论文阅读:CROSS-DOMAIN FEW-SHOT CLASSIFICATION VIA LEARNED FEATURE-WISE TRANSFORMATION
论文:CROSS-DOMAIN FEW-SHOT CLASSIFICATION
VIA LEARNED FEATURE-WISE TRANSFORMATION
地址:https://arxiv.org/abs/2001.08735
代码:https://github.com/hytseng0509/CrossDomainFewShot
来源:ICLR2020
摘要
由于不同领域的数据特征分布具有差异性,因此少样本分类算法对于之前为见过的领域数据效果不好。次论文主要解决的是基于度量的方法在领域迁移(domain shift)问题下的少样本分类任务。核心思想是提出了一个feature-wise transformation layer ,在训练阶段通过仿射变换增强图像特征来模拟不同领域中的特征分布。为了捕获不同领域中的特征分布,又使用了learning-to-learn的方法来搜索fearure-wise transofrmation layer中的超参数。实验数据集:mini-ImageNet,CUB, Cars, Places, and Plantae.
问题
domain shift
基于度量的方法通常包含两个部分:特征编码器和度量函数。通常的方法对于训练集和测试集都是在同意领域的数据,比如都是miniImageNet中的数据,因此他们的数据分布都差不多。但是我们如果想测试其他领域的数据,比如CUB数据,因为数据分布差距较大,因此效果也较差。
如上图所示,寻来拿阶段用的是miniImageNet中的一部分,在miniImageNet中另一部分测试时,因为他们的数据分布差不多,每类之间的差距都较大,所以效果可以,但是在CUB和Cars测试,他们都是鸟类或这汽车的数据,因此数据分布接近,这时之前训练的度量函数效果就不好了。
解决domain shift的主要方法:1)无监督的领域自适应(unsupervised domain adaptation),这种放方法在训练阶段会使用目标域中的无标签数据。 2)领域泛化(domain generalization),学习一个分类器,使他在目标域中有足够好的泛化性,但是这种方法目的是识别与训练阶段相同类型的数据。
方法
基于度量的方法
基于度量的方法通常包含两个部分:特征编码器 E E E和度量函数 M M M。
![]()
E E E为特征编码器,本别对support set X s \mathcal{X_s} Xs和query set X q \mathcal{X_q} Xq进行编码,然后通过度量函数 M M M实现分类。

最后根据loss反向传播计算参数。
问题设置
一个领域包含多个任务 T = { T 1 , T 2 , … , T n } \mathcal{T} = \{T_1,T_2,\dots,T_n\} T={T1,T2,…,Tn},我们假设在训练阶段可以看到N个领域 { T 1 s e e n , T 2 s e e n , … , T N s e e n } \{\mathcal{T}_1^{seen},\mathcal{T}_2^{seen},\dots,\mathcal{T}_N^{seen}\} {T1seen,T2seen,…,TNseen}。目标是使我们的模型在目标域 T u n s e e n \mathcal{T}^{unseen} Tunseen有足够好的效果。
Feature-wise transformation layer
为了解决度量函数 M M M在可视域上过拟合,作者提出了Feature-wise transformation layer,加在了在特征编码器 E E E的最后,通过放射变化来增强特征的表示。因此可以处理不同的特征分布从而提升了度量函数 M M M的泛化性。
作者将变换层插入到Feature Encoder 的BN层之后。变换层的两个超参数 θ γ ∈ R C × 1 × 1 \theta_\gamma \in R^{C\times1\times1} θγ∈RC×1×1和 θ β ∈ R C × 1 × 1 \theta_\beta \in R^{C\times1\times1} θβ∈RC×1×1代表的是用来从中采样affine变换参数的一个高斯分布的标准差。
![]()
给定Feature Encoder的一个 C × H × W C\times H \times W C×H×W大小的特征图 z \mathbf{z} z,首先从高斯分布在采样scaling项 γ \gamma γ 和bias项 β \beta β,然后根据公式对 z \mathbf{z} z进行调整。
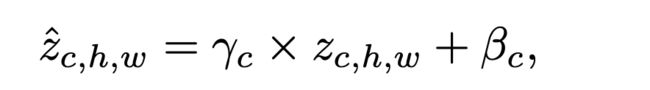
实际上作者在多层中都插入了此结构。
Learning the Feature-wise Transformation Layer
θ f = { θ γ , θ β } \theta_f = \{\theta_\gamma,\theta_\beta\} θf={θγ,θβ}是feature-wise transformation layer的超参数,我们之前通常是根据经验手动设置这个超参数,这里论文提出了learning-to-learn的算法来优化参数。
在每一次训练迭代t,我们从 { T 1 s e e n , T 2 s e e n , … , T N s e e n } \{\mathcal{T}_1^{seen},\mathcal{T}_2^{seen},\dots,\mathcal{T}_N^{seen}\} {T1seen,T2seen,…,TNseen}随机抽取一个作为pseudo-seen域 T p s \mathcal{T}^{ps} Tps,和一个pseudo-unseen域 T p u \mathcal{T}^{pu} Tpu。给定一个metric-based模型,特征编码器为 E θ e t E_{\theta_e^t} Eθet,距离度量函数为 M θ m t M_{\theta_m^t} Mθmt,首先将超参数为
θ f = { θ γ , θ β } \theta_f = \{\theta_\gamma,\theta_\beta\} θf={θγ,θβ}的Feature-wise transformation layer插入到特征编码器 E θ e t , θ f t E_{\theta_e^t,\theta_f^t} Eθet,θft中。使用pseudo-seen task T p s = { ( X s p s , Y s p s ) , ( X q p s , Y q p s ) } ∈ T p s T^{ps}=\{(\mathcal{X}_s^{ps},\mathcal{Y}_s^{ps}),(\mathcal{X}_q^{ps},\mathcal{Y}_q^{ps})\} \in \mathcal{T}^{ps} Tps={(Xsps,Ysps),(Xqps,Yqps)}∈Tps结合公式(2)更新metric-based模型中的参数。具体公式如下所示。
![]()
然后使用更新的模型来测试泛化性。首先移除feature-wise transformation layer,然后计算在 pseudo-unseen task T p u = { ( X s p u , Y s p u ) , ( X q p u , Y q p u ) } ∈ T p u T^{pu} = \{(\mathcal{X}_s^{pu},\mathcal{Y}_s^{pu}),(\mathcal{X}_q^{pu},\mathcal{Y}_q^{pu})\} \in \mathcal{T}^{pu} Tpu={(Xspu,Yspu),(Xqpu,Yqpu)}∈Tpu上计算loss。根据下式。
![]()
最后根据loss 来更新参数 θ f \theta_f θf:

