Spark MLlib 源码学习---线性回归模型(LinearRegression)
线性回归是机器学习中最常见的一种回归模型,也是入门机器学习的一种经典模型。线性回归假设因变量与自变量之间呈线性关系,当只有单一自变量的时候,称之为一元线性回归。当有多个自变量的时候,则为多元线性回归。线性回归模型的训练过程是通过训练数据集来确定每个自变量/特征的系数的过程。常用的训练算法有最小二乘法(Least Squares)以及基于最优化理论的梯度下降法(Gradient Descent)、牛顿法(Newton’s method)、拟牛顿法(Quasi-Newton Methods)等。这里我们主要分析的梯度下降以及拟牛顿法中的L-BFGS算法。如果在线性回归的损失函数中添加L1或L2正则化,则可以得到Lasso回归和Ridge回归。当然也可以同时考虑L1和L2正则化,也就是ElasticNet回归。Spark ML/MLlib中均实现了线性回归与添加了正则化项的各种变体。下面来具体看下Spark中线性回归的实现。
0. 线性回归基本原理
模型: y = w T x + b y=w^Tx+b y=wTx+b
其中, x = ( x 1 , x 2 , x 3 , . . . , x n ) , x ∈ R n x=(x_{1},x_{2},x_{3},...,x_{n}), x \in R^{n} x=(x1,x2,x3,...,xn),x∈Rn表示 n n n维特征向量。 w = ( w 1 , w 2 , w 3 , . . . , w n ) , w ∈ R n w=(w_{1},w_{2},w_{3},...,w_{n}),w \in R^{n} w=(w1,w2,w3,...,wn),w∈Rn对应上面每一个特征的权重,也称回归系数。 b ∈ R b \in R b∈R表示偏置项。可以很清晰得看出,线性回归模型的预测结果是通过特征与其对应权重的内积再加上偏置项得到的,也就是特征之间的线性组合的结果。特征权重可以表征每一个特征的重要性,具有较好的解释性,因此很多回归的工程问题都可以用线性回归模型做为baseline。
损失函数: L o s s ( w , b ) = 1 2 N ∑ i = 1 N ( y i − y ^ i ) 2 = 1 2 N ∑ i = 1 N ( y i − ∑ j = 1 M w j x j − b ) 2 Loss(w,b)=\frac{1}{2N}\sum_{i=1}^N(y_{i}-\hat y_{i})^2 =\frac{1}{2N}\sum_{i=1}^N(y_{i}-\sum_{j=1}^Mw_{j}x_{j}-b)^2 Loss(w,b)=2N1∑i=1N(yi−y^i)2=2N1∑i=1N(yi−∑j=1Mwjxj−b)2
对于线性回归模型,常用上面的均方误差(Square Error)作为模型的损失函数,训练模型就是确定 w w w和 b b b这两个超参数,一旦确定了这两个超参,那么模型就被确定下来,可以用于实际的预测工作。想要确定超参,首先我们需要定义损失函数,比较直观的,可以用均方误差作为线性回归的损失函数,这也非常符合常识,即预测结果越接近真实值,那么函数拟合得越好,使用中预测得也就越准确。从上述解析式中可以看到, L o s s Loss Loss的物理含义是所有训练数据的预测值与真实值的误差的平方和的均值(严格来说去掉常数1/2,为了方便后续计算保留)。我们的目标其实是最小化该误差,即求取 min L o s s ( w , b ) \min Loss(w,b) minLoss(w,b)。
算法: 凸优化问题,使用梯度下降法或者牛顿法。以梯度下降法为例
w n + 1 = w n − η ∗ ∂ L o s s ( w n , b ) ∂ w n w_{n+1}=w_{n}-\eta*\frac{\partial Loss(w_{n},b)}{\partial w_{n}} wn+1=wn−η∗∂wn∂Loss(wn,b)
= w n − η ∗ 1 N ∗ ∑ i = 1 N ( − x i ) ∗ ( y l a b e l i − w n T x i − b ) w_{n}-\eta*\frac{1}{N}*\sum_{i=1}^N(-x_{i})*(y_{label_{i}}-w_{n}^Tx_{i}-b) wn−η∗N1∗∑i=1N(−xi)∗(ylabeli−wnTxi−b)
