NLP自然语言处理——问答系统
NLP自然语言处理——问答系统
文章目录
- NLP自然语言处理——问答系统
- 前言
- 一、 基于搜索的问答系统
- 二、具体步骤
-
- 1.处理流程
-
- 1.1分词
-
- 1.1.1前向最大匹配(forward-max matching)
- 1.1.2后向最大匹配(next-max matching)
- 1.1.3 unigram 切分
- 1.1.4 Viterbi分词法
- 1.2预处理
-
- 1.2.1拼写纠错
- 1.2.2 steming
- 1.3文本表示(word representation)
-
- 1.3.1 one-hot representation
- 1.3.2 boolean representation
- 1.3.3 count representation
- 1.3.4 tf-idf representation
- 1.3.4 word2vec (分布式的表达方法)
- 1.4计算相似度
- 1.6倒排表
- 1.7返回结果
- 2.简单的问答系统
- 总结
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
一、 基于搜索的问答系统

二、具体步骤
1.处理流程
1.1分词
将单词进行分割,例如:How do you like NLPCamp?——>[how, do, you, like, NLPCamp]
1.1.1前向最大匹配(forward-max matching)
从句子前面开始截取,从后向前匹配最大的词语
例子:我们经常有意见分歧
词典:[“我们”,“经常”,“有”,“有意见”,“意见”,“分歧”]
python代码
dicts = ["我们","经常","有","有意见","意见","分歧"]
s = '我们经常有意见啊分歧啊'
def forword_max_match(s ,dicts, maxlen=5):
'''
params
s:String, split text
dicts:list, word dict
maxlen:int,the lentgh of one word
return list
'''
i = 0
l = len(s)
words = []
if l!=0:
while i < l:
j = i+maxlen if (i+maxlen) < l else l
while i < j:
if s[i:j] in dicts or i == j-1:#当分词出现在词典中或者就剩一个字时
words.append(s[i:j])
i = j
break
else:
j -= 1
return words
forword_max_match(s,dicts,5)
输出结果
['我们', '经常', '有意见', '啊', '分歧', '啊']
1.1.2后向最大匹配(next-max matching)
从句子后面开始截取,从前向前后配最大的词语
例子:我们经常有意见分歧
词典:[“我们”,“经常”,“有”,“有意见”,“意见”,“分歧”]
python代码
dicts = ["我们","经常","有","有意见","意见","分歧"]
s = '我们经常有意见啊分歧啊'
def next_max_match(s ,dicts, maxlen=5):
'''
params
s:String, split text
dicts:list, word dict
maxlen:int,the lentgh of one word
return list
'''
l = len(s)
i = l
words = []
if l!=0:
while i > 0:
j = i-maxlen if (i-maxlen) > 0 else 0
while i > j:
if s[j:i] in dicts or i == j+1:#当分词出现在词典中或者就剩一个字时
words.append(s[j:i])
i = j
break
else:
j += 1
words.reverse()
return words
next_max_match(s,dicts,5)
输出结果
['我们', '经常', '有意见', '啊', '分歧', '啊']
提示: 前向和后向最大匹配有时候结果是不一样的
缺点:
- 不能细分,有时候最大匹配结果不是最好的(贪心未必最优)
- 不能考虑语义
- 复杂度和maxlen相关
1.1.3 unigram 切分
求最大所有出现在字典的可能分割概率的最大值
S = X 1 X4X4X4…Xn
P = p(X0-i1)p(X(i1+1)-i2)…P(X(in+1)-(l-1)) {Xik-im∈S,l = len(S}
由于P是概率连乘,所以P可能约等于0,所以加log
P = log(p(X0-i1))log(p(X(i1+1)-i2))…log(P(X(in+1)-(l-1))) {Xik-im∈S,l = len(S}
又由于分割的个数越多,P的值会越少,为了避免这种情况,将P取几何平均值,即
P = pow(P,1/len(words) {words为分割后单词列表}
最后求得max§
import re
import numpy as np
def cut_word(input_str,word_dict):
#只切一刀
a={}
l = len(input_str)
for i in range(l):#列举所有有前向匹配可能的组合
if(input_str[:l-i] in word_dict) or l-i==1:#l-i == 1默认一个字也可以是一个词
a[input_str[:l-i]]= l-i #记录切割位置
return a
def cutwords(input_str,word_dict,max_len=4):
#切割一刀后,等于切割前面的词组 + 切割位置后面的组合
dicts = []
arr = cut_word(input_str[:max_len],word_dict)#第一刀
if(arr=={}):
return [[]]
for d in arr:
v = cutwords(input_str[arr[d]:],word_dict,max_len)#后面的刀
for i in v:
