机器学习之自然语言处理——中文分词jieba库详解(代码+原理)
目录
- 文本分类概述
-
- 文本分类的应用
- 文本分类的挑战
- 文本分类的算法应用
- 文本分类所需知识
-
-
- 中文分词神器-jieba
-
- jieba分词的三种模式
- 词性标注
- 载入词典(不分词)
- 词典中删除词语(不显示)
- 停用词过滤
- 调整词语的词频
- 关键词提取
-
- 基于TF-IDF算法的关键词提取
- 基于 TextRank 算法的关键词抽取
- 返回词语在原文的起止位置(论文常用算法)
- 词频统计(附智能程序)
- 每文一语
-
文本分类概述
文本分类的应用
在大数据时代,网络上的文本数据日益增长。采用文本分类技术对海量数据进行科学地组织和管理显得尤为重要。
文本作为分布最广、数据量最大的信息载体,如何对这些数据进行有效地组织和管理是亟待解决的难题。
文本分类是自然语言处理任务中的一项基础性工作,其目的是对文本资源进行整理和归类,同时其也是解决文本信息过载问题的关键环节。
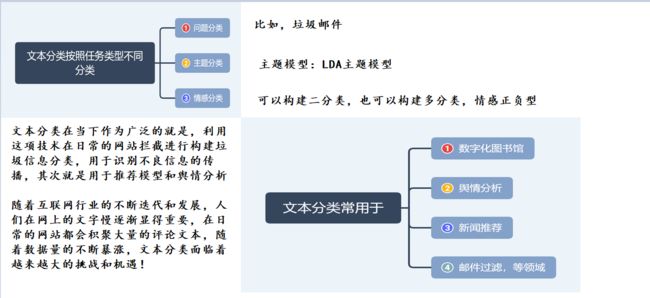
文本分类按照任务类型的不同可划分为问题分类、主题分类以及情感分类。
常用于数字化图书馆、舆情分析、新闻推荐、邮件过滤等领域,为文本资源的查询、检索提供了有力支撑,是当前的主要研究热点之一。
问题分类在问答系统 ( Question AnsweringSystem) 中起着重要作用,提高问题分类的准确率有助于构建更加鲁棒的 QA 系统。
在图书情报领域,专利、图书、期刊论文、学术新闻等跨类型学术资源的自动组织与分类是数字化图书馆的关键技术,有利于工业企业、科研院所的研究人员更快地掌握各类前沿动态。
随着移动互联网的发展,人们获取信息的方式发生了变化,由单纯的信息检索转变为“搜索 + 推荐”的双引擎模式。但无论是搜索还是推荐,其背后都离不开机器对内容的理解能力。
文本作为网络上分布最广、数据量最大的信息载体,准确的分类标签为资源检索和新闻资讯的个性化推荐提供了有力支撑,使得推荐的信息能够尽可能地满足千人千面的用户需求。
情感分类(情感极性分析) 是文本分类的重要分支。如在社交媒体中,对用户评论的情感倾向进行分析( 积极、消极等) 。情感极性分析能帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有力的决策支持。此外,情感分析技术还可以用在商品和服务领域。例如对产品、电影、图书评论的情感分类。
智能手机的普及促进了在线即时消息和短信使用的增长。将文本分类技术应用于邮件检测和短信过滤任务,可以帮助人们快速筛选有用信息。
文本分类的挑战
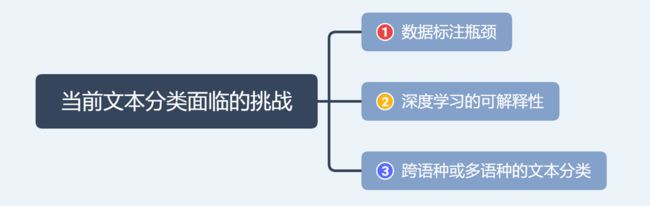
(1) 数据标注瓶颈。
