点云深度学习系列博客(二): 点云配准网络PCRNet
目录
一. 简介
二. 基础结构
三. 项目代码
四. 实验结果
总结
Reference
今天的点云深度学习系列博客为大家介绍一个用于点云配准的深度网络:PCRNet [1]。凡是对点云相关应用有些了解的同学,相信都接触过点云配准。配准相关的经典算法,包括ICP,NDT,FPFH,已被广泛应用于工业设计,三维定位,SLAM,自动驾驶等领域。尤其在SLAM和自动驾驶领域,随着家庭清扫机器人和电动汽车的普及,基于激光扫描技术的点云配准技术得以快速发展,并在实际应用中实现部署,可见相关研究的经济价值。自ICP算法被提出,虽然点云配准已经被研究了几十年时间,一些技术难点仍然没有被解决,包括尺度归一化,点对应,局部最优,噪声与点云缺失以及计算效率问题等。PCRNet基于PointNet点云深度学习架构,提出了一个新的点云配准方案。该方案针对噪声鲁棒性,计算速度等问题,提供了新的解决思路,相对于传统方法获得了一定的性能提升。接下来,而我们就来具体探讨一下PCRNet的一些技术细节。
一. 简介
将深度学习的相关工具用于解决点云配准的问题,存在两个难点,第一,如何有效的建立针对点云的表示形式,以适应网络学习;第二,如何建立有效的迭代优化方法,使得配准过程能够利用深度学习强大的特征分析能力。针对第一个问题,2019年前后的配准工作,主要是基于PointNet对点云编码来解决。由于PointNet利用池化技术,有效的提取了点云的全局特征。基于这种全局特征,点云能够被表示为一个与点顺序无关的向量形式。这个过程相当于对点云进行了一次无序编码,使得编码后的特征向量继承了点云的全局特征与语义信息。针对第二个问题,之前的工作还是使用传统的优化方法,如牛顿法,ICP,梯度下降,LK算法等,针对编码后的特征向量实现姿态对齐。主要缺点就是没有利用深度学习来实现对变换矩阵的求解,整个计算过程的效率还是比较低的。
PCRNet的提出,尝试使用一个基于全连接层的深度网络结构,直接输出基于7个参数表示的变换矩阵。因为没有使用传统的姿态优化,而是直接利用全连接层求解变换矩阵,其优点在于计算效率高,有效的学习了大规模样本的配准规律,且对噪声的鲁棒性具备一定优势。下面我们就来介绍下PCRNet的基础结构。
二. 基础结构
PCRNet分为两个部分,第一部分基本等同于PointNet全局特征提取结构,分别由几个MLP组成,数据维度分别变换为(64,64,64,128,1024)。到最后每一个点变换为一个1024维的特征向量,之后做最大池化,每一维取最大值,那么就从一个n*3的点云变成1*1024的特征向量。配准的输入是两个点云,因此就会得到两个1024维的向量,将二者结合,就变成了一个2048维的向量,至此,基于PointNet的编码过程完成,图1展示了该过程。

图1. 基于PointNet的点云编码过程。
比较关键的是第二部分,即PCRNet基于编码的变换矩阵求解过程。这里,PCRNet基于全连接层结构设计了一个神经网络,直接求解变换矩阵。网络结构如下:
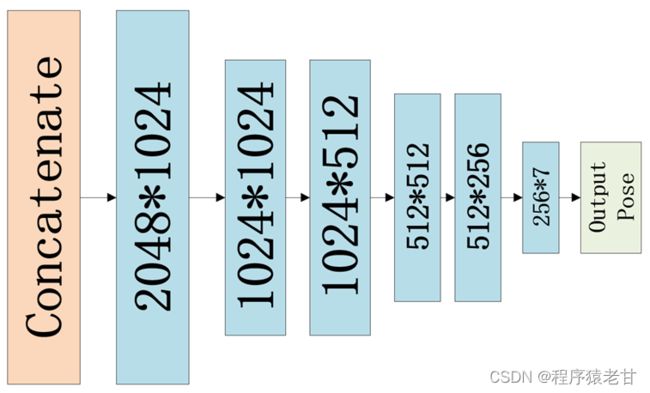
图2. 用于求解变换矩阵的全连接层神经网络。
由上图可知,该结构包含五个隐藏层,维度变换为(1024,1024,512,512,256,7)。最后的输出是一个7维的特征矩阵,表示变换矩阵相关的7个参数,前三个用于表示平移,后四个用于表示角度(不知道为啥用4个参数表示角度,感觉3个也没有问题)。基于该结构,PCRNet通过训练能够直接输出变换矩阵。
Loss Function选择使用EMD距离计算,其公式表示如下:

该公式求一个双射函数 ψ,使得基于该函数的点对距离和取最小。EMD的定义是清楚的,相对于最近点距离以及豪斯多夫距离,对点云对应关系的衡量更准确。EMD的计算效率较低,这种针对双射的优化过程,其计算开销必然远超其他度量方法。不过对于训练过程无所谓,因为训练时间开销再大,也不会影响测试过程。参数一旦被确定,实际计算效率仍然是线性的。
类似于PointNetLK中的LK算法以及ICP,对于变换矩阵的求解过程,仍然是一个迭代的过程。经过每一轮求解得到的变换矩阵,将源点云按照变换矩阵进行变换,然后重新输入PointNet提取全局特征,然后继续求解新的变换矩阵。经过一系列的迭代,直到收敛。T为变换矩阵迭代过程。图3展示了变换矩阵的求解过程。


图3. 变换矩阵求解过程。
至此,我们介绍了PCRNet的基础机构以及求解过程。可以看到,其整个过程都是基于MLP以及全连接层来实现优化与计算的,这样就让整个配准过程的计算开销维持在线性水平,进而保证了算法的计算效率。
三. 项目代码
项目主页:https://vinitsarode.weebly.com/pcrnet.html
代码链接:GitHub - vinits5/pcrnet: Point Cloud Registration Network
PCRNet初始化代码:
self.feature_model = feature_model
self.pooling = Pooling(pooling)
self.linear = [nn.Linear(self.feature_model.emb_dims * 2, 1024), nn.ReLU(),
nn.Linear(1024, 1024), nn.ReLU(),
nn.Linear(1024, 512), nn.ReLU(),
nn.Linear(512, 512), nn.ReLU(),
nn.Linear(512, 256), nn.ReLU()]
if droput>0.0:
self.linear.append(nn.Dropout(droput))
self.linear.append(nn.Linear(256,7))
self.linear = nn.Sequential(*self.linear)feature_model传入的就是PointNet,后边的Linear用来表示变换矩阵的全连接层。
更新代码:
self.source_features = self.pooling(self.feature_model(source))
y = torch.cat([template_features, self.source_features], dim=1)
pose_7d = self.linear(y)
pose_7d = transform.create_pose_7d(pose_7d)
# Find current rotation and translation.
identity = torch.eye(3).to(source).view(1,3,3).expand(batch_size, 3, 3).contiguous()
est_R_temp = transform.quaternion_rotate(identity, pose_7d).permute(0, 2, 1)
est_t_temp = transform.get_translation(pose_7d).view(-1, 1, 3)
# update translation matrix.
est_t = torch.bmm(est_R_temp, est_t.permute(0, 2, 1)).permute(0, 2, 1) + est_t_temp
# update rotation matrix.
est_R = torch.bmm(est_R_temp, est_R)
source = transform.quaternion_transform(source, pose_7d) # Ps' = est_R*Ps + est_t首先用feature_model对source做一步全局特征提取,池化后作为输入到已经定义好的Linear结构,即针对全连接层的姿态优化结构。可以看到,Linear的输出是一个pose_7d,即由7个参数表示的变换矩阵。之后,按照pose_7d变换source,并记录变换矩阵的信息即可。
这里特别说下EMD计算:
def chamfer_distance(template: torch.Tensor, source: torch.Tensor):
from .cuda.chamfer_distance import ChamferDistance
cost_p0_p1, cost_p1_p0 = ChamferDistance()(template, source)
cost_p0_p1 = torch.mean(torch.sqrt(cost_p0_p1))
cost_p1_p0 = torch.mean(torch.sqrt(cost_p1_p0))
chamfer_loss = (cost_p0_p1 + cost_p1_p0)/2.0
return chamfer_loss这里作者给出了一个基于Cuda的实现,即函数ChamferDistance()
class ChamferDistanceFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, xyz1, xyz2):
batchsize, n, _ = xyz1.size()
_, m, _ = xyz2.size()
xyz1 = xyz1.contiguous()
xyz2 = xyz2.contiguous()
dist1 = torch.zeros(batchsize, n)
dist2 = torch.zeros(batchsize, m)
idx1 = torch.zeros(batchsize, n, dtype=torch.int)
idx2 = torch.zeros(batchsize, m, dtype=torch.int)
if not xyz1.is_cuda:
cd.forward(xyz1, xyz2, dist1, dist2, idx1, idx2)
else:
dist1 = dist1.cuda()
dist2 = dist2.cuda()
idx1 = idx1.cuda()
idx2 = idx2.cuda()
cd.forward_cuda(xyz1, xyz2, dist1, dist2, idx1, idx2)
ctx.save_for_backward(xyz1, xyz2, idx1, idx2)
return dist1, dist2
@staticmethod
def backward(ctx, graddist1, graddist2):
xyz1, xyz2, idx1, idx2 = ctx.saved_tensors
graddist1 = graddist1.contiguous()
graddist2 = graddist2.contiguous()
gradxyz1 = torch.zeros(xyz1.size())
gradxyz2 = torch.zeros(xyz2.size())
if not graddist1.is_cuda:
cd.backward(
xyz1, xyz2, gradxyz1, gradxyz2, graddist1, graddist2, idx1, idx2
)
else:
gradxyz1 = gradxyz1.cuda()
gradxyz2 = gradxyz2.cuda()
cd.backward_cuda(
xyz1, xyz2, gradxyz1, gradxyz2, graddist1, graddist2, idx1, idx2
)
return gradxyz1, gradxyz2
class ChamferDistance(torch.nn.Module):
def forward(self, xyz1, xyz2):
return ChamferDistanceFunction.apply(xyz1, xyz2)整个过程我没有看懂。直观的感觉,这段代码像是动态规划的一种实现,包括前传后传,还用了递归,确实算了不少东西,最后得到双射结果。整个计算过程应该是利用了Cuda并行计算的,否则计算开销实在是太大了。
四. 实验结果
作者给出两个实验对比图,证明在噪声干扰以及数据分布不均匀的双重影响下,PCRNet的性能显著好于ICP。
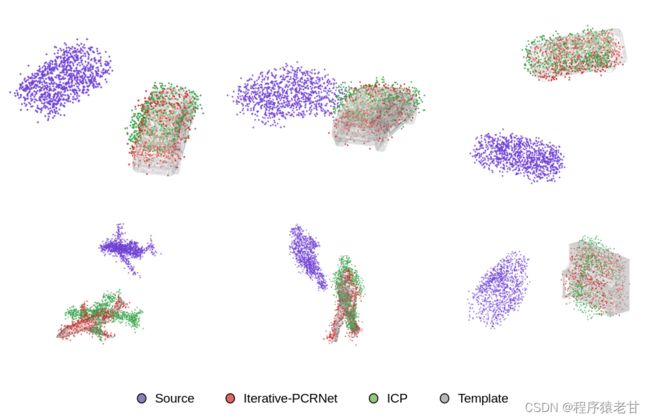