算法如下图所示。

实验
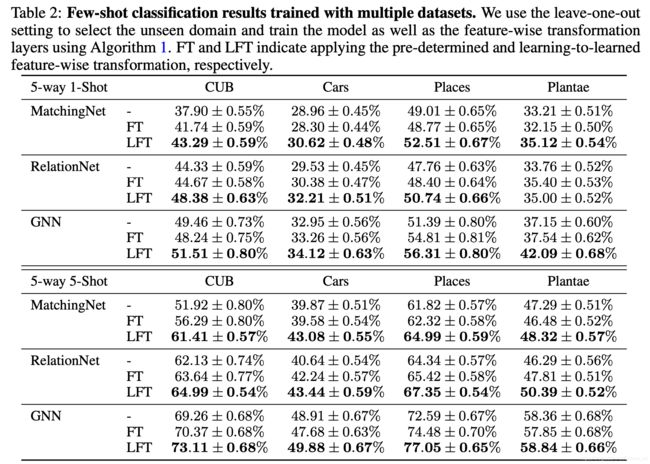
在实验阶段,作者先在miniImageNet中的64类数据进行了预训练,这样可以取得较好的效果。实验主要分为两种情况:1)仅仅使用miniImageNet作为seen domain,然后其他的四个数据集分别作为unseen doman进行试验。2)采用留一法,在其他四个数据集中分别选一个作为unseen domain,然后让其他的和miniImageNet作为seen domain。baseline 为MatchingNet、RelationNet和GNN。
Training on mini-ImageNet domain and evaluate on different domains
FT代表添加了feature-wise transformation layer,超参数是根据经验手动设置的,论文中作者提出的是 θ γ = 0.3 , θ β = 0.5 \theta_\gamma=0.3,\theta_\beta=0.5 θγ=0.3,θβ=0.5。
LFT代表使用leading-to-learn的方法自动学习超参数。

leave-one-out setting
visualization
下图是对特征分布的可视化,如图所示,添加了feature-wise transformation layer之后的不同领域的特征分布距离更接近了。
下图是对learning-to-learn部分的 θ γ 和 θ β \theta_\gamma和\theta_\beta θγ和θβ的可视化,可以看出后边的层中的 θ γ \theta_\gamma θγ在逐渐变小, θ β \theta_\beta θβ基本没有变化。

参考
《Cross-Domain Few-Shot Classification》笔记