数据和算法是推动人工智能向前发展的主要动力。高质量的标记数据有助于提升文本分类的准确率。然而,网络上存在大量杂乱无章的无标签数据,依赖人工标注的成本高,效率低。无监督数据的特征学习和半监督学习自动标注过程中的噪音剔除是当前的研究热点和难点。
(2) 深度学习的可解释性。
深度学习模型在特征提取,语义挖掘方面有着独特的优势,在文本分类任务中取得了不俗的成绩。然而,深度学习是一个黑盒模型,其训练过程难以复现,隐语义和输出结果的可解释性较差。例如,结合迁移学习理论的文本分类方法,初始预训练的语言模型学习到哪些知识,在参数迁移、特征迁移、针对目标域的训练数据和分类任务进行微调时,保留了哪些特征,我们很难了解。这使得模型的改进与优化失去了明确的指引,也大大加深了研究人员调参的难度。
(3) 跨语种或多语种的文本分类。
在经济全球化的大背景下,跨语言的文本分类在跨国组织和企业中的应用越来越多。将在源语言中训练的分类模型应用于另一种语言( 目标语言) 的分类任务,其挑战性在于源语言数据的特征空间与目标语言数据之间缺乏重叠。各国的语言、文字包含不同的语言学特征,这无疑加大了跨语言文本分类的难度。
当前,基于机器翻译技术的跨语言文本分类方法过于依赖双语词典和平行语料,在一些小语种上的表现较差。通过跨语言文本表示技术和迁移学习方法训练得到独立于语言的分类模型是未来的重点研究方向。
目前自然语言的处理,在文本分类上的技术研究,已经不断地在成熟发展,这方面的生态也在不断地扩张和壮大。
文本分类的算法应用
(1) 对传统方法进行优化如常用机器学习模型的改进; 传统的机器学习算法、特征提取方法与深度学习模型的融合。
(2) 新理论、新方法的提出如将图卷积神经网络( Graph Convolutional Networks ) 应 用于文本分类任务。
(3) 引入知识库、知识图谱等结构化的外部知识,优化文本表示和预训练的语言模型,进而提升文本分类的性能。
目前相对于比较成熟的还是机器学习构建文本分类,也比较的简单易懂,在逻辑上通过基本的算法调整,在算法上结合逻辑的优化,机器学习和深度学习将在自然语言处理有着极大地生长空间!
文本分类所需知识
中文分词神器-jieba
汉字具有源远流长的文化底蕴,如何利用逻辑性极强的机器来理解具有诗情画意的中文汉字,我们都知道在古代是没有标点符号的,那么人们是通过什么来进行断句的呢?
古文从来没有标点,古人读书,首先要学会“句读”,所以“习六书,明句读”是读书人的基本功。简而言之就是根据文章的意思和固定的格式以及对应的词义进行断句。这也要求知识分子需要从小锻炼自己的读书能力,随着时代的发展和进步,人们的生活步伐必须要跟进社会的进步,标点符号慢慢的走进了人们的视野,“16世纪时,小马努蒂乌斯提出了一套正规的标点符号系统。主要符号源于希腊语法家们所用的小点,但常常改变其含义。
断句在自然语言处理中,显得十分重要,因为我们需要根据文本分词组成的一个大的迭代对象进行词的向量化,所以我们介绍一种python第三方库——jieba,中文分词的神器!

