从零实现深度学习框架——深入浅出Word2vec(上)
引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不使用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
本文我们来探讨word2vec。本文介绍word2vec词嵌入,它一种稠密向量模型,向量的元素值是实数,甚至可以是负数。
值得注意的是,word2vec是一种静态嵌入(static embeddings)模型,即为词典中的单词生成的是固定嵌入,而不是像BERT那样根据上下文生成动态嵌入。
看完本文,你应该可以一次性掌握word2vec的原理以及实现。
word2vec
word2vec是一种高效的训练词向量的模型。它的想法直接,如果两个单词的上下文相似,那么这两个单词(词向量)也应该是相似的。比如,“A dog is running in the room"和"A cat is running in the room”。这两个句子,只是"cat"和"dog"不同,word2vec认为它们是相似的,而n-gram模型做不到这一点。
这里的词向量是什么?为了便于计算机处理,我们需要把文档、单词向量化。而且除了向量化之后,还希望单词的表达能计算相似词信息。
word2vec有两种计算嵌入的方法:skip-gram和CBOW。
我们先来看看CBOW。
CBOW
CBOW(Continuous Bag-of-Words,连续词袋)模型的基本思想是根据上下文对中心词(目标词,target word)进行预测。例如,对于文本 ⋯ w t − 2 w t − 1 w t ‾ w t + 1 w t + 2 ⋯ \cdots \, w_{t-2} \, w_{t-1} \, \underline{w_t} \, w_{t+1} \, w_{t+2} \, \cdots ⋯wt−2wt−1wtwt+1wt+2⋯,CBOW模型的任务是根据一定窗口大小内的上下文 C t C_t Ct(这里窗口大小为 2 2 2,则 C t = { w t − 2 , w t − 1 , w t + 1 , w t + 2 } C_t =\{w_{t-2},w_{t-1},w_{t+1},w_{t+2}\} Ct={wt−2,wt−1,wt+1,wt+2})对 t t t时刻的单词 w t w_t wt进行预测。
但是要注意的是,CBOW模型不考虑单词的顺序,实际上是一个词袋模型,这就是它名字的由来。
CBOW模型可以表示成下图所示的前馈神经网络结构。但不同于一般的前馈神经网络,CBOW模型的隐藏层只是执行对词向量取平均的操作,而没有线性变换和非线性激活过程。这也是CBOW模型训练效率高的原因。
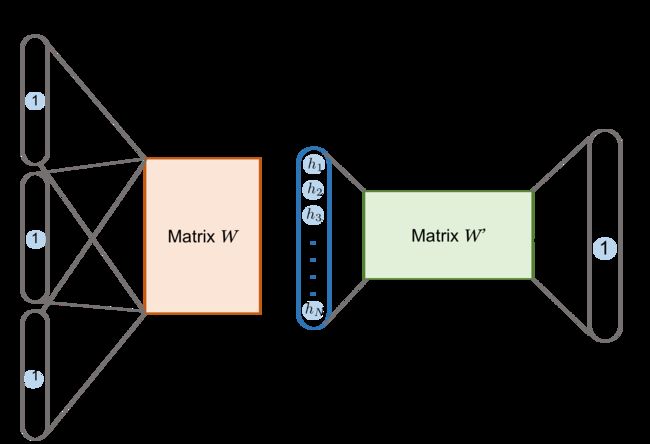
这里给定词典大小为 V V V,每个输入向量 x x x和输出向量 y y y都是维度为 V V V的独热编码。隐藏层的大小为 N N N,表示得到的词嵌入维度。
实际上我们的输入可以直接是索引,这一点在代码实现可以看到。
输入层(input): 以大小为 2 2 2的窗口为例,在目标词 w t w_t wt左右各取 2 2 2个单词作为模型的输入。那么输入就由 4 4 4个维度为词典大小 V V V的独热编码向量构成。
隐藏层(Hidden):隐藏层所做的事情就是对上下文 C t C_t Ct中的所有词向量取平均,得到一个上下文表示。具体来说,首先输入层中每个单词的独热编码向量经过矩阵 W ∈ R V × N W \in \Bbb R^{V \times N} W∈RV×N映射到词向量空间:
v w i = W T x i (1) v_{w_i} = W^T x_i \tag 1 vwi=WTxi(1)
这里 x i x_i xi表示第 i i i个单词的独热编码向量,维度是 V × 1 V \times 1 V×1;而 W W W为 V × N V \times N V×N的权重矩阵;
上式的结果是得到一个 N × 1 N \times 1 N×1的向量,其实就是取矩阵 W W W的第 i i i行,也就是单词 w i w_i wi的词向量。
其实这里用不着独热编码,直接取 W W W的第 i i i行这种索引操作就行了,Pytorch提供了
nn.Embedding来实现这一点。
而 C t = { w t − 2 , w t − 1 , w t + 1 , w t + 2 } C_t =\{w_{t-2},w_{t-1},w_{t+1},w_{t+2}\} Ct={wt−2,wt−1,wt+1,wt+2}表示所有 w t w_t wt的上下文单词的集合,这里对 C t C_t Ct中所有单词的词向量取均值,作为 w t w_t wt的上下文表示:
v C t = 1 ∣ C t ∣ ∑ w ∈ C t v w (2) v_{C_t} = \frac{1}{|C_t|} \sum_{w \in C_t} v_w \tag{2} vCt=∣Ct∣1w∈Ct∑vw(2)
这里 ∣ C t ∣ |C_t| ∣Ct∣表示该集合中单词的总数,这样 v C t v_{C_t} vCt的维度还是 N × 1 N \times 1 N×1。
输出层(Output):输出层做的就是一个多分类问题,与前馈神经网络类似,但是也丢弃了线性变换和偏置。输出层有一个不同的权重矩阵 W ′ W^\prime W′,它的维度是 N × V N \times V N×V的。如果说 W W W是表示中心词的权重矩阵,那么 W ′ W^\prime W′就是表示上下文词的权重矩阵。它的每一列代表一个上下文单词的词向量。