b n + 1 = b n − η ∗ ∂ L o s s ( w , b ) ∂ b b_{n+1}=b_{n}-\eta*\frac{\partial Loss(w,b)}{\partial b} bn+1=bn−η∗∂b∂Loss(w,b)
= b n − η ∗ 1 N ∗ ( − 1 ) ∗ ∑ i = 1 N ( y l a b e l i − w n T x i − b ) b_{n}-\eta*\frac{1}{N}*(-1)*\sum_{i=1}^N(y_{label_{i}}-w_{n}^Tx_{i}-b) bn−η∗N1∗(−1)∗∑i=1N(ylabeli−wnTxi−b)
我们使用迭代的方法求解超参数 w w w和 b b b。对于梯度下降法,迭代关系为 w k + 1 = w k − η ∗ ∂ L ∂ w k w_{k+1}=w_{k}-\eta*\frac{\partial L}{\partial w_{k}} wk+1=wk−η∗∂wk∂L
那么我们可以推导出上述 w w w和 b b b的迭代关系,其中 η \eta η代表学习率或者叫做步长。既然是迭代算法,必须要有迭代停止的条件。一般可以通过设置最大迭代次数或者迭代误差小于某一阈值的时候来停止迭代。
1. 简单入门案例
这里举个二元线性回归的例子: y = w 1 ∗ x 1 + w 2 ∗ x 2 + b , w ∈ R 2 , b ∈ R y = w_{1} * x_{1}+w_{2}*x_{2} + b, w \in R^2, b \in R y=w1∗x1+w2∗x2+b,w∈R2,b∈R
这里有两个自变量 x 1 x_{1} x1和 x 2 x_{2} x2,因变量 y y y是关于这两个自变量的线性组合。这里假设 w 1 = 1.0 , w 2 = 2.0 , b = 3.0 w_{1}=1.0,w_{2}=2.0,b=3.0 w1=1.0,w2=2.0,b=3.0。同时我们随机选取一些 x 1 x_{1} x1和 x 2 x_{2} x2的取值,就可以计算 y y y的值。下图就给出一些 x 1 x_{1} x1、 x 2 x_{2} x2和 y y y的样例数据。
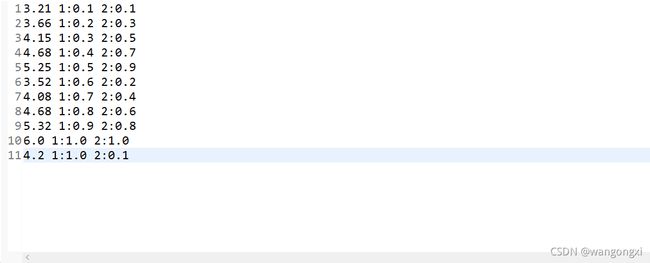
样例数据的格式已经调整为了libsvm的格式。第一列是标签的值,也就是 y y y的取值,后面两列分别是 x 1 x_{1} x1和 x 2 x_{2} x2的取值,也就是两个特征的取值。
我们考虑一个问题:如果我们只有上面截图中的这11条数据,但不清楚 w 1 w_{1} w1、 w 2 w_{2} w2还有 b b b的取值,那么是否可以通过建模的方式来计算这三个参数。也就是说,我们的目的是通过这些已知的离散点来确定线性回归方程中的回归系数和偏置两个参数。
事实上由于这些样本是 w 1 = 1.0 w_{1}=1.0 w1=1.0、 w 2 = 2.0 w_{2}=2.0 w2=2.0以及 b = 3.0 b=3.0 b=3.0的条件下产生的,因此理想情况下使用线性回归模型进行建模并训练后,三个参数会接近于事先的给定值。下面给定使用Spark ML实现上述过程。
object LinearRegressionExample{
def main(args : Array[String]) : Unit = {
val spark = SparkSession.builder().appName("Linear Regression Example").getOrCreate()
spark.sparkContext.setLogLevel("INFO")
//加载训练数据
val training : DataFrame = spark.read.format("libsvm").load("linear_regression_train_data.txt")
val lr : LinearRegression = new LinearRegression()
.setFitIntercept(true) //是否使用偏置项参数
.setLoss("squaredError") //损失函数,这里使用均方误差
