【论文笔记(3)】Attention Is All You Need
目录
- Ⅰ 论文信息
- Ⅱ 论文框架
-
- 1 Introdcution
- 2 Background
- 3 Model Architecture
-
- 3.1 Encoder and Decoder Stacks
- 3.2 Attention
-
- 3.2.1 Scaled Dot-Product Attention
- 3.2.2 Multi-Head Attention
- 3.2.3 Applications of Attention in our Model
- 3.3 Position-wise Feed-Forward Networks
- 3.4 Embeddings and Softmax
- 3.5 Positional Encoding
- 4 Why Self-Attention
- 5 Training
-
- 5.3 Optimizer
Ⅰ 论文信息
《Attention is All You Need》是由谷歌团队2017年发表在NIPS上的文章,是具有超高引用的重要文章。
这篇文章提出了鼎鼎大名的Transformer,一个仅仅基于注意力机制的序列模型。该模型更具有并行性,需要的训练时间更短。
Ⅱ 论文框架
1 Introdcution
注意力机制过去常常与RNN一起使用,被用于将编码器的输出有效地传递给解码器。
本文提出的Tranformer是首个用注意力机制替代了RNN的模型。
2 Background
本部分主要讲述有哪些相关论文,相关论文与本文有什么联系,以及本文与相关论文的区别。
-
为了模拟CNN中多通道输出的效果,本文使用了multi-head attention。
因为对于CNN来说,学习远距离位置之间的dependencies比较困难,需要很多次operations,而Transformer将远距离学习降低到常数步的操作,减少了计算量。 -
Self-attention (intra-attention)
自注意力机制是一个attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence。
3 Model Architecture
- 自回归:过去时刻的输出会作为当前时刻的输入
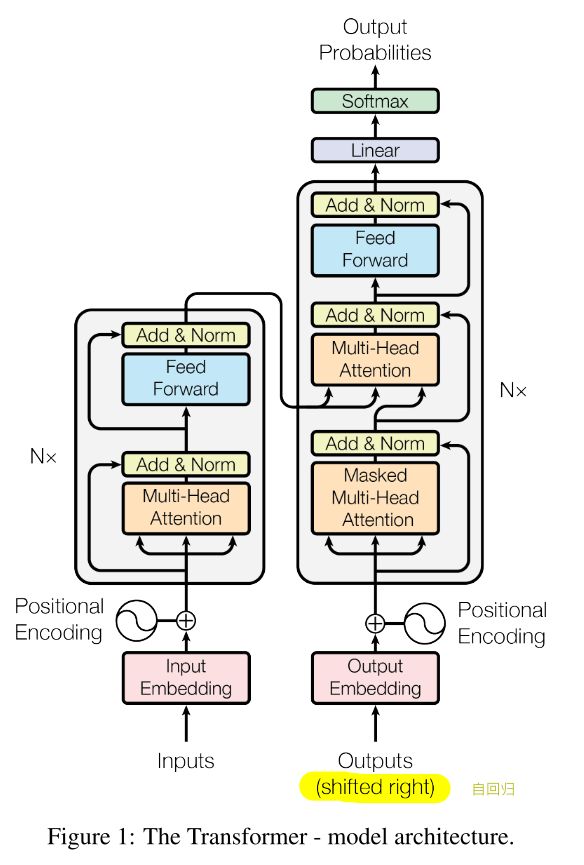
Transformer模型的架构分为左边的encoder和右边的decoder两个部分。
3.1 Encoder and Decoder Stacks
ENCODER:
- 由 N=6 个相同的layer堆叠而成,每个layer分成2个sub-layers
- 第一个子层为 multi-head self-attention mechanism
- 第二个子层为 MLP
- 对于每个子层,都使用了 residual connection+layer nomalization
- 为了便于残差连接,模型中所有子层的输出维度 d m o d e l = 512 d_{model}=512 dmodel=512
- 每个子层的输出都是 L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x + Sublayer(x)) LayerNorm(x+Sublayer(x))
DECODER:
- 由 N=6 个相同的layer堆叠而成,每个layer分成3个sub-layers
- 第一个子层为 masked multi-head attention
- 第二个子层为 multi-head attention,作用于encoder的输出
- 第三个子层为 MLP
- masking可以避免当前位置关注到之后位置的信息,确保当前的输出只取决于此刻及以前的信息
3.2 Attention
- 注意力函数
- 定义: mapping a query and a set of key-value pairs to an output
- 输出是 value 的加权和
- 赋给每个 value 的权重与 query 和 相应 key 的相似程度有关
3.2.1 Scaled Dot-Product Attention

Scaled Dot-Product Attention的输出为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
Q: n × d k d_k dk ; K: m × d k d_k dk ; V: m × d v d_v dv (n = m = d m o d e l d_{model} dmodel)
本文在 additive attention 和 dot-product attention 两种常用的注意力函数中选择了计算更为简单的 dot-product attention,并添加了 scaling factor 1 d k \frac{1}{\sqrt{d_k}} dk1, d k d_k dk为 key 和 query 的维度。