i.append(d)
dicts.append(i)
return dicts
def word_segment_naive(input_str,word_dict,max_len=5, seps=''):
inputs = re.split(fr'[{seps}]\s*', input_str)#可以自己添加断句分隔符
words = []
for input_str in inputs:
res = cutwords(input_str,word_dict,max_len)
for i in range(len(res)):
res[i].reverse()
segment_p = []
best = 0
for k,i in enumerate(res):
p = 1
for j in i:
if(j not in word_dict):
word_dict[j] = 0.000001
p *= np.log10(word_dict[j])#防止数过大或过小
p = np.power(p, 1/len(i))#几何平均,否则词组月多概率越小
segment_p.append(p)
if(p>segment_p[best]):
best = k
words.extend(res[best])
return words
text = '今天北京的天气真好啊,今天北京的天气真好啊' # 保存词典库中读取的单词
word_prob = {'思':0.2,'京':0.01,"北京":0.02,"的":0.08,"天":0.005,"气":0.005,"天气":0.06,"真":0.04,"好":0.05,"真好":0.04,"啊":0.01,"真好啊":0.005,
"今":0.01,"今天":0.07,"课程":0.01,"内容":0.06,"有":0.05,"很":0.03,"很有":0.04,"意思":0.06,"有意思":0.005,"课":0.01,
"程":0.005,"经常":0.02,"意见":0.01,"意":0.01,"见":0.005,"有意见":0.005,"分歧":0.01,"分":0.02, "歧":0.005}
word_segment_naive(text,word_prob,max_len=4, seps=':,。?、; ‘“@#¥%……&*()”’\s')
输出结果
['今天', '北京', '的', '天气', '真好啊', '今天', '北京', '的', '天气', '真好啊']
缺点: 复杂度太高,递归算法导致有重复分割子串的现象,欢迎在下面评论新的算法解决复杂度问题
1.1.4 Viterbi分词法
以句子所有分割位点作为顶点(分割位点,如:"你好"有三个分割位点“|你|好|”,|代表分割位点),将词语的概率看做是边,那么问题就变成了了从开始到结尾的最短路径(将概率取负对数)
例:
词典︰[“经常”,“经”,“有”,“有意见”,“意见”,“分歧”,“见”,“意”,“见分歧”,“分”]
概率︰[ 0.1,0.05,0.1,0.1, 0.2,0.2, 0.05,0.05, 0.05, 0.1]
-log(x): [ 2.3, 3, 2.3, 2.3, 1.6, 1.6, 3, 3, 3, 2.3]
将分词转化为图模型,求最短路径
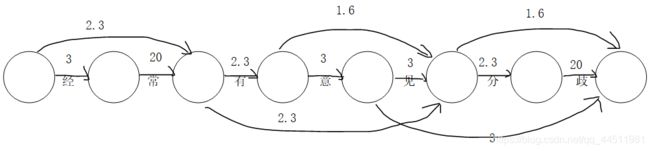
#构建矩阵存储边值
import numpy as np
def viterbi(s, dicts,max_len=4):
edges = []#构建矩阵存储边值
for i in range(len(s)):
edges.append([0 for _ in range(len(s))])
if s[i] in dicts:
edges[i][i] = -np.log2(dicts[s[i]])
else:
edges[i][i] = -np.log2(0.00001)
for j in range(1,max_len):
if(i+j+1>len(s)):
break
if s[i:i+j+1] in dicts:
edges[i][i+j] = -np.log2(dicts[s[i:i+j+1]] )
edges = np.array(edges)#第一个分位点到第一个分位点,因为是乘积的关系,设为1不影响大小
min_rode = {0:[[],1]}
return v(len(s),min_rode,edges)
def v(n,min_rode,edges):
if n in min_rode:
return min_rode[n]
else:
arr = []#存放所有可能路径和值
for i,k in enumerate(edges[:,n-1]):
if(k!=0):
a = v(i,min_rode,edges)
arr.append([a[0]+[s[i:n]], a[1]*k])
min_rode[n] = sorted(arr,key=lambda x:x[1])[0]#找到最短的
return min_rode[n]
viterbi(s, dicts,max_len=4)
输出结果
[['经常', '有意见', '分歧'], 25.622955465622145]
★中文分词工具 :Jieba分词、SnowNLP、LTP、HanNLP、FndaNLP(工具包虽好也要懂得基础原理)
1.2预处理
- spelling correction 拼写纠错
- stop words 停用词过滤(特定无意义的词)
- stemming:one way to normalize(时态归一化等)
- words filter 特殊词过滤
- 同义词替换
1.2.1拼写纠错
拼写纠错流程
寻找候选单词:
- 从编辑距离较小的寻找
- 从常用拼写错误词典寻找
从编辑距离较小的单词寻找
编辑距离:详解编辑距离(Edit Distance)及其代码实现
如果在词典里寻找编辑距离所有最小的单词,计算与每个词的编辑距离复杂度太高,所以可以先生成固定距离的编辑距离再去词典里寻找
生成编辑距离的单词
def edit_distance_words(word,distance=1):
error_words = []
if distance == 1:#计算编辑距离为1的