.setSolver("l-bfgs") //优化算法,这里使用l-bfgs
.setStandardization(true) //训练数据标准化
.setMaxIter(100) //最大的迭代次数,作为算法停止的其中一个条件
.setTol(1E-6) //收敛阈值,默认为1e-6,这里沿用默认值
.setRegParam(0.0) //正则化项系数值
.setElasticNetParam(1.0) //选择L1/L2/L1&L2正则化,默认值为0,即为L2正则化,1.0为L1正则化,0~1之间实数值表示L1&L2正则化都考虑
//模型训练
val lrModel = lr.fit(training)
//打印超参数
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
}
}
先解释下上面的这段逻辑。首先声明一个Spark应用的上下文,然后读取libsvm格式的训练数据,也就是上面提到的一共11条的样本数据。接下来声明一个线性回归模型的实例,并设置模型的相关参数。在代码的注释中已经做了解释,这里就不再多做说明了。需要额外说明的地方有两处,一个是损失函数,在上面代码中使用的是均方误差,也是默认的损失函数,此外Spark中还支持Huber Loss,可以用“huber”关键字来设置。另一处则是优化算法,上面我们使用的是L-BFGS算法,是线性回归中默认的优化算法,也是常用的拟牛顿优化算法。此外Spark中还支持使用正规方程法(最小二乘法)求解参数,若要使用该算法则需要设置参数关键字为"normal"。如果关键字设置为"auto",那么模型会自动选择优化算法。为了便于下面说明源码的实现,这边统一使用上面配置的模型参数进行说明。最后来看下结果。
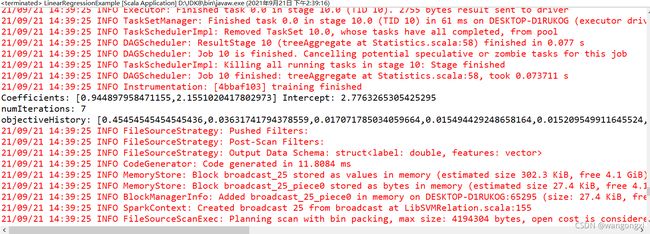
截图中打印了三行用户日志,主要是关于两个回归系数的值以及偏置项的值,还有总迭代次数以及每次迭代后的损失函数的值,从数值上可以明显看出,损失函数的值是在不断下降的,也就是说模型在逐步的收敛。最后两次的损失函数值的误差间隔已经小于1E-6,所以模型停止了迭代,训练也就结束了。
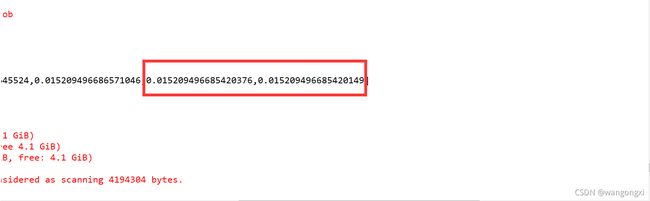
从模型停止迭代后,可以看到两个回归系数分别为0.9和2.1,偏置项为2.77,这同设置的各个参数的值是比较接近的,整体模型拟合的效果较好,是符合我们的预期的。下面来分析下它的源码实现。
2. Spark源码实现分析
在分析线性回归在Spark中的实现之前,有必要先介绍下Spark依赖的张量计算库Breeze。Breeze是基于Scala的数学计算框架,集成了常见的矩阵计算操作以及优化算法。它类似于Deeplearning4j生态中ND4J,底层同样可以使用OpenBLAS/MKL等库进行加速。在breeze.optimize包路径中,有如下类继承关系图
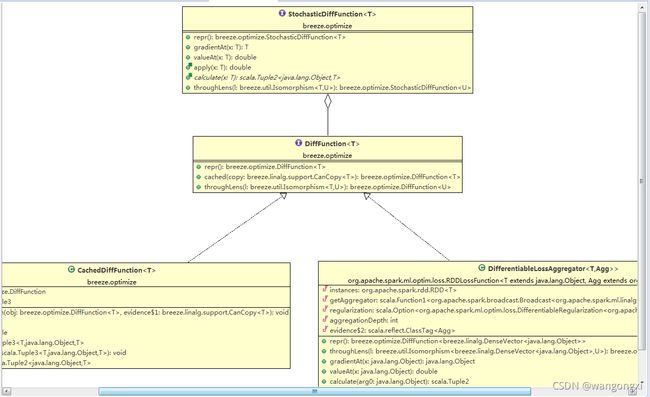
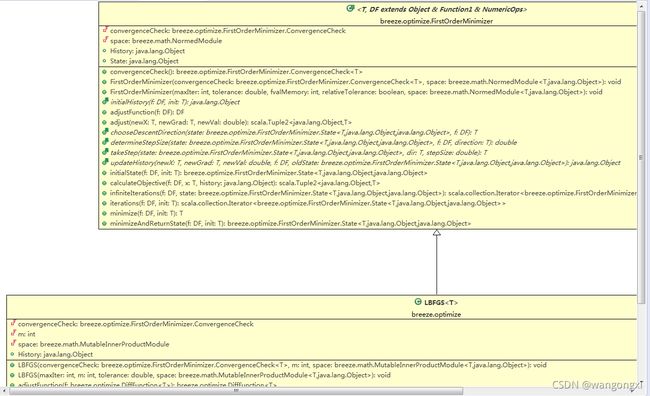
从截图中可以看到,LBFGS类继承了抽象类FirstOrderMinimizer并覆写了initialHistory、chooseDescentDirection和determineStepSize等方法。在FirstOrderMinimizer抽象类中核心的方法有两个:initialState和initialState。initialState用于初始化算法的状态,并将初次计算后的梯度与损失函数值记录State实例对象中,紧接着就会调用infiniteIterations方法进行模型的迭代计算
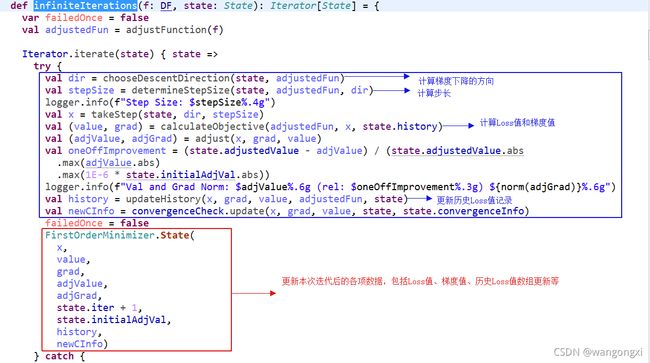
上面截图中给出了继承FirstOrderMinimizer的优化算法迭代方法的实现过程。在分析LBFS实现的之前,先简单回顾下牛顿法。考虑不带正则化项约束的损失函数,对其进行泰勒级数展开到二阶,令损失函数的导数为0求取极值,则经过变换后可以得到下面的迭代公式:
ω k + 1 = ω k − f ′ ( ω k ) f ′ ′ ( ω k ) \omega_{k+1}=\omega_{k}-\frac{f^{'}(\omega_{k})}{f^{''}(\omega_{k})} ωk+1=ωk−f′′(ωk)f′(ωk)
