam) * criterion(outputs, targets_b)