alpha = 'abcdefghigklmnopqrstuvwxyz'
add = [word[:i]+ j +word[i:] for i in range(len(word)) for j in alpha]
delete = [word[:i] + word[i+1:] for i in range(len(word))]
replace = [word[:i] + j + word[i+1:] for i in range(len(word)) for j in alpha]
return list(set(add+delete+replace))
else:
for i in edit_distance_words(word,distance-1):#编辑距离不为1的,对编辑距离减1的词在进行一次编辑距离为1的变换
error_words += edit_distance_words(i)
return list(set(error_words))
len(edit_distance_words('word',2))
输出结果
17360
拼写纠错练习
数据
- vocab.txt
- testdata.txt
- spell-error.txt
from nltk.corpus import reuters
import numpy as np
import re
vocb = set([line.strip() for line in open('vocab.txt')])
def generate_candidates(word):#生成编辑距离为1的单词
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[0:i],word[i:]) for i in range(len(word))]
inserts = [L+c+R for L,R in splits for c in letters]
deletes = [L+R[1:] for L,R in splits]
replaces = [L+c+R[1:] for L,R in splits for c in letters]
candidates = set(inserts+deletes+replaces)
return list(candidates)
categories = reuters.categories()
corpus = reuters.sents(categories=categories)
term_count = {}
bigram_count = {}
for doc in corpus:
doc = ['']+doc
for i in range(0,len(doc)-1):
term = doc[i]
bigram = doc[i:i+2]
if term in term_count:
term_count[term] += 1
else:
term_count[term] = 1
bigram = ' '.join(bigram)
if bigram in bigram_count:
bigram_count[bigram] += 1
else:
bigram_count[bigram] = 1
channel_prob = {}
for line in open('spell-error.txt'):
items = line.split(':')
corrent = items[0].strip()
mistakes = [item.strip() for item in items[1].strip().split(',')]
channel_prob[corrent] = {}
for i in mistakes:
channel_prob[corrent][i] = 1/len(mistakes)
V = len(term_count.keys())
file = open("testdata.txt", 'r')
for line in file:
items = line.strip().split('\t')
mis_mun = items[1]
mis_text = items[2]
mis_words = re.split(r'[\., \s]\s*',mis_text)
for mis_word in mis_words:
if mis_word not in vocb:
candidate = generate_candidates(mis_word)
if len(candidate) < 1:
continue
probs = []
for cand in candidate:
prob = 0
if cand in channel_prob and mis_word in channel_prob[cand]:
prob = np.log(channel_prob[cand][mis_word])
else:
prob += np.log(0.0001)
idx = mis_text.index(mis_word)+1
if mis_text[idx-1] in bigram_count and cand in bigram_count[mis_text[idx-1]]:
prob += np.log((bigram_count[mis_text[idx-1]][cand] + 1.0) / (term_count[bigram_count[mis_text[idx - 1]]] + V))
else:
prob += np.log(1.0 / V)
probs.append(prob)
max_idx = probs.index(max(probs))
print(mis_word, candidate[max_idx])
输出结果
protectionst kprotectionst
Tkyo's Tkyos's
retaiation retniation
Japan's Japman's
tases atases
wouldn't woyldn't
busines busiles
ltMC ltcMC
Taawin Taaswin
seriousnyss serisousnyss
aganst against
bililon bililocn
...