这是对于单一参数而言,改写成矩阵形式后则有
ω k + 1 = ω k − H k − 1 g k \omega_{k+1}=\omega_{k}-H^{-1}_{k}g_{k} ωk+1=ωk−Hk−1gk
这里的 g k g_{k} gk表示损失函数对参数的一阶偏导向量, H k − 1 H^{-1}_{k} Hk−1则表示二阶偏导矩阵,也就是所谓的海塞矩阵的逆矩阵。原始牛顿法的步长是固定的,这可能导致模型发散,因此在改进的组尼牛顿法中基于一维线性搜索算法计算步长因子,可得到
ω k + 1 = ω k − t ∗ H k − 1 g k \omega_{k+1}=\omega_{k}-t*H^{-1}_{k}g_{k} ωk+1=ωk−t∗Hk−1gk
牛顿法的缺点在于海塞矩阵的逆矩阵的计算代价巨大,因此考虑近似的计算方法是必然的,拟牛顿法的核心思想是不基于二阶偏导的计算构建海塞矩阵或其逆矩阵的近似正定对称矩阵。对于此问题,主流的方案有BFGS算法以及DFP算法等。这里给出BFGS算法中海塞矩阵的近似计算。
H k + 1 = H k + y y T y T s − H k s s T H k s T H k s , s = ω k + 1 − ω k , y = g k + 1 − g k H_{k+1}=H_{k}+\frac{yy^T}{y^Ts}-\frac{H_{k}ss^TH_{k}}{s^TH_{k}s},s=\omega_{k+1}-\omega_{k},y=g_{k+1}-g_{k} Hk+1=Hk+yTsyyT−sTHksHkssTHk,s=ωk+1−ωk,y=gk+1−gk
海塞矩阵逆矩阵的迭代公式
H k + 1 − 1 = ( I − s y T y T s ) H k − 1 ( I − y s T y T s ) + s s T y T s H^{-1}_{k+1}=(I-\frac{sy^T}{y^Ts})H^{-1}_{k}(I-\frac{ys^T}{y^Ts})+\frac{ss^T}{y^Ts} Hk+1−1=(I−yTssyT)Hk−1(I−yTsysT)+yTsssT
BFGS算法需要存储 H k H_{k} Hk这样一个 N ∗ N N*N N∗N的矩阵或者它的逆矩阵,空间复杂度为 O ( N ∗ N ) O(N*N) O(N∗N),即使考虑它的对称性将存储降为原先的一半,复杂度依然没有降低,依然非常可观,因此进一步优化点在于是否可以不存储这样的矩阵也可以完成上面的迭代计算,L-BFGS的提出提供了一种有效的解决方案。对于L-BFGS算法,我们假定初始的近似的海塞矩阵是单位矩阵,即 H 0 = I H_{0}=I H0=I,并且我们存储最近的 m m m个 s s s和 y y y向量,则基于上面的迭代公式我们可以递归地计算得到 H k + 1 H_{k+1} Hk+1或者 H k + 1 − 1 H^{-1}_{k+1} Hk+1−1。实际工程落地的时候, m m m的值一般取个位数就有较好的结果,如Breeze中L-BFGS算法的实现中 m m m一般取3~7之间。
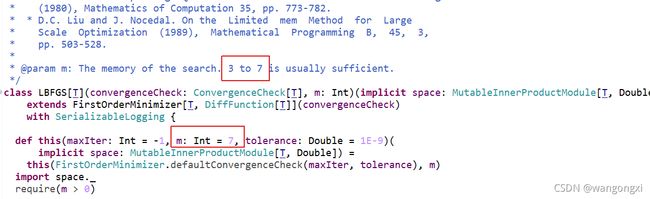
L-BFGS对于BFGS的近似求解使得存储的复杂度下降到了 O ( m ∗ N ) O(m*N) O(m∗N), m m m是一个相对小的数值,当特征的数量越大,也就是 m < < N m<
线性回归模型训练过程的实际入口方法是LinearRegression.train(dataset: Dataset[_]): LinearRegressionModel

首先计算了特征的数量,然后根据特征的数量以及用户设置的损失函数选择实际使用的优化算法。对于用户设置了“normal”或者设置成了"auto"且特征数量小于4096则会使用最小二乘法进行参数计算。由于我们关注的主要是L-BFGS优化算法,因此这里调用trainWithNormal方法进行最小二乘计算细节这里不做展开。接着往下看。
