机器学习【系列】之第一章线性回归模型
机器学习【系列】之第一章线性回归模型
第一章 Python 机器学习入门之线性回归模型
文章目录
- 机器学习【系列】之第一章线性回归模型
- 前言
- 一、线性回归算法
-
- 1.一元线性回归
- 二、线性回归的代码实现
-
- 1.一元线性回归的代码实现
- (1)绘制散点图
- (2)引入Scikit-Learn库搭建模型
- (3)模型预测
- (4)模型可视化
- (5)线性回归方程构造
- 2.案例实战:不同行业工龄与薪水的线性回归模型
- (1)读取数据
- (2)模型搭建+数据可视化
- (3)线性回归方程构造
- (4)模型优化
- 三、线性回归模型评估
-
- 1.模型评估的编程实现
- 2.案例实战:客户价值预测模型
- 总结
前言
机器学习涉及的知识面很广,但总的来说有两条主线,一条主线是问题,另一条主线是模型。机器学习看起来无话八门,但总的来说主要分为监督学习和无监督学习两大类。
在线性回归中,我们根据特征表列(也称自变量)来预测反应变量(也称因变量)。根据特征变量的个数可将线性回归模型分为一元线性回归和多元线性回归。例如,通过“工龄”这一特征变量来预测“薪水”,就属于一元线性回归;而通过“工龄”“行业”“所在城市”等多个特征变量来预测“薪水”,就属于多元线性回归。
提示:以下是本篇文章正文内容,下面案例可供参考
一、线性回归算法
1.一元线性回归
对于一个线性回归问题,也就是说,这里的“神秘方程”就是一个线性方程,相应的数据集点也一定是根据线性排布的,那么,我们要做的就是不断调整线性方程的两个按钮,作出一条能够一一通过这些点的直线,也就是拟合。这个能够拟合数据集点的线性方程,就是我们要找的“神秘方程”。
二、线性回归的代码实现
1.一元线性回归的代码实现
(1)绘制散点图
import matplotlib.pyplot as plt
X = [[1],[2],[4],[5]]
Y = [2,4,6,8]
plt.scatter(X,Y)
plt.show()
(2)引入Scikit-Learn库搭建模型
# 从Scikit-Learn库引入线性回归的相关模块LinearRegression
from sklearn.linear_model import LinearRegression
# 构造一个初始的线性回归模型并命名为regr
regr = LinearRegression()
# 用fit()函数完成模型搭建,此时的regr就是一个搭建好的线性回归模型
regr.fit(X,Y)
(3)模型预测
# 那么使用predict()函数就能预测对应的因变量y
y = regr.predict([[1.5],[2.5],[4.5]])
# 预测结果如下:
[2.9 4.3 7.1]
(4)模型可视化
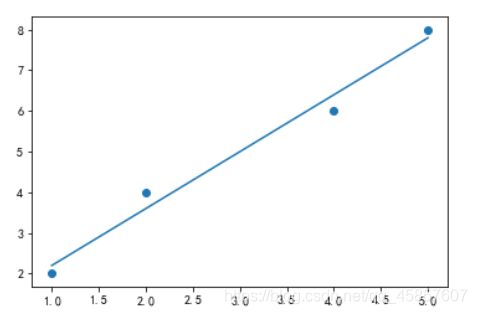
plt.scatter(X,Y)
plt.plot(X,regr.predict(X))
# 其中的原理就是最小二乘法
plt.show()
(5)线性回归方程构造
print("系数a: "+str(regr.coef_[0]))
print("截距b: "+str(regr.intercept_))
# 运行结果如下:
系数a: 1.4
截距b: 0.8
# 拟合得到的一元线性回归方程为 y = 1.4x + 0.8.
2.案例实战:不同行业工龄与薪水的线性回归模型
代码如下(示例):
(1)读取数据
from sklearn import linear_model
from matplotlib import pyplot as plt
import pandas as pd
df = pd.read_excel('IT行业收入表.xlsx')
X = df[["工龄"]]
Y = df[["薪水"]]
plt.rcParams["font.sans-serif"] = ["SimHei"] #用来显示中文标签
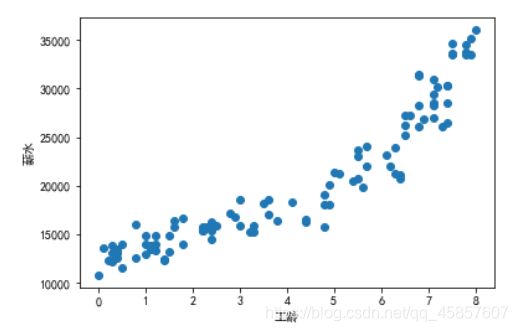
plt.scatter(X,Y)
plt.xlabel("工龄")
plt.ylabel("薪水")
plt.show()