Jieba库是优秀的中文分词第三方库,中文文本需要通过分词获得单个的词语。
Jieba库的分词原理:利用一个中文词库,确定汉字之间的关联概率,汉字间概率大的组成词组,形成分词结果。除了分词,用户还可以添加自定义的词组。
jieba分词的三种模式
精确模式:就是把一段文本精确地切分成若干个中文单词,若干个中文单词之间经过组合,就精确地还原为之前的文本。其中不存在冗余单词。
全模式:将一段文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式,或者有不同的角度来切分变成不同的词语,在全模式下,Jieba库会将各种不同的组合都挖掘出来。分词后的信息再组合起来会有冗余,不再是原来的文本。
搜索引擎模式:在精确模式基础上,对发现的那些长的词语,我们会对它再次切分,进而适合搜索引擎对短词语的索引和搜索。也有冗余。
 jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。
该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
使用搜索引擎模型,有限公司被分词为:有限 公司
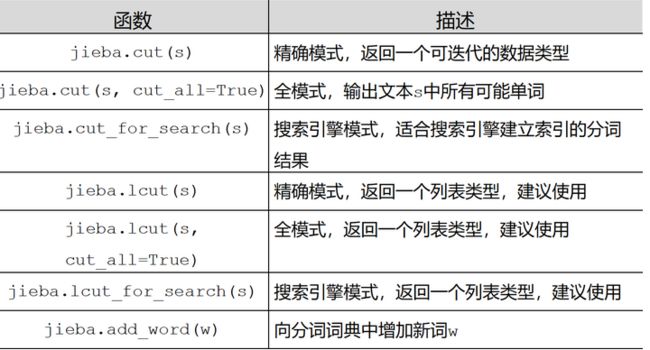
jieba库的一般函数
 案例:
案例:
cut()函数有4个参数:
第一个参数:待分词文本
cut_all:设置使用全模式(True)还是精确模式(False); 默认False
use_paddle:控制是否使用Paddle模式进行分词
HMM:控制是否使用HMM模式识别新词
use_paddle参数可以设置开启paddle模式
import jieba
import paddle
str1 = '我来到了西北皇家理工学院,发现这儿真不错'
#jieba.enable_paddle() 已经停用
paddle.enable_static()
seg_list = jieba.cut(str1, use_paddle=True) #使用paddle模式进行分词
print('Paddle模式分词结果:', '/'.join(seg_list))
'''
Paddle模式分词结果:
我/来到/了/西北/皇家/理工学院/,/发现/这儿/真不错
'''
一般的,lcut比较的常用,大多用于分词
词性标注
通常中文里面的词性大多都已经在下面列举出来了

import jieba
import jieba.posseg as pseg
#jieba.enable_paddle()
str2 = '上海自来水来自海上'
seg_list = pseg.cut(str2, use_paddle=True) #使用posseg进行分词
for seg, flag in seg_list:
print(seg, flag)
上海 ns
自来水 l
来自 v
海上 s
载入词典(不分词)
可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
这个文件需要自己根据自己的使用场景进行测试,这里提供一个
ieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。

有需要的可以点击此处下载
file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
词频省略时使用自动计算的能保证分出该词的词频。
jieba.add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
jieba.suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效
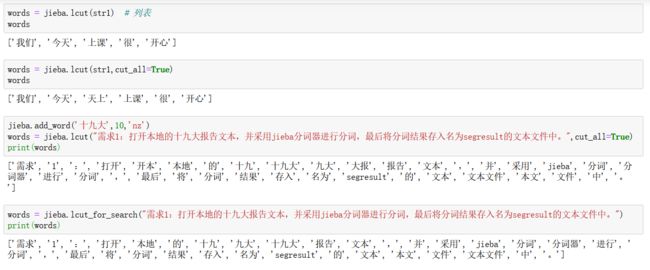
jieba.add_word('铃儿响叮当')
jieba.add_word('让世界充满爱')
jieba.add_word('迅雷不及掩耳之势')
lcut_res = jieba.lcut(test_content, cut_all=True, HMM=False)
print('[添加自定义词语]:', lcut_res)
[添加自定义词语]:
[‘迅雷’, ‘迅雷不及’, ‘迅雷不及掩耳’, ‘不及’, ‘掩耳’, ‘掩耳盗铃’,‘铃儿响叮当’, ‘响叮当’, ‘叮当’, ‘当仁不让’, ‘不让’, ‘让世界充满爱’, ‘世界’, ‘充满’, ‘爱’, ‘之’, ‘势’]
add_word()有三个参数,分别是添加的词语、词频和词性,词频和词性可以省略。
添加自定义词语后,自定义词语如果能匹配到,就会返回到分词结果中。如果自定义词语在待分词语句中没有连续的匹配结果,分词结果中不会体现。
词典中删除词语(不显示)
jieba.del_word('不及')
jieba.del_word('不让')
jieba.del_word('之')
lcut_res = jieba.lcut(test_content, cut_all=True, HMM=False)
print('[删除词语]:', lcut_res)
[删除词语]:
[‘迅雷’, ‘迅雷不及’, ‘迅雷不及掩耳’, ‘掩耳’, ‘掩耳盗铃’, ‘儿’, ‘响叮当’, ‘叮当’,‘当仁不让’, ‘世界’, ‘充满’, ‘爱’, ‘之’, ‘势’]
删除的词语一般是语气助词、逻辑连接词等,这些词对于文本分析没有实际意义,反而会成为干扰。
在设置删除的词语后,结果中不再有删除的词语,但对于单个字,会独立成词,所以删除后在结果中也还存在。
怎么理解这句话呢,我们看看一个实际的例子!