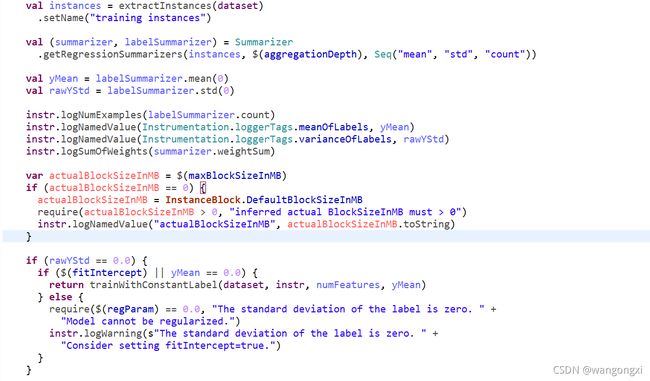 这部分逻辑处理主要有三个部分,从DataSet/DataFrame中抽取特征、标注以及样本权重这些列并封装到Instance的实例对象中。分别计算标注、特征的均值、标准差和总数。随后计算了实际每个block中 instance的集合占用的内存阈值。对于标注如果是一个常数的特殊情况,ML中会做简化的计算处理。从判断逻辑中可以看出,标注的标准差值为0是常数标注的充分条件,进一步判断标注的均值是否为0或者设置了偏置项,满足其中一个则构成了充分必要条件,就会按照常数标注进行模型参数的计算。对于标注均值也是0的情况,那么回归系数和偏置项必然等于0。如果标注均值不等于0,那么偏置项就等于标注的均值,回归系数均等于0。具体实现逻辑可以看下L464-L495。至于Instance实例占用的内存大小的限制,主要是后面在批量计算梯度和Loss值的时候会先吧每个Instance合并成InstanceBlock对象,由于不可能把每个分区中的Instance直接合并成一个大的InstanceBlock,因此会根据每个block内存占用阈值来限制block中Instance实例的数量。这个后面也会谈到。
这部分逻辑处理主要有三个部分,从DataSet/DataFrame中抽取特征、标注以及样本权重这些列并封装到Instance的实例对象中。分别计算标注、特征的均值、标准差和总数。随后计算了实际每个block中 instance的集合占用的内存阈值。对于标注如果是一个常数的特殊情况,ML中会做简化的计算处理。从判断逻辑中可以看出,标注的标准差值为0是常数标注的充分条件,进一步判断标注的均值是否为0或者设置了偏置项,满足其中一个则构成了充分必要条件,就会按照常数标注进行模型参数的计算。对于标注均值也是0的情况,那么回归系数和偏置项必然等于0。如果标注均值不等于0,那么偏置项就等于标注的均值,回归系数均等于0。具体实现逻辑可以看下L464-L495。至于Instance实例占用的内存大小的限制,主要是后面在批量计算梯度和Loss值的时候会先吧每个Instance合并成InstanceBlock对象,由于不可能把每个分区中的Instance直接合并成一个大的InstanceBlock,因此会根据每个block内存占用阈值来限制block中Instance实例的数量。这个后面也会谈到。
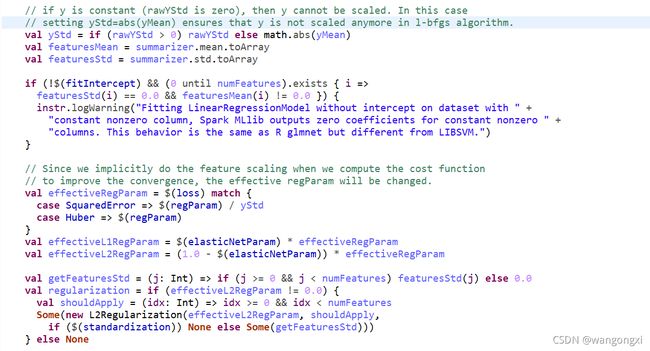
上面的这部分主要是对于正则化项的处理。首先对于标注的原始标准差如果存在等于0的情况,则令标注的均值代替标准差。做这一步操作的原因主要是后面会对标注值和特征值做统一的标准化处理,这样是为了防止分母等于0的情况。**需要注意的是,无论开发人员在设置超参数的时候设置是否需要做标准化,在实际内部处理的时候都会默认做标准化处理,目的是为了使得模型更好得收敛,这也是要事先计算标注和特征均值和标准差的原因,当然如果用户设置标准化参数为false,那么最后会做数值的还原。**接着,对于没有设置偏置项但是存在特征中有均值不等于0却方差等于0的不合理情况,会打印warning日志出来,这会导致回归系数为0结果,当然实际场景中这种情况并不常见。接着这段逻辑比较明显,就是根据不同的损失函数调整正则化系数的大小,得到所有真正有效的正则化系数,也就是所谓的effectiveRegParam。随后基于effectiveRegParam计算有效的L1和L2正则化系数。由于参数elasticNetParam的设置决定了到底是采用哪一种正则化项亦或者两者同时采用,因此这里根据elasticNetParam的实际值来计算L1和L2正则化系数的实际值。如果实际值等于0,那么其实也就不考虑该正则化项了。最后声明了L2正则化项的对象,其中封装了对特征标准化值计算的函数对象。下面看下整个训练过程。

createOptimizer方法创建了优化器,具体的是breeze.optimize.LBFGS实现类。接着初始化了每个回归系数的值为0。trainImpl方法中则是实现了训练的实现细节。先看下其中的第一部分。

在第一部分中,首先将特征的均值和标准差两份统计数据通过创建广播变量的方式分发到各个执行节点,然后对于每一个样本中的特征值除以该位特征的标准差。在第一部分的最后将RDD[Instance]转化为RDD[InstanceBlock]。InstanceBlock实例对象内部通过Matrix对象存储多个样本的特征,上面也有提到这个Matrix的大小需要考虑内存的大小,因此在堆叠Instance实例的过程中会校验总的内存大小是否已经超过阈值,一旦超过阈值则停止。下面看下第二部分。

