python gephi可视化 金庸人物关系图
使用python+gephi分析金庸小说人物关系
参考文章:https://blog.csdn.net/weixin_39768541/article/details/84958298
1.模型构建
当两个人物在相邻段落出现时,视为两者存在关系
(该方法可以表示一定的人物关系,但是也存在显著缺陷,后续可进行相关改进)
2.人物获取
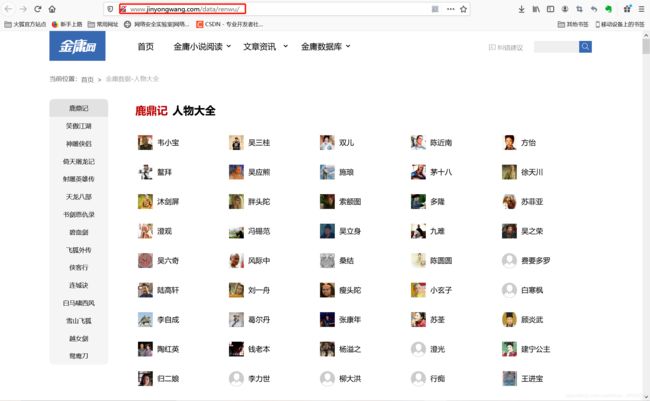
通过金庸小说网获取小说中所有人物
import requests
from bs4 import BeautifulSoup
import re
import jieba
from collections import Counter
import csv
respond = requests.get("http://www.jinyongwang.com/data/renwu/")
html = respond.text
soup = BeautifulSoup(html, 'lxml')
OringialPath = soup.find_all(class_="datapice")
pattern = re.compile('(?<=alt=").*?(?=")')
name_list = re.findall(pattern, str(OringialPath))
name_set = set(name_list)成功实现获取金庸小说所有人物

3.文章获取
使用爬虫获取文章,并根据段落进行分割,保存到数组中
article = ["fei","xue","lian","tian","she","bai","lu","xiao","shu","shen","xia","yi","bi","yuan","yue"]
article = ["xiao"]
URL_Base = "http://www.jinyongwang.com/"
URL = [URL_Base + name + "/" for name in article]
print(URL)
data = []
for u in URL:
print(u)
book = u.split("/")[-2]
print(book)
listpath = []
try:
respond = requests.get(u)
html = respond.text
soup = BeautifulSoup(html, 'lxml')
OringialPath = soup.find_all(class_="mlist")
pattern = re.compile('(?<=href=").*?(?=")')
listpath = re.findall(pattern, str(OringialPath))
# print(listpath)
except:
print("Error")
for l in listpath:
web = URL_Base + l
respond = requests.get(web)
html = respond.text
pattern = re.compile('(?<=).*?(?=
)')
text = re.findall(pattern, str(html))
# print(text)
for i in range(len(text)-1):
# print(i,i+1)
a = jieba.lcut(text[i])
b = jieba.lcut(text[i+1])
first = set(a)&set(name_set)