提示: 编辑距离为2的单词就已经非常多了
寻找最佳候选词
给定一个字符串s,我们要找出最有可能成为正确的字符串c,也就是 c = a r g m a x c ∈ c n a d i d a t e s p ( c ∣ s ) c = argmax_{c∈cnadidates}p(c|s) c=argmaxc∈cnadidatesp(c∣s) 贝 叶 斯 定 里 的 : 贝叶斯定里的: 贝叶斯定里的: c = a r g m a x c ∈ c n a d i d a t e s p ( s ∣ c ) p ( c ) / p ( s ) c= argmax_{c∈cnadidates}p(s|c)p(c)/p(s) c=argmaxc∈cnadidatesp(s∣c)p(c)/p(s) 由 于 p ( s ) 是 固 定 的 的 : 由于p(s)是固定的的: 由于p(s)是固定的的: c = a r g m a x c ∈ c n a d i d a t e s p ( s ∣ c ) p ( c ) c= argmax_{c∈cnadidates}p(s|c)p(c) c=argmaxc∈cnadidatesp(s∣c)p(c)
p(s|c)基于统计的计算得出,例如有多少人把c写成了s
p( c)文章中c出现的概率
1.2.2 steming
意思相同,单词的不同形式转化(根据具体的应用场景选择转化)
went,going,go -> go(时态)
fly, flies -> fly(单复数)
fast, faster,fastest ->fast(比较级)
PorterStemmer算法python版,可以自己下载用一用,这里就不在展示
1.3文本表示(word representation)
text->vector
- boolean vector
- count vector
- tf-idf
- word2vec
- seq2seq
1.3.1 one-hot representation
词典:[我们,去,爬山,今天,你们,昨天,跑步]
我们:[1,0,0,0,0,0,0]
爬山:[0,0,1,0,0,0,0]
…
特点:稀疏向量,只有一个为1,向量大小与词典大小相同,词与词之间相似度为0,无法表达语义。
1.3.2 boolean representation
句子表示,1代表出现过,0代表没有出现
词典:[我们,又,去,爬山,今天,你们,昨天,跑步]
我们今天去爬山:(1,0,1,1,1,0,0,0)
你们昨天跑步:(0,0,0,0,0,1,1,1)
你们又去爬山又去跑步:(0,1,1,1,0,1,0,1)
特点:无法考虑语序,无法表示单词出现个数
1.3.3 count representation
句子表示,m代表出现过m次
词典:[我们,又,去,爬山,今天,你们,昨天,跑步]
我们今天去爬山:(1,0,1,1,1,0,0,0)
你们昨天跑步:(0,0,0,0,0,1,1,1)
你们又去爬山又去跑步:(0,2,2,1,0,1,0,1)
特点:无法考虑语序,并不是出现个数越多就越重要
1.3.4 tf-idf representation
t f i d f ( w ) = t f ( d , w ) ∗ i d f ( w ) tfidf(w) = tf(d,w)*idf(w) tfidf(w)=tf(d,w)∗idf(w) t f ( d , w ) = 文 档 d 中 w 出 现 的 词 频 tf(d,w)=文档d中w出现的词频 tf(d,w)=文档d中w出现的词频 i d f ( w ) = l o g ( N / N ( w ) ) idf(w) = log(N/N(w)) idf(w)=log(N/N(w))
N:语料库中文档的总数
N(w):词语w出现在多少个文档
Idf代表单词重要性,出现在不同文档的数越多,越不重要
1.3.4 word2vec (分布式的表达方法)
分布式的单词表示方法,例如使用模型训练出100维度的向量(0.1,0.2,0.1…0.3),解决了词向量稀疏问题,而且100维就可以表达所有单词。
word2vec的方法(这里先挖个坑)
- skip-gram
- glove
- cbow
- RNN/LSTM
- MF
- Gaussian Embedding
1.4计算相似度
- 欧氏距离
d = ∣ S 1 − S 2 ∣ d = |S_1-S_2| d=∣S1−S2∣
缺点:向量是有方向的,欧式距离没有考虑方向
- 余弦相似度
d = S 1 S 2 / ( ∣ S 1 ∣ ∗ ∣ S 2 ∣ ) d = S_1 S_2/(|S_1|*|S_2|) d=S1S2/(∣S1∣∗∣S2∣)
- Jaccard 相似度

1.6倒排表
在我们计算相似度时,我们需要对输入的问题与每一个问题计算相似度,这样十分浪费时间,于是可以使用倒排表进行检索优化
词典:[key1,key2,key3,…keyn]
文档:[doc1,dco2,doc2,…docn]
key1:[doc1,doc5]
key2:doc2,doc4,doc6]
key3:[doc1,doc3,doc7]
…
当我们需要查找计算相似度时,直接计算与关键词相关的文档即可,不需要遍历每一个文档
1.7返回结果
- 直接返回相似最高的结果
- 过滤最高的几个
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.简单的问答系统
搭建一个问答系统做个练习吧
数据:
- 英语停用词
- 问答数据
代码如下(示例):
import json
#加载问题和答案
def load_data():
with open('问答系统.json', encoding='utf-8') as f:
data = json.load(f)
f.close()
data['data'][0]['paragraphs'][0]['qas'][0]['question']
data['data'][0]['paragraphs'][0]['qas'][0]['answers'][0]['text']
question = []
answers = []
for i in data['data']:
for j in i['paragraphs']:
for k in j['qas']:
question.append(k['question'])
answers.append(k['answers'])
stop_words = [line.strip('\n') for line in open('stop_words_English.txt', encoding='utf-8')]