import jieba
jieba.load_userdict('用户词典.txt')
jieba.del_word('一低头')
seg_list = jieba.cut('心灵感应般地蓦然回首,才能撞见那一低头的温柔;也最是那一低头的温柔,似一朵水莲花不胜凉风的娇羞;也最是那一抹娇羞,才能让两人携手共白首。')
print('删除自定义词时的精确模式分词结果:\n', '/'.join(seg_list))
删除自定义词时的精确模式分词结果:
心灵感应/般地/蓦然回首/,/才能/撞见/那一/低头/的/温柔/;/也/最/是/那/一/低头/的/温柔/,/似/一朵/水莲花/不胜/凉风/的/娇羞/;/也/最/是/那/一抹/娇羞/,/才能/让/两人/携手/共/白首/。
一低头,动态删除,但是没有意味着我把“一低头”真正的在这个词库里面删除了,而是分解了,组合为其他的词组了
停用词过滤
当然,这里我们还可以是用过滤词,也就是停用词进行对一些无用删除,过滤,就像下面的这个一样
#启动停用词过滤
import jieba
with open('stopwords.txt', 'r+', encoding = 'utf-8')as fp:
stopwords = fp.read().split('\n') #将停用词词典的每一行停用词作为列表中的一个元素
word_list = [] #用于存储过滤停用词后的分词结果
text = '商务部4月23日发布的数据显示,一季度,全国农产品网络零售额达936.8亿元,增长31.0%;电商直播超过400万场。电商给农民带来了新的机遇。'
seg_list = jieba.cut(text)
for seg in seg_list:
if seg not in stopwords:
word_list.append(seg)
print('启用停用词过滤时的分词结果:\n', '/'.join(word_list))
 有需要的可以点击此处下载
有需要的可以点击此处下载
调整词语的词频
调整词语的词频,调整其在结果中被分出来的可能性,使分词结果满足预期。
分两种情况,一种是将分词结果中的一个长词拆分成多个词,另一种是将分词结果中的多个词组成一个词。
lcut_res = jieba.lcut(test_content, cut_all=False, HMM=False)
print('[设置前]:', lcut_res)
jieba.suggest_freq('让世界充满爱', True)
lcut_res = jieba.lcut(test_content, cut_all=False, HMM=False)
print('[设置后]:', lcut_res)
[设置前]: [‘迅雷不及’, ‘掩耳盗铃’, ‘儿’, ‘响’, ‘叮’, ‘当仁不让’, ‘世界’, ‘充满’, ‘爱’, ‘之’, ‘势’]
[设置后]: [‘迅雷不及’, ‘掩耳盗铃’, ‘儿’, ‘响叮当’, ‘仁’, ‘不’, ‘让世界充满爱’, ‘之’, ‘势’]
再来一个案例,让理解变得更加深刻:
他/认为/未来/几年/健康/产业/在/GDP/中将/占/比/第一/。
#修改词频
import jieba
str3 = '他认为未来几年健康产业在GDP中将占比第一。'
jieba.suggest_freq(('中', '将'), True) #修改词频 强制“中将”
jieba.suggest_freq('占比', True) #强制让“占比”作为一次词
seg_list = jieba.cut(str3, HMM=False)
print('精确模式分词结果:\n', '/'.join(seg_list))
他/认为/未来/几年/健康/产业/在/GDP/中/将/占比/第一/。
我们的思路有很多种,比如我们可以将这些不需要分词,使用jieba.addword()加入到里面,但是有时候的效果并不好,如果我们采用这样的模式,可能效果更加的好!
例如:

方法有很多,“条条大路通罗马”,需要的时候可以多去尝试一下,这些方法,看效果最终谁比较的凸出明显!