second = set(b)&set(name_set)
# print(first)
# print(second)
if(first and second):
for f in first:
for s in second:
if(f!=s):
print(f+"_"+s+"_"+book)
data.append(f+"_"+s+"_"+book)
# print(data)
4.关系识别
通过使用jieba匹配人物,并根据上下文识别关系,并写入文件
f = open('data.csv','w',encoding='utf-8',newline="")
csv_writer = csv.writer(f)
csv_writer.writerow(["source","target","book","weight"])
counts = Counter(data)
print(counts)
for c in counts:
line = c.split("_")
print(line)
print(counts[c])
line.append(counts[c])
csv_writer.writerow(line)
f.close()结果如下所示

5.gephi展示
5.1导入数据
导入电子表格
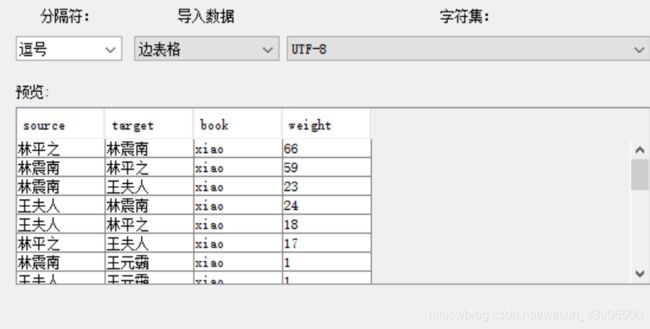
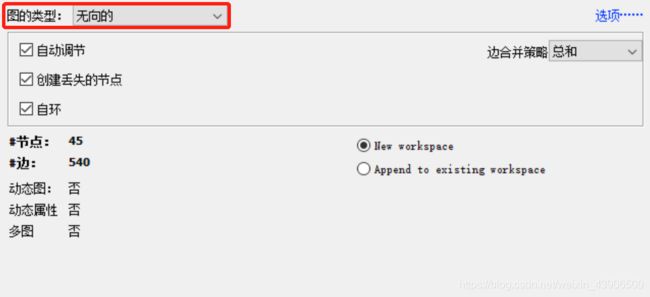
选择无向图
数据表格边如下
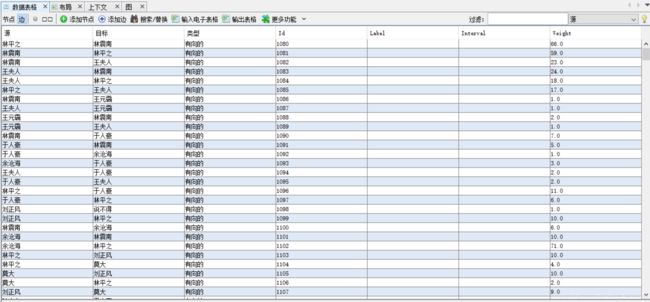
数据表格节点由于自动生成,需要将ID列复制到标签列
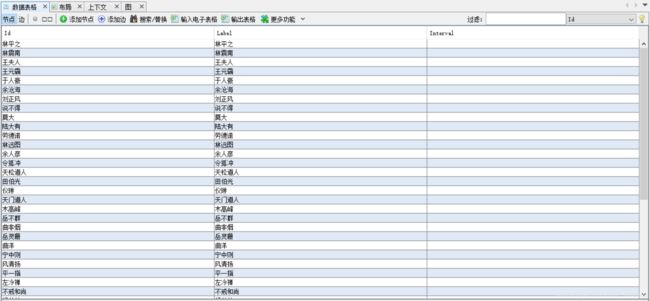
5.2数据可视化
当预览显示时,标签处显示为方框
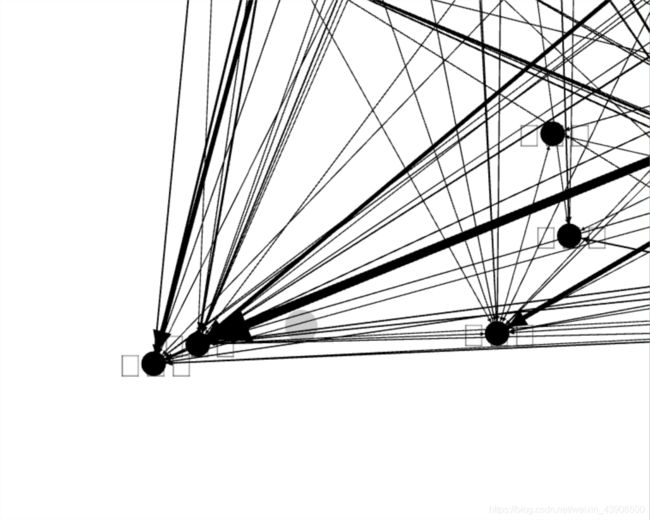
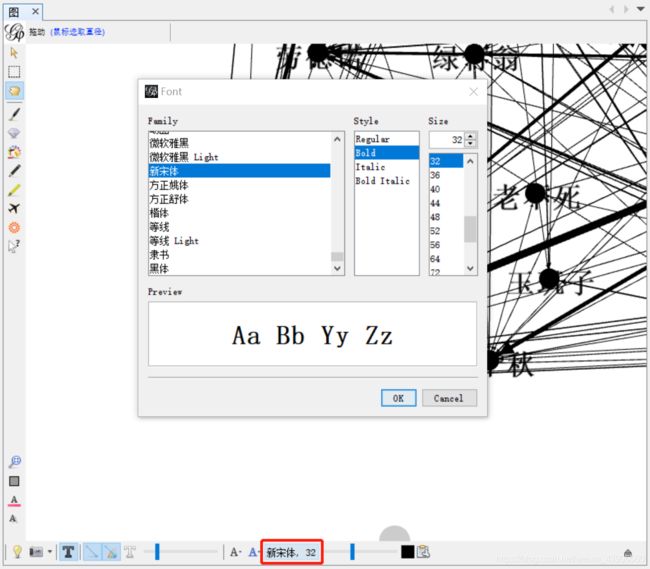
通过测试,可知是由于字体问题,通过修改字体实现标签的显示
通过修改节点和边的布局,可视化结果如下所示
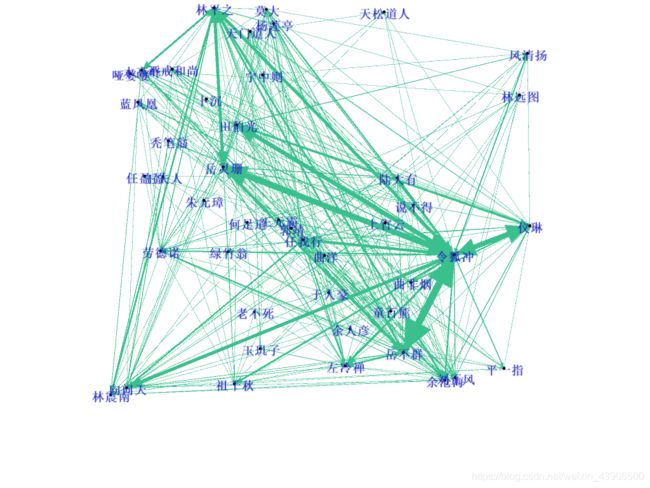
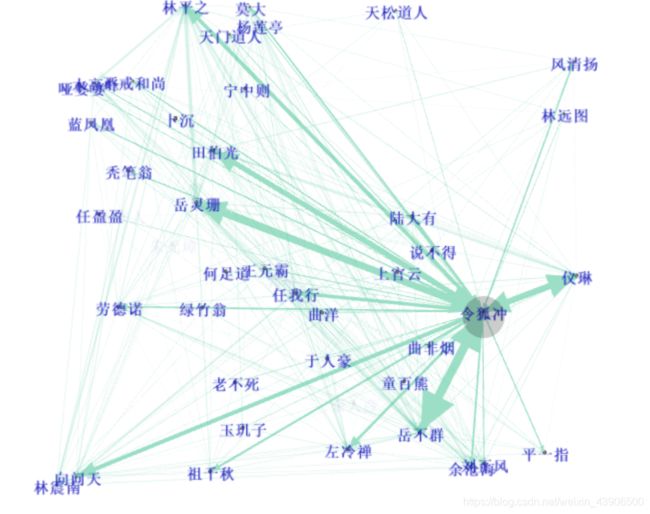
查看令狐冲的关系图,如下所示
6.完整代码
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
import jieba
from collections import Counter
import csv
respond = requests.get("http://www.jinyongwang.com/data/renwu/")
html = respond.text
soup = BeautifulSoup(html, 'lxml')
OringialPath = soup.find_all(class_="datapice")
pattern = re.compile('(?<=alt=").*?(?=")')
name_list = re.findall(pattern, str(OringialPath))
print(name_list)
name_set = set(name_list)
f = open('name.txt','w')
for i in name_list:
f.write(i)
f.write("\n")
f.close()
article = ["fei","xue","lian","tian","she","bai","lu","xiao","shu","shen","xia","yi","bi","yuan","yue"]