return question,answers,stop_words
question,answers,stop_words = load_data()
#建立词典
import re
def count_word(question,answers,stop_words):
words_dict = {'NAN':0}
for i in question:
arr = re.split(r'[0-9\'<>\":;.\+\-\*\/,()?$:,。?、; ‘“@#¥%……&*()”’\s]\s*',i)
for j in arr:
j = j.lower()
if(j == ''):
continue
elif( j in stop_words):
words_dict['NAN'] += 1 #停用词过滤
elif (j in words_dict):
words_dict[j] += 1
else:
words_dict[j] = 1
# del_keys = [key for key in words_dict if words_dict[key]<=1]#删除低频单词
# [words_dict.pop(key) for key in del_keys]
words_dict['NAN'] = 11
return words_dict
words_dict = count_word(question,answers,stop_words)
#自己写的TfIdf效率有点低
import numpy as np
from scipy.sparse import lil_matrix
class TfidfVectorizer:
def __init__(self):
self.document = None
def fit_transform(self,document,words_dict):
self.words_dict = words_dict.copy()#词典
self.document = document#句子
self.N = len(words_dict)#句子个数
self.dict = {'NAN':10}#单词在不同句子的个数
self.words = []#切分后的单词
self.keys = {'NAN':0}
for i in document:
arr = re.split(r'[0-9\'<>\":;.\+\-\*\/,()?$:,。?、; ‘“@#¥%……&*()”’\s]\s*',i)
self.words.append(arr)
self.count_word_in_document()
self.data = []
for i in self.words:
s = lil_matrix((1,self.N),dtype=float)
count = {}
for word in i:
if word in count:
count[word] += 1
else:
count[word] = 1
for word in count:
if word in self.words_dict:
s[(0,self.keys[word])] = count[word] * np.log2(self.N/self.dict[word])
# else:
# s[(0,0)] += count[word] * np.log2(self.N/self.dict['NAN'])
self.data.append(s)
def count_word_in_document(self):
count = 1
for i in self.words:
i = list(set(i))
for word in i:
if word in self.words_dict:
if word in self.dict:
self.dict[word] += 1
else:
self.keys[word] = count
count += 1
self.dict[word] = 1
def tranform(self, s):
arr = re.split(r'[0-9\'<>\":;.\+\-\*\/,()?$:,。?、; ‘“@#¥%……&*()”’\s]\s*',s)
s = lil_matrix((1,self.N),dtype=float)
count = {}
for word in arr:
if word in count:
count[word] += 1
else:
count[word] = 1
for word in count:
if word in self.words_dict:
s[(0,self.keys[word])] = count[word] * np.log2(self.N/self.dict[word])
# else:
# s[(0,0)] += count[word] * np.log2(self.N/self.dict['NAN'])
return s
tf = TfidfVectorizer()
tf.fit_transform(question,words_dict)
w = tf.tranform('When did Beyonce start becoming popular?')
similary = []
for i in tf.data:
print(w.dot(i.T))#找到最大的分数的索引返回答案即可
#由于自己写的TfIdf效率太低,可以用sklearn的Tfidf
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
tf_idf = tfidf.fit_transform(raw_documents=question)
w = tfidf.transform(['When did Beyonce start becoming popular'])
similary = []
maxIndex = 0
for k,i in enumerate(tf_idf):
simi = w.dot(i.T)[0,0]
similary.append(simi)
if simi > similary[maxIndex]:
maxIndex = k
print(answers[maxIndex][0]['text'])
输出结果:
in the late 1990s
总结
以上就是今天要讲的内容,本文仅仅简单介绍了比较传统的问答系统的基本原理,欢迎大家评论沟通。