关键词提取
关键词提取使用jieba中的analyse模块,基于两种不同的算法,提供了两个不同的方法。
基于TF-IDF算法的关键词提取
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
案例代码
import jieba.analyse
sentence='''在克鲁伊夫时代,巴萨联赛中完成四连冠,后三个冠军都是在末轮逆袭获得的。在91//92赛季,巴萨末轮前落后皇马1分,结果皇马客场不敌特内里费使得巴萨逆转。一年之后,巴萨用几乎相同的方式逆袭,皇马还是末轮输给了特内里费。在93/94赛季中,巴萨末轮落后拉科1分。巴萨末轮5比2屠杀塞维利亚,拉科则0比0战平瓦伦西亚,巴萨最终在积分相同的情况下靠直接交锋时的战绩优势夺冠。神奇的是,拉科球员久基齐在终场前踢丢点球,这才有巴萨的逆袭。
巴萨上一次压哨夺冠,发生在09/10赛季中。末轮前巴萨领先皇马1分,只要赢球就夺冠。末轮中巴萨4比0大胜巴拉多利德,皇马则与对手踢平。巴萨以99分的佳绩创下五大联赛积分记录,皇马则以96分成为了悲情的史上最强亚军。
在48/49赛季中,巴萨末轮2比1拿下同城死敌西班牙人,以2分优势夺冠。52/53赛季,巴萨末轮3比0战胜毕巴,以2分优势力压瓦伦西亚夺冠。在59/60赛季,巴萨末轮5比0大胜萨拉戈萨。皇马巴萨积分相同,巴萨靠直接交锋时的战绩优势夺冠。'''
print(jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=()))
print(jieba.analyse.extract_tags(sentence, topK=20, withWeight=True, allowPOS=()))
print(jieba.analyse.extract_tags(sentence, topK=20, withWeight=True, allowPOS=('i','n','f','s','t')))
['巴萨', '末轮', '皇马', '夺冠', '赛季', '拉科', '内里费', '积分', '逆袭', '瓦伦西亚', '优势', '大胜', '联赛', '相同', '战绩', '交锋', '四连冠', '多利德', '落后', '克鲁伊夫']
[('巴萨', 1.2181461971020409), ('末轮', 0.7319245409938775), ('皇马', 0.5362676344), ('夺冠', 0.42225835063265305), ('赛季', 0.39762426810693874), ('拉科', 0.2471207792387755), ('内里费', 0.18912486601360545), ('积分', 0.1691336641957143), ('逆袭', 0.16264989799863944), ('瓦伦西亚', 0.16264989799863944), ('优势', 0.15362255099918368), ('大胜', 0.12660622859646256), ('联赛', 0.12398892393455782), ('相同', 0.12255595193938776), ('战绩', 0.12077275008340135), ('交锋', 0.11605496086870748), ('四连冠', 0.09456243300680273), ('多利德', 0.09456243300680273), ('落后', 0.09077944490340135), ('克鲁伊夫', 0.08708888002244898)]
[('末轮', 2.2989937505576923), ('皇马', 1.5159873510923079), ('赛季', 1.1240532194561537), ('内里费', 0.5346414481538462), ('优势', 0.43427913455538464), ('战绩', 0.34141527427423074), ('交锋', 0.32807844707115386), ('压哨', 0.2298993750557692), ('赢球', 0.2298993750557692), ('力压', 0.2298993750557692), ('终场', 0.22506640528076924), ('战平', 0.22120735344615383), ('悲情', 0.21173665180961537), ('点球', 0.20620430426153843), ('佳绩', 0.19894864597115386), ('客场', 0.1913352679498077), ('球员', 0.1652386529725), ('冠军', 0.14683416229307691), ('战胜', 0.14229592272), ('领先', 0.13591626767673076)]
# 基于TF-IDF算法的关键词提取
from jieba import analyse
text = '记者日前从中国科学院南京地质古生物研究所获悉,该所早期生命研究团队与美国学者合作,在中国湖北三峡地区的石板滩生物群中,发现了4种形似树叶的远古生物。这些“树叶”实际上是形态奇特的早期动物,它们生活在远古海洋底部。相关研究成果已发表在古生物学国际专业期刊《古生物学杂志》上。'
keywords = analyse.extract_tags(text, topK=10, withWeight=True, allowPOS=('n', 'v'))
print(keywords)