令 v w i ′ v^\prime_{w_i} vwi′为 w i w_i wi在 W ′ W^\prime W′中对应的列向量,维度为 N × 1 N \times 1 N×1。那么现在做的就是用 v C t v_{C_t} vCt与每一个列向量做点积,得到一个分数,这个分数可以理解为衡量中心词 w t w_t wt与输出词的相似度。
我们可以一次计算所有单词的得分:
u = W ′ T ⋅ v C t (3) u = W^{\prime T} \cdot v_{C_t} \tag 3 u=W′T⋅vCt(3)
得到一个 V × 1 V \times 1 V×1的列向量,其中每个元素代表对应单词与中心词的相似得分。最终经过Softmax得到一个概率分布,再和实际的中心词独热编码做一个交叉熵计算损失,我们希望损失越小越好。
若是展开来看,并加上Softmax,那么输出中心词 w t w_t wt的概率可计算为:
P ( w t ∣ v C t ) = exp ( v C t ⋅ v w t ′ ) ∑ w ′ ∈ V exp ( v C t ⋅ v w ′ ′ ) (4) P(w_t|v_{C_t}) = \frac{\exp(v_{C_t} \cdot v^\prime_{w_t})}{\sum_{w^\prime \in \Bbb V} \exp(v_{C_t} \cdot v^\prime_{w^\prime})} \tag {4} P(wt∣vCt)=∑w′∈Vexp(vCt⋅vw′′)exp(vCt⋅vwt′)(4)
损失函数
从公式 ( 4 ) (4) (4)可以看出,这其实是一个多分类问题。除了可以用交叉熵来作为损失函数,也可以用负对数似然损失:
L ( θ ) = ∑ t = 1 T log P ( w t ∣ C t ) (5) L(\theta) = \sum_{t=1}^T \log P(w_t|C_t) \tag 5 L(θ)=t=1∑TlogP(wt∣Ct)(5)
其中 C t = { w t − k , ⋯ , w t − 1 , w t + 1 , ⋯ , w t + k } C_t =\{w_{t-k},\cdots ,w_{t-1},w_{t+1},\cdots ,w_{t+k}\} Ct={wt−k,⋯,wt−1,wt+1,⋯,wt+k}表示窗口大小为 k k k的上下文单词的集合。
有了正向传播过程和损失函数,我们就可以利用metagrad进行代码实现了,而不用关心反向传播过程。
如果想了解反向传播的推导,可以参考从零实现Word2Vec[^2]。
在CBOW模型的参数中,矩阵 W W W和 W ′ W^\prime W′都可以作为词向量矩阵,它们分别描述了词典中的词在作为目标词或上下文词的不同性质。在实际中通常只用 W W W就可以满足应用需求。
在介绍Skip-gram模型之前,我们先来实现已经学习的CBOW模型。
代码实现
在实现上面的权重矩阵 W W W时,可以基于没有偏置的线性层Linear来实现,这样输入就如上面所说的one-hot向量。但是还有一种更常用的实现,那么就是通过嵌入层Embedding。
如果通过one-hot向量加线性层实现,就是用one-hot向量与 W W W进行矩阵运算,实际上就是取的 W W W中的第 k k k行,假设one-hot向量中第 k k k个元素为 1 1 1。那么与其进行这么复杂的运算,不如直接传入索引 k k k,拿到 W W W的第 k k k行。嵌入层就是实现这个功能的。
嵌入层的实现
class Embedding(Module):
def __init__(self, num_embeddings: int, embedding_dim: int, _weight: Optional[Tensor] = None,
dtype=None, device=None) -> None:
'''
一个存储固定大小词汇表嵌入的查找表,可以通过索引(列表)直接访问,而不是one-hot向量。
:param num_embeddings: 词汇表大小
:param embedding_dim: 嵌入维度
'''
super(Embedding, self).__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
# 也可以传预训练好的权重进来
if _weight is None:
self.weight = Parameter(Tensor.empty((num_embeddings, embedding_dim), dtype=dtype, device=device))
self.reset_parameters()
else:
assert list(_weight.shape) == [num_embeddings, embedding_dim], \
'Shape of weight does not match num_embeddings and embedding_dim'
self.weight = Parameter(_weight, device=device)
def reset_parameters(self) -> None:
init.uniform_(self.weight)
def forward(self, input: Tensor) -> Tensor:
return F.embedding(self.weight, input)
@classmethod
def from_pretrained(cls, embeddings: Tensor, freeze=True):
assert embeddings.ndim == 2, \
'Embeddings parameter is expected to be 2-dimensional'
rows, cols = embeddings.shape
