ThunderNet(Towards Real-time Generice Object Detection) 学习笔记
论文: ThunderNet: Towards Real-time Generic Object Detection
作者: Zheng Qin, Zeming Li, Zhaoning Zhang, Yiping Bao, Gang Yu, Yuxing Peng, Jian Sun
一、ThunderNet的提出
移动平台上的实时通用对象检测是一项至关重要但具有挑战性的计算机视觉任务(Real-time generic object detection on mobile platforms is a crucial but challenging computer vision task)。但是以前的基于CNN的检测器具有较大的计算成本(computational cost),这使它们在计算受限的情况下无法进行实时判断。
从网络结构的角度来看,基于CNN的检测器可以分为backbone part和detection part。Backbone part负责提取图像的特征, detection part负责检测图像中的对象实例。
1.1 骨干网络的考虑
在backbone part,stata-of-the-art检测器倾向于利用庞大的分类网络(如ResNet-101等)和高分辨率的输入图像(如800 x 1200),这需要大量的计算成本。轻量级图像分类网络(如Xception, mobilenets, shufflenet等)的最新进