缩放因子的作用在于当 d k d_k dk 很大的时候,dot product的值会很大,导致softmax的值非常接近0或1,梯度非常小,使得模型的收敛很缓慢,为了加快模型的收敛,添加了缩放因子。
3.2.2 Multi-Head Attention

相较于采用 d m o d e l d_{model} dmodel 维度的K, Q, V的单一注意力函数,本文认为将K,Q,V用多个不同线性映射函数并行地进行 h h h次线性映射得到 d k d_k dk, d k d_k dk, d v d_v dv维度会效果更好。
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O MultiHead(Q, K, V) = Concat(head_1, ... , head_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) where\ head_i = Attention(QW^Q_i, KW^K_i, VW^V_i) where headi=Attention(QWiQ,KWiK,VWiV)
![]()
多头注意力机制允许模型 jointly attend to information from different representation subspaces at different positions
3.2.3 Applications of Attention in our Model
The Transformer uses multi-head attention in three different ways:
- 解码器的第二子层:
- Q 来自于前一个解码器子层,K, V 来自编码器的输出
- 解码器中的每个位置都能关注到输入序列中的所有位置
- 编码器的第一子层:
- 是自注意力层,K, Q, V都是一样的,来自编码器的前一层
- 解码器的第一子层:
- 掩码自注意力层,允许解码器中的每个位置关注此前和包括自身在内的所有位置(看不到自身之后的位置)
3.3 Position-wise Feed-Forward Networks
本质就是简单的MLP:
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0, xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
输入输出的维度是 d m o d e l = 512 d_{model}=512 dmodel=512,内层的维度 d f f = 2048 d_{ff}=2048 dff=2048。
3.4 Embeddings and Softmax
在两个 embedding layer 和 pre-softmax linear transformation 中共享同样的 weight matrix。 在 embedding layer 中,将这些权重乘以 d m o d e l \sqrt{d_{model}} dmodel。
3.5 Positional Encoding
为了利用 the order of the sequence,通过Positional Encoding注入relative or absolute position of the tokens in the sequence。
4 Why Self-Attention
不是很懂,大意就是将比于CNN和RNN,Transformer是最好的
5 Training
5.3 Optimizer
文章中用的是 Adam optimizer,学习率的设置很有意思:
l r a t e = d m o d e l − 0.5 ⋅ m i n ( s t e p _ n u m − 0.5 , s t e p _ n u m ⋅ w a r m u p _ s t e p s − 1.5 ) lrate=d_{model}^{-0.5} · min(step\_num^{-0.5},step\_num·warmup\_steps^{-1.5}) lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)
This corresponds to increasing the learning rate linearly for the first warmup_steps training steps, and decreasing it thereafter proportionally to the inverse square root of the step number. We used warmup_steps = 4000.