[('古生物学', 0.783184303024), ('树叶', 0.6635900468544), ('生物群', 0.43238540794400004), ('古生物', 0.38124919198039997), ('期刊', 0.36554014868720003), ('石板', 0.34699723913040004), ('形似', 0.3288202017184), ('研究成果', 0.3278758070928), ('团队', 0.2826627565264), ('获悉', 0.28072960723920004)]
基于 TextRank 算法的关键词抽取
两种方法的区别是默认提取的词性不同
当然算法不同,结果可能有差异
jieba.analyse.textrank(sentance, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
# 基于TextRank算法的关键词提取
from jieba import analyse
text = '记者日前从中国科学院南京地质古生物研究所获悉,该所早期生命研究团队与美国学者合作,在中国湖北三峡地区的石板滩生物群中,发现了4种形似树叶的远古生物。这些“树叶”实际上是形态奇特的早期动物,它们生活在远古海洋底部。相关研究成果已发表在古生物学国际专业期刊《古生物学杂志》上。'
keywords = analyse.textrank(text, topK=10, withWeight=True, allowPOS=('n', 'v'))
print(keywords)
[('古生物学', 1.0), ('树叶', 0.8797803471074045), ('形似', 0.6765568513591282), ('专业', 0.6684901270801065), ('生物', 0.648692596888148), ('发表', 0.6139083953888275), ('生物群', 0.59981945604977), ('期刊', 0.5651065025924439), ('国际', 0.5642917600351786), ('获悉', 0.5620719278559326)]
返回词语在原文的起止位置(论文常用算法)
返回词语在原文的起止位置使用jieba中的Tokenize模块,实际调用时使用tokenize()方法。
注意,输入参数只接受 unicode
print('默认模式')
for tk in jieba.tokenize(u'华夏文明是一个经久不衰的文明'):
print("word %s\t start: %2d \t end:%2d" % (tk[0],tk[1],tk[2]))
print('搜索模式')
for tk in jieba.tokenize(u'华夏文明是一个经久不衰的文明', mode='search'):
print("word %s\t start: %2d \t end:%2d" % (tk[0],tk[1],tk[2]))
默认模式
word 华夏 start: 0 end: 2
word 文明 start: 2 end: 4
word 是 start: 4 end: 5
word 一个 start: 5 end: 7
word 经久不衰 start: 7 end:11
word 的 start: 11 end:12
word 文明 start: 12 end:14
***********************************
搜索模式
word 华夏 start: 0 end: 2
word 文明 start: 2 end: 4
word 是 start: 4 end: 5
word 一个 start: 5 end: 7
word 经久 start: 7 end: 9
word 不衰 start: 9 end:11
word 经久不衰 start: 7 end:11
word 的 start: 11 end:12
word 文明 start: 12 end:14
词频统计(附智能程序)
import jieba
text = '蒸馍馍锅锅蒸馍馍,馍馍蒸了一锅锅,馍馍搁上桌桌,桌桌上面有馍馍。'
with open('stopwords.txt', 'r+', encoding = 'utf-8')as fp:
stopwords = fp.read().split('\n') #加载停用词
word_dict = {} #用于存储词频统计结果的词典
jieba.suggest_freq(('桌桌'), True) #让“桌桌”作为一个词
seg_list = jieba.cut(text)
for seg in seg_list:
if seg not in stopwords:
if seg in word_dict.keys():
word_dict[seg] += 1 #存在则词频+1
else:
word_dict[seg] = 1 #不存在则存入键值对
print(word_dict)
{'蒸': 3, '馍馍': 5, '锅锅': 1, '一锅': 1, '锅': 1, '搁': 1, '桌桌': 2, '上面': 1}
这里博主也写好了一个智能词云算法,包括生成词云和词频,并且可以自定义展示的词组的格式,一键化输入,只需要用户输出文本路径即可(首先需要将文本复制到txt文件中,然后在讲绝对路径输入即可),看依稀下面的演示视频吧!需要的可以自己点击下面的链接下载!
点击此处下载
智能分词算法
分词完成之后,后续就是如何使用分词好的结果进行构建词向量了!
每文一语
你要相信你走过的每一步都算数!