(2)模型搭建+数据可视化
model = linear_model.LinearRegression()
model.fit(X,Y)
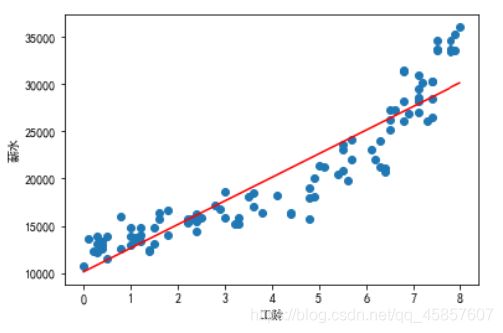
plt.scatter(X,Y)
plt.plot(X,model.predict(X),color="red") # color="red"表示用红色绘制趋势线
plt.xlabel("工龄")
plt.ylabel("薪水")
plt.show()
(3)线性回归方程构造
print("系数a: ",str(model.coef_[0]))
print("截距b: ",str(model.intercept_))
# 结果如下:
系数a: [ 2497.1513476]
截距b: [ 10143.13196687]
(4)模型优化
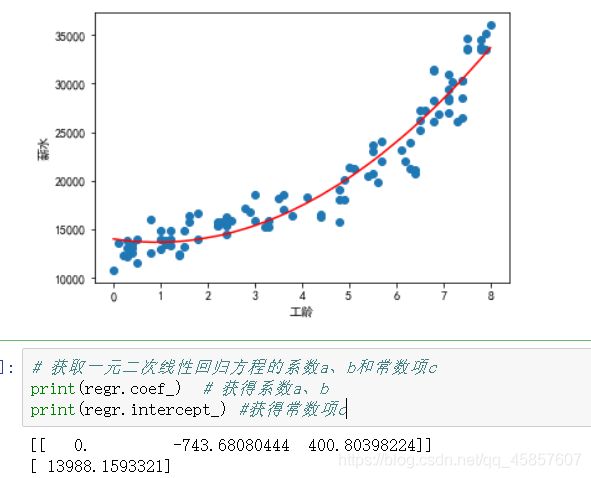
一元线性回归模型还有一个进阶版本 :一元多次线性回归模型,比较常见的是一元二次线性回归模型,其形式可以表示为如下所示的公式: y = ax2+bx+c
# 用于增加一个多次项内容的模块PolynomialFeatures
from sklearn.preprocessing import PolynomialFeatures
# 设置最高项伟二次项,为生成二次项数据(x2)做准备
ploy_reg = PolynomialFeatures(degree=2)
# 生成一个新的二维数组X_
X_ = ploy_reg.fit_transform(X)
ploy_reg = PolynomialFeatures(degree=2)
X_ = ploy_reg.fit_transform(X)
regr = linear_model.LinearRegression()
regr.fit(X_,Y)
plt.scatter(X,Y)
plt.plot(X,regr.predict(X_),color="red")
plt.xlabel("工龄")
plt.ylabel("薪水")
plt.show()
三、线性回归模型评估
1.模型评估的编程实现
模型搭建完成后,还需要对模型进行评估,这里主要以3个值作为评判标准:R-squared(即统计学中的R的平方)、Adj.R-squared(即Adjusted R的平方)、P值。其中R-squared和Adj.R-squared用来衡量线性拟合的优劣,P值用来衡量特征变量的显著性。
import statsmodels.api as sm
X2 = sm.add_constant(X)
est = sm.OLS(Y,X2).fit()
print(est.summary())

R-squared和Adj.R-squared的取值范围为0–1,它们的值越接近1,则模型的拟合程度越高;P值在本质上是个概率值,其取值范围也为0–1,P值越接近1,则特征变量的显著性越高,即该特征变量真的和目标变量具有相关性。
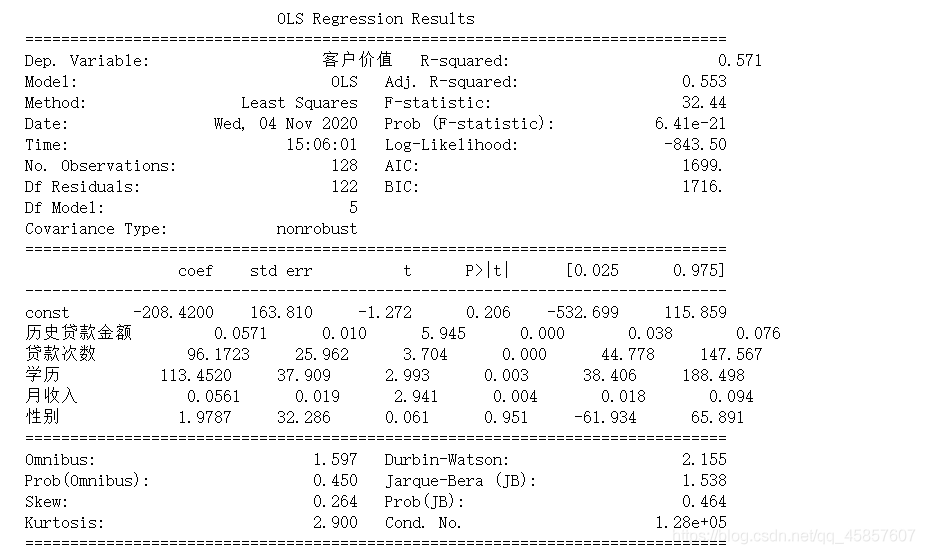
2.案例实战:客户价值预测模型
import pandas as pd
df2 = pd.read_excel('客户价值数据表.xlsx')
df2.head()
X = df2[["历史贷款金额","贷款次数","学历","月收入","性别"]]
Y = df2["客户价值"]
from sklearn.linear_model import LinearRegression
regr = LinearRegression()
regr.fit(X,Y)
print("各系数: "+str(regr.coef_))
print("常系数k0:"+str(regr.intercept_))
import statsmodels.api as sm
X2 = sm.add_constant(X)
est = sm.OLS(Y,X2).fit()
print(est.summary())
总结
这里对文章进行总结:
以上就是今天要讲的内容,本文仅仅简单介绍了线性回归模型和简单进行了案列实战。
参考书籍:《Python大数据分析与机器学习商业案例实战》