# article = ["xiao"]
URL_Base = "http://www.jinyongwang.com/"
URL = [URL_Base + name + "/" for name in article]
print(URL)
data = []
for u in URL:
print(u)
book = u.split("/")[-2]
print(book)
listpath = []
try:
respond = requests.get(u)
html = respond.text
soup = BeautifulSoup(html, 'lxml')
OringialPath = soup.find_all(class_="mlist")
pattern = re.compile('(?<=href=").*?(?=")')
listpath = re.findall(pattern, str(OringialPath))
# print(listpath)
except:
print("Error")
for l in listpath:
web = URL_Base + l
respond = requests.get(web)
html = respond.text
pattern = re.compile('(?<=).*?(?=
)')
text = re.findall(pattern, str(html))
# print(text)
for i in range(len(text)-1):
# print(i,i+1)
a = jieba.lcut(text[i])
b = jieba.lcut(text[i+1])
first = set(a)&set(name_set)
second = set(b)&set(name_set)
# print(first)
# print(second)
if(first and second):
for f in first:
for s in second:
if(f!=s):
print(f+"_"+s+"_"+book)
data.append(f+"_"+s+"_"+book)
# print(data)
f = open('data.csv','w',encoding='utf-8',newline="")
csv_writer = csv.writer(f)
csv_writer.writerow(["source","target","book","weight"])
counts = Counter(data)
print(counts)
for c in counts:
line = c.split("_")
print(line)
print(counts[c])
line.append(counts[c])
csv_writer.writerow(line)
f.close()7.资料下载
金庸小说人物关系分析代码:https://download.csdn.net/download/weixin_43906500/15385425
笑傲江湖人物关系数据:https://download.csdn.net/download/weixin_43906500/15385421
金庸小说人物数据下载:https://download.csdn.net/download/weixin_43906500/15385386
笑傲江湖人物分析网络资源:https://download.csdn.net/download/weixin_43906500/15385433