前言:
Pandas 是基于 NumPy 设计实现的 Python 数据分析库,Pandas 提供了大量的能让我们高效处理数据的函数和方法,也纳入了很多数据处理的库以及一些数据模型,可以说非常强大。
可以使用以下命令进行安装:
conda install pandas # 或 pip install pandas
Series数据结构
Pandas 最常用的数据结构主要有两种:Series 和 DataFrame,这篇文章主要介绍一下Series及如何创建Series对象。
Series 是一维数组,由一列索引index和一列值values组成,索引和值是一一对应的,可以存储不同种类的数据类型,字符串、布尔值、数字、Python对象等都可以。
创建Series对象
创建Series对象的格式如下:
s = pd.Series(data, index)
参数data为数据,可以是字典、列表、Numpy的 ndarray 数组等;
参数index为索引,值必须唯一,类似于Python字典的键,可以不传,默认为从0开始递增的整数。
从列表创建:
data = ["a", "b", "c", "d", "e"] s = pd.Series(data) s
从字典创建:
当data为字典时,如果没有传入索引的话,会按照字典的键来构造索引,索引对应的值就是字典的键对应的值。
data = {"a": 1, "b": 2, "c": 3}
s = pd.Series(data)
s
结果输出如下:
a 1
b 2
c 3
dtype: int64
从 ndarray 数组创建:
ndarray 为Numpy 的数组类型,在之前的文章Python数据分析之 Numpy 的简单使用已经介绍过。
data = np.array([1, 2, 3, 4]) s = pd.Series(data) s
我们可以通过创建的Series对象,调用相应的属性和方法来进行数据的处理分析等。
这篇文章主要说一下Series对象的基本操作。
Series 常用属性
- index:获取索引
- values:获取数组
- size:获取元素数量
- dtype:获取对象的数据类型
获取索引及修改索引:
data = ["a", "b", "c", "d"] s = pd.Series(data) print(s.index) s.index = ["A", "B", "C", "D"] print(s.index)
结果输出如下:
RangeIndex(start=0, stop=4, step=1) Index(['A', 'B', 'C', 'D'], dtype='object')
指定索引对应元素的获取、修改及删除:
Series 通过索引获取、修改及删除对应元素和Python字典的操作有些类似,具体使用方法如下:
# 获取数据
print(s["A"])
# 修改数据
s['A'] = 99
# 删除数据
s = s.drop("B")
s
另外,Series 也支持通过筛选条件获取数据,例如获取能被2整除的数据:
data = np.array([1, 2, 3, 4]) s = pd.Series(data) s[s%2==0]
Series 切片:
Series 切片操作同Python列表的切面也是类似的,如下:
s[0:3]
表示取第0、1、2个数据。
也可以使用索引值来进行切片,例如获取索引值B-D的值:
s["B":"D"] 复制代码
Series 常用方法
- head(n):返回前n行数据,默认前5行
- tail(n):返回后n行数据,默认后5行
- isnull()&nonull():判断是否为空,返回True和False
- sort_values():排序,通过传递ascending参数来确定升序or降序,默认为True,表示升序
- dropna():删除空值
Series 运算
统计信息:
可以通过describe()方法获取统计信息,如下:
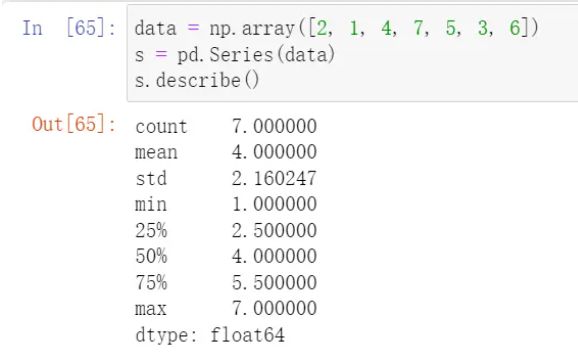
也可以通过如下方法分别获取:
- min():获取最小值
- max():获取最大值
- mean():获取均值
- median():获取中位数
- sum():获取总和
- count():获取总数
- ······
四则运算:
s+2 # 对每个元素进行+2 s*100 # 对每个元素乘100
也可以调用如下方法进行:加法add()、减法sub()、乘法mul()、除法div()。
到此这篇关于Python数据分析之 Pandas Series对象的文章就介绍到这了,更多相关Pandas Series对象内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!