第二部分主要定义了损失函数并将该函数对象以及回归系数初始化值作为入参调用优化器的迭代方法进行模型参数的迭代计算。在上面介绍FirstOrderMinimizer.infiniteIterations的方法时,在截图中已经对每一步的操作做了说明。其中calculateObjective方法的调用目的是计算本轮迭代的Loss值和梯度,实际在该方法内部会调用DiffFunction的子类(也就是这张截图中的RDDLossFunction类)的calculate方法。我们来看下calculate方法的实现。

calculate方法内部实际并没有直接计算梯度和Loss值,而是通过DifferentiableLossAggregator的实现类来计算,也就是上一张截图中BlockLeastSquaresAggregator对象。calculate方法的目的是主要是聚合每个Instance或者InstanceBlock实例计算得到的Loss值以及梯度值。那么我们来看下BlockLeastSquaresAggregator类中计算Loss和梯度的细节。在具体看代码实现逻辑之前,我们先对做了标准化的原始特征和标注做一下转换。
L o s s ( ω ) = 1 2 N ∣ ∣ ∑ i ω i ( x i − x i ˉ ) x i ^ − y − y ˉ y ^ ∣ ∣ 2 , x ˉ = m e a n ( x ) , x ^ = s t d ( x ) Loss(\omega)=\frac{1}{2N}||\sum_{i}\frac{\omega_{i}(x_i-\bar{x_i})}{\hat{x_i}}-\frac{y-\bar{y}}{\hat{y}}||^2,\bar{x}=mean(x),\hat{x}=std(x) Loss(ω)=2N1∣∣i∑xi^ωi(xi−xiˉ)−y^y−yˉ∣∣2,xˉ=mean(x),x^=std(x)
从上面公式中可以看出,类似 x ^ \hat{x} x^还有 x ˉ \bar{x} xˉ都是到特征维度的统计量,可以事先计算得到。进一步的,可以考虑通过公式的变换,将与 x i x_i xi无关的部分分离出来。
L o s s ( ω ) = 1 2 N ∣ ∣ ∑ i ω i x i x i ^ − ∑ i ω i x i ˉ x i ^ − y y ^ + y ˉ y ^ ∣ ∣ 2 = 1 2 N ∣ ∣ ∑ i ω i ′ x i − y y ^ + o f f s e t ∣ ∣ 2 Loss(\omega)=\frac{1}{2N}||\sum_i\frac{\omega_ix_i}{\hat{x_i}}-\sum_i\frac{\omega_i\bar{x_i}}{\hat{x_i}}-\frac{y}{\hat{y}}+\frac{\bar{y}}{\hat{y}}||^2=\frac{1}{2N}||\sum_i\omega_i'x_i-\frac{y}{\hat{y}}+offset||^2 Loss(ω)=2N1∣∣i∑xi^ωixi−i∑xi^ωixiˉ−y^y+y^yˉ∣∣2=2N1∣∣i∑ωi′xi−y^y+offset∣∣2
其中 o f f s e t = − ∑ i ω i x i ˉ x i ^ + y ˉ y ^ , ω i ′ = ω i x i ^ offset=-\sum_i\frac{\omega_i\bar{x_i}}{\hat{x_i}}+\frac{\bar{y}}{\hat{y}},\omega_i'=\frac{\omega_i}{\hat{x_i}} offset=−∑ixi^ωixiˉ+y^yˉ,ωi′=xi^ωi
到这一步我们将只与统计量相关的部分给分离出来了。下面我们给出梯度的计算公式
∂ ( L o s s ( ω ) ) ∂ ( ω i ) = d i f f N ∗ x i − x i ˉ x i ^ , d i f f = ∣ ∣ ∑ i ω i ′ x i − y y ^ + o f f s e t ∣ ∣ \frac{\partial(Loss(\omega))}{\partial(\omega_i)}=\frac{diff}{N}*\frac{x_i-\bar{x_i}}{\hat{x_i}},diff=||\sum_i\omega_i'x_i-\frac{y}{\hat{y}}+offset|| ∂(ωi)∂(Loss(ω))=Ndiff∗xi^xi−xiˉ,diff=∣∣i∑ωi′xi−y^y+offset∣∣