基于配准结果的对象替换:



作者还给出了PCRNet与ICP、PointNetLK的迭代对比结果,如下如:
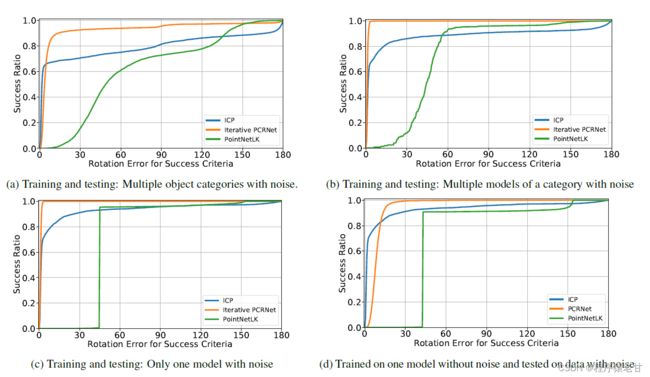
可以看到,PCRNet能够在收敛速度更快,误差更小。
总结
对于配准任务来说,PCRNet针对变换矩阵的求解还是有一些新意的。脱离传统的ICP,NDT以及LK算法的帮助,利用全连接层直接对变换矩阵求解,不得不说是一个大胆的尝试。经过实验可以看到,PCRNet充分利用了深度学习高效的计算能力,以获得结果。然而,在实际使用中,该算法的泛化性较差。我认为其原因在于,PCRNet并没有解决变换矩阵的求解问题。基于一个大的样本库,并且包含各种各样的姿态,利用深度学习获得一个全局最优的结果,听上去是一个可行的方案。但我们不能保证训练数据能够很好的覆盖各种姿态,各种位置。一旦实际数据的分布不满足训练数据的样本特性,或者训练数据的变换本来就存在较大的偏见,其实际性能就会打折。我个人认为,未来的改进思路还是要放在点对应上。基于深度学习建立更好的点特征描述,并建立基于特征描述的点对应。这样,有了更好的对应关系,就能够利用ICP或者SVD来计算变换矩阵。直接利用网络结构求解变换矩阵,直观感觉还是有些激进,不太看好这条技术路线。
Reference
[1] V. Sarode, X. Li, H. Goforth, et al. Pcrnet: Point cloud registration network using pointnet encoding[J]. arXiv preprint arXiv:1908.07906, 2019.