embedding = cls(num_embeddings=rows, embedding_dim=cols, _weight=embeddings)
embedding.weight.requires_grad = not freeze
return embedding
代码也不复杂,这里还提供了从已经训练好的权重中加载的功能。在forward中直接调用embedding函数。显然核心逻辑在该函数里面,我们来实现看。
class Embedding(Function):
def forward(ctx, weight: NdArray, indices: NdArray) -> NdArray:
ctx.save_for_backward(weight.shape, indices)
return weight[indices]
def backward(ctx, grad: NdArray) -> Tuple[NdArray, None]:
w_shape, indices = ctx.saved_tensors
xp = get_array_module(grad)
bigger_grad = xp.zeros(w_shape, dtype=grad.dtype)
if xp is np:
np.add.at(bigger_grad, indices, grad)
else:
bigger_grad.scatter_add(indices, grad)
# 因为它有两个输入,防止错误地拆开bigger_grad
# indices 不需要梯度
return bigger_grad, None
def embedding(weight: Tensor, indices: Tensor) -> Tensor:
return Embedding.apply(Embedding, weight, indices)
实现起来类似我们之前的slice函数,毕竟操作上本质是一样的嘛。
当然还有必不可少的单元测试,相关代码请参考完整代码。
那么接下来我们就可以实现CBOW模型了。
模型实现
首先我们要构建词典:
BOS_TOKEN = "" # 句子开始标记
EOS_TOKEN = "" # 句子结束标记
PAD_TOKEN = "" # 填充标记
UNK_TOKEN = "" # 未知词标记
class Vocabulary:
def __init__(self, tokens=None):
self._idx_to_token = list()
self._token_to_idx = dict()
# 如果传入了去重单词列表
if tokens is not None:
if UNK_TOKEN not in tokens:
tokens = tokens + [UNK_TOKEN]
# 构建id2word和word2id
for token in tokens:
self._idx_to_token.append(token)
self._token_to_idx[token] = len(self._idx_to_token) - 1
self.unk = self._token_to_idx[UNK_TOKEN]
@classmethod
def build(cls, text, min_freq=2, reserved_tokens=None):
'''
构建词表
:param text: 处理好的(分词、去掉特殊符号等)text
:param min_freq: 最小单词频率
:param reserved_tokens: 预先保留的标记
:return:
'''
token_freqs = defaultdict(int)
for sentence in text:
for token in sentence:
token_freqs[token] += 1
unique_tokens = [UNK_TOKEN] + (reserved_tokens if reserved_tokens else [])
unique_tokens += [token for token, freq in token_freqs.items() \
if freq >= min_freq and token != UNK_TOKEN]
return cls(unique_tokens)
def __len__(self):
return len(self._idx_to_token)
def __getitem__(self, token):
'''得到token对应的id'''
return self._token_to_idx.get(token, self.unk)
def token(self, idx):
assert 0 <= idx < len(self._idx_to_token)
'''根据索引获取token'''
return self._idx_to_token[idx]
def to_ids(self, tokens):
return [self[token] for token in tokens]
def to_tokens(self, indices):
return [self._idx_to_token[index] for index in indices]
然后我们需要自定义数据集:
class CBOWDataset(Dataset):
def __init__(self, corpus, vocab, window_size=2):
self.data = []
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
for sentence in tqdm(corpus, desc='Dataset Construction'):
sentence = [self.bos] + sentence + [self.eos]
# 如果句子长度不足以构建(上下文,目标词)训练样本,则跳过
if len(sentence) < window_size * 2 + 1:
continue
for i in range(window_size, len(sentence) - window_size):
# 分别取i左右window_size个单词
context = sentence[i - window_size:i] + sentence[i + 1:i + window_size + 1]
# 目标词:当前词
target = sentence[i]
self.data.append((context, target))
self.data = np.asarray(self.data)
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
@staticmethod
def collate_fn(examples):
'''
自定义整理函数
:param examples:
:return:
'''
inputs = Tensor([ex[0] for ex in examples])
targets = Tensor([ex[1] for ex in examples])
return inputs, targets
构建(上下文,目标词)训练样本,并且实现自定义的整理函数。
下面我们就可以构建模型了,
class CBOWModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
# 词向量层,即权重矩阵W
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 输出层,包含权重矩阵W'
self.output = nn.Linear(embedding_dim, vocab_size, bias=False)
def forward(self, inputs: Tensor) -> Tensor:
# 得到所有上下文嵌入向量
embeds = self.embeddings(inputs)
# 计算均值,得到隐藏层向量,作为目标词的上下文表示
hidden = embeds.mean(axis=1)
output = self.output(hidden)
return output
参考上面的描述图,其实就是两个权重矩阵。我们一个用嵌入层实现,另一个用不带偏置项的线性层实现。
在训练之前,我们需要构建词典对象,和处理好的语料。
def load_corpus(corpus_path):
'''
从corpus_path中读取预料
:param corpus_path: 处理好的文本路径
:return:
'''
with open(corpus_path, 'r', encoding='utf8') as f:
lines = f.readlines()
# 去掉空行,将文本转换为单词列表
text = [[word for word in sentence.split(' ')] for sentence in lines if len(sentence) != 0]
# 构建词典
vocab = Vocabulary.build(text, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN])
print(f'vocab size:{len(vocab)}')
# 构建语料:将单词转换为ID
corpus = [vocab.to_ids(sentence) for sentence in text]
return corpus, vocab
最后就可以开始训练了:
embedding_dim = 64
window_size = 3
batch_size = 2048
num_epoch = 2000
min_freq = 3 # 保留单词最少出现的次数
corpus, vocab = load_corpus('../../data/xiyouji.txt', min_freq)
# 构建数据集
dataset = CBOWDataset(corpus, vocab, window_size=window_size)
data_loader = DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=True
)
device = cuda.get_device("cuda:0" if cuda.is_available() else "cpu")
print(f'current device:{device}')
loss_func = CrossEntropyLoss()
# 构建模型
model = CBOWModel(len(vocab), embedding_dim)
model.to(device)
optimizer = SGD(model.parameters(), 1)
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f'Training Epoch {epoch}'):
inputs, targets = [x.to(device) for x in batch]
optimizer.zero_grad()
output = model(inputs)
loss = loss_func(output, targets)
loss.backward()
optimizer.step()
total_loss += loss
print(f'Loss: {total_loss.item():.2f}')
save_pretrained(vocab, model.embeddings.weight, 'cbow.vec')
数据集采用的是《西游记》,经过分词、去掉标点符号预处理。
能看到这里的都是粉丝,这里直接放出处理好的数据集。
数据集下载 → 提取码:nap4
为了加速,我们使用GPU进行训练。所配的参数如下:
embedding_dim = 64
window_size = 3
batch_size = 2048
num_epoch = 2000
min_freq = 3
最终的Loss为:800+
实验效果:
> search('观音', embeddings, vocab)
故此: 0.5987884141294884
观音菩萨: 0.5976461631931431
菩萨: 0.5212316212655066
> search('孙悟空', embeddings, vocab)
齐天大圣: 0.5778116509661732
名字: 0.5639390829512272
那方: 0.5528188565550192
> search('呆子', embeddings, vocab)
八戒: 0.6547101716347253
行者: 0.6176272985497067
沙僧: 0.5527797715535391
> search('如来', embeddings, vocab)
佛祖: 0.7029674765576888
佛: 0.5874278308846846
菩萨: 0.5716678406707916
> search('唐僧', embeddings, vocab)
长老: 0.7743582601251642
圣僧: 0.7191300108695816
那怪: 0.6567922349528186
训练好的模型下载 → 提取码: p7ye
测试方法,运行examples/embeddings/load_and_test.py即可。
Skip-gram模型
CBOW模型使用上下文窗口词中的集合作为输入来预测目标词,即 P ( w t ∣ C t ) P(w_t|C_t) P(wt∣Ct)。而Skip-gram模型是根据当前词 w t w_t wt来预测上下文词 C t C_t Ct。
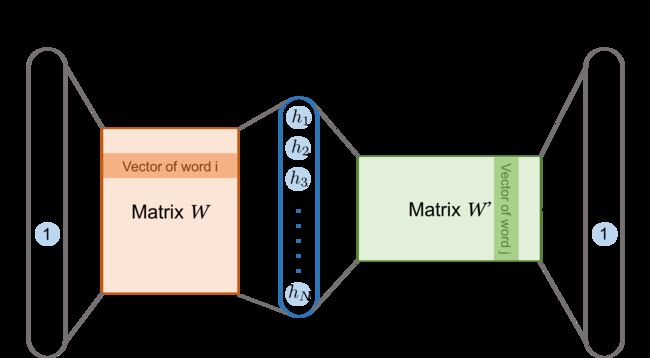
这里给定词典大小为 V V V,输入向量 x x x和输出向量 y y y都是维度为 V V V的独热编码。隐藏层的大小为 N N N,表示得到的词嵌入维度。
输入层 这里也以窗口大小 k = 2 k=2 k=2为例,输入 w i ∈ R V × 1 w_i \in R^{V \times 1} wi∈RV×1是 V V V维的独热编码,也记为 w t w_t wt。
隐藏层 w t w_t wt通过矩阵 W ∈ R N × V W \in R^{N \times V} W∈RN×V投影到隐藏层,这里隐藏层向量即为 w t w_t wt的词向量 v w t ∈ R N × 1 v_{w_t} \in R^{N \times 1} vwt∈RN×1:
v w t = W T x (6) v_{w_t} = W^Tx \tag 6 vwt=WTx(6)
输出层 输出层利用线性变换矩阵 W ′ W^\prime W′对上下文窗口内的单词进行预测:
具体做法是,假设 v c ′ v_c^\prime vc′某个上下文单词在 W ′ ∈ R N × V W^\prime \in R^{N \times V} W′∈RN×V中对应的列向量,维度为 N × 1 N \times 1 N×1。那么也是用当前词的词向量 v w t v_{w_t} vwt与上下文单词的词向量 v c ′ v^\prime_c vc′做一个点积,得到一个数值作为得分,也可以看成相似度。
那么我们也可以一次计算词典中所有单词的得分(其实就是公式 ( 8 ) (8) (8)中的:
u = W ′ T ⋅ v w t (7) u = W^{\prime T} \cdot v_{w_t} \tag 7 u=W′T⋅vwt(7)
得到的 u ∈ R V × 1 u \in R^{V \times 1} u∈RV×1,每个元素代表对应单词与当前词的相似得分,最终经过Softmax得到一个概率分布。若展开来看,那么由中心词计算上下文词 c c c的概率为:
P ( c ∣ w t ) = exp ( v w t ⋅ v c ′ ) ∑ w ′ exp ( v w t ⋅ v w ′ ′ ) (8) P(c|w_t) = \frac{\exp(v_{w_t} \cdot v_c^\prime)}{\sum_{w^\prime} \exp(v_{w_t} \cdot v^\prime_{w^\prime})} \tag 8 P(c∣wt)=∑w′exp(vwt⋅vw′′)exp(vwt⋅vc′)(8)
其中 c ∈ { w t − 2 , w t − 1 , w t + 1 , w t + 2 } c \in \{w_{t-2},w_{t-1},w_{t+1},w_{t+2}\} c∈{wt−2,wt−1,wt+1,wt+2}。
损失函数
Skip-gram模型的负对数似然损失函数为:
L ( θ ) = − ∑ t = 1 T ∑ − k ≤ j ≤ k , j ≠ 0 log P ( w t + j ∣ w t ) (9) L(\theta) = - \sum_{t=1}^T \sum_{-k \leq j \leq k, j\neq 0} \log P(w_{t+j}|w_t) \tag 9 L(θ)=−t=1∑T−k≤j≤k,j=0∑logP(wt+j∣wt)(9)
即希望基于 w t w_t wt预测得到的上下文单词 w t + j w_{t+j} wt+j出现的概率越高越好。
代码实现
有了上面的基础,我们直接进行模型实现。
Skip-gram模型的输入输出与CBOW模型接近,主要区别在于Skip-gram的输入输出都是单个单词,即在一定上下文窗口大小内共现的词对,而CBOW模型的输入是多个上下文单词与一个中心词组成的词对。
我们首先构建这种数据集:
class SkipGramDataset(Dataset):
def __init__(self, corpus, vocab, window_size=2):
self.data = []
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
for sentence in tqdm(corpus, desc='Dataset Construction'):
sentence = [self.bos] + sentence + [self.eos]
for i in range(1, len(sentence) - 1):
# 模型输入:当前词
w = sentence[i]
# 模型输出: 窗口大小内的上下文
# max 和 min 防止越界取到非预期的单词
left_context_index = max(0, i - window_size)
right_context_index = min(len(sentence), i + window_size)
context = sentence[left_context_index:i] + sentence[i + 1:right_context_index + 1]
self.data.extend([(w, c) for c in context])
self.data = np.asarray(self.data)
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
@staticmethod
def collate_fn(examples):
'''
自定义整理函数
:param examples:
:return:
'''
inputs = Tensor([ex[0] for ex in examples])
targets = Tensor([ex[1] for ex in examples])
return inputs, targets
从代码可以看出,假设窗口大小为 k k k,那么我们一次就得到了 2 k 2k 2k个训练样本(中心词,上下文词)。所以还是单类别多分类问题。
模型实现就更简单了,不需要求均值:
class SkipGramModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.output = nn.Linear(embedding_dim, vocab_size)
def forward(self, inputs: Tensor) -> Tensor:
# 得到输入词向量
embeds = self.embeddings(inputs)
# 根据输入词向量,对上下文进行预测,得到每个单词的得分,但是我们只关注样本中与中心词对应的上下文词的得分,期望越高越好。
output = self.output(embeds)
return output
最后的训练代码为:
embedding_dim = 64
window_size = 3
batch_size = 1024
num_epoch = 10
min_freq = 3 # 保留单词最少出现的次数
# 读取文本数据,构建Skip-gram模型训练数据集
corpus, vocab = load_corpus('data/xiyouji.txt', min_freq)
dataset = SkipGramDataset(corpus, vocab, window_size=window_size)
data_loader = DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=True
)
loss_func = CrossEntropyLoss()
# 构建Skip-gram模型,并加载至device
device = cuda.get_device("cuda:0" if cuda.is_available() else "cpu")
model = SkipGramModel(len(vocab), embedding_dim)
model.to(device)
optimizer = SGD(model.parameters(), lr=1)
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):
inputs, targets = [x.to(device) for x in batch]
optimizer.zero_grad()
output = model(inputs)
loss = loss_func(output, targets)
loss.backward()
optimizer.step()
total_loss += loss
print(f"Loss: {total_loss.item():.2f}")
完整代码
https://github.com/nlp-greyfoss/metagrad
References
- Learning Word Embedding
- 从零实现Word2Vec
- 自然语言处理:基于预训练模型的方法
- Speech and Language Processing