对上面公式做进一步的变换可得到
∂ ( L o s s ( ω ) ) ∂ ( ω i ) = 1 N ∑ j d i f f j ∗ x i j − x i ˉ x i ^ = 1 N ( ∑ j d i f f j ∗ x i j x i ^ − ∑ j d i f f j ∗ x i ˉ x i ^ ) \frac{\partial(Loss(\omega))}{\partial(\omega_i)}=\frac{1}{N}\sum_jdiff_j*\frac{x_{ij}-\bar{x_i}}{\hat{x_i}}=\frac{1}{N}(\sum_jdiff_j*\frac{x_{ij}}{\hat{x_i}}-\sum_jdiff_j*\frac{\bar{x_i}}{\hat{x_i}}) ∂(ωi)∂(Loss(ω))=N1j∑diffj∗xi^xij−xiˉ=N1(j∑diffj∗xi^xij−j∑diffj∗xi^xiˉ)
其中括号中后半部分中的 ∑ j d i f f j \sum_jdiff_j ∑jdiffj,可有
∑ j d i f f j = ∑ j ( ∑ i w i ( x i j − x i ˉ ) / x i ^ − ( y j − y ˉ ) / y ^ ) = ∑ i ∑ j ω i ( x i j − x i ˉ ) x i ^ − ∑ j y j − y ˉ y ^ = ∑ i ω i N x i ˉ − N x i ˉ x i ^ − N y ˉ − N y ˉ y i ^ = 0 \sum_jdiff_j=\sum_j (\sum_i w_i(x_{ij} - \bar{x_i}) / \hat{x_i} - (y_j - \bar{y}) / \hat{y}) \\ = \sum_i\sum_j\frac{\omega_i(x_{ij}-\bar{x_i})}{\hat{x_i}}-\sum_j\frac{y_j-\bar{y}}{\hat{y}}\\=\sum_i\omega_i\frac{N\bar{x_i}-N\bar{x_i}}{\hat{x_i}}-\frac{N\bar{y}-N\bar{y}}{\hat{y_i}}=0 j∑diffj=j∑(i∑wi(xij−xiˉ)/xi^−(yj−yˉ)/y^)=i∑j∑xi^ωi(xij−xiˉ)−j∑y^yj−yˉ=i∑ωixi^Nxiˉ−Nxiˉ−yi^Nyˉ−Nyˉ=0
也就是说 ∑ j d i f f j = 0 \sum_jdiff_j=0 ∑jdiffj=0,因此,最终我们可以得到梯度的计算公式为
∂ ( L o s s ( ω ) ) ∂ ( ω i ) = 1 N ( ∑ j d i f f j ∗ x i j x i ^ − ∑ j d i f f j ∗ x i ˉ x i ^ ) = 1 N ∑ j d i f f j ∗ x i j x i ^ \frac{\partial(Loss(\omega))}{\partial(\omega_i)}=\frac{1}{N}(\sum_jdiff_j*\frac{x_{ij}}{\hat{x_i}}-\sum_jdiff_j*\frac{\bar{x_i}}{\hat{x_i}})\\=\frac{1}{N}\sum_jdiff_j*\frac{x_{ij}}{\hat{x_i}} ∂(ωi)∂(Loss(ω))=N1(j∑diffj∗xi^xij−j∑diffj∗xi^xiˉ)=N1j∑diffj∗xi^xij
之所以进行上面的公式推导,主要在于BlockLeastSquaresAggregator中对于梯度和Loss值的计算就是基于以上的推导结果。
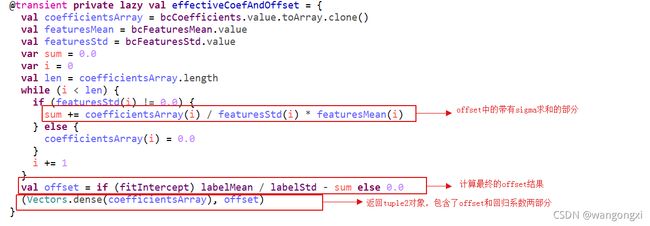
effectiveCoefAndOffset是一个tuple2对象,第一个元素就是原始的回归系数,第二个参数是offset的具体值,计算依据就是上面对offset的推导结果。effectiveCoefAndOffset对象是一个lazy对象,默认不会计算。effectiveCoefAndOffset实际是在BlockLeastSquaresAggregator.add方法中调用。我们来具体看下add方法的实现。

add方法是实际的计算训练样本Loss值和梯度的的方法。在截图中我们已经做了一些注释,这里再对一些细节做下说明。首先是计算offset的数值,这段逻辑上面已经解释过,然后基于offset的值计算diff的值。diff的计算分为两步,首先对于每一个样本计算 o f f s e t − y / y ^ offset-y/\hat{y} offset−y/y^的值,然后调用BLAS.gemv接口计算 o f f s e t − y / y ^ + ∑ i ω i ∗ x i j / x i ^ offset-y/\hat{y}+\sum_i\omega_i*x_{ij}/\hat{x_i} offset−y/y^+∑iωi∗xij/xi^。由于在L544-L550中对于每个特征值已经计算了 x i j / x i ^ x_{ij}/\hat{x_i} xij/xi^值,也就是说实际现在参与计算的其实是原始特征值除以该列特征标准差的结果,因此直接计算回归系数与当前特征值的内积即可。计算完diff值后,再循环遍历每一个样本的diff值计算Loss值并累加到当前block的总Loss值中。对于梯度值的计算放在最后一步。整个计算流程主要是依赖上面推导的结果。应该说在工程落地上,做了很多的优化工作,提升了性能。最后我们回到LinearRegression.trainImpl方法的主流程上,看下最后一部分的逻辑。

最后这一部分逻辑主要是通过上面训练结束返回的state迭代器中获取最终各个回归系数以及历史的Loss值序列。同时释放掉一些内存中的对象,包括一些广播变量。在train的主逻辑的最后还有基于训练得到的参数创建模型对象的逻辑,这个比较清晰,就不多赘述了。那么到此线性回归模型的构建过程就结束了。
3. 总结
线性回归模型是很常用的baseline,通过添加正则化项我们可以得到Lasso或者Ridge回归等。Spark ML中事先了该模型的训练和预测过程。由于预测的逻辑比较简单,直接做特征值与回归系数的内积再加上偏置项即可,因此这里就不单独说明了。
再Spark MLlib包中其实有LinearRegression用SGD算法训练的版本,但主要是为online training服务的,因此从Spark 3.0开始没法直接建模。早期的Spark MLlib包中实际是同时支持SGD和L-BFGS的。有兴趣的同学可以用早期的版本,或者自己实现下也是很方便的。下面的官网的例子,可以参考下做online的线性回归模型的训练。
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.regression.StreamingLinearRegressionWithSGD
val trainingData = ssc.textFileStream(args(0)).map(LabeledPoint.parse).cache()
val testData = ssc.textFileStream(args(1)).map(LabeledPoint.parse)
val numFeatures = 3
val model = new StreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.zeros(numFeatures))
model.trainOn(trainingData)
model.predictOnValues(testData.map(lp => (lp.label, lp.features))).print()
ssc.start()
ssc.awaitTermination()
在上面分析源码的部分,实际很多都是和L-BFGS相关的。对于Breeze库中的优化算法包括一些矩阵操作如果有时间会单独写博客来分析,毕竟优化算法库是算法工程落地的基础,尤其后面介绍逻辑回归等模型的时候也是会用到这些优化工具的,所以其实这部分单独介绍会好一些。
对于源码中用到或者准确来说可以选择的Huber Loss以及最小二乘法可以具体用到的时候再去仔细看,总体逻辑是差不多的。至于实际使用中哪个更好的问题,一般倾向于Huber Loss优于MSE,但实际使用的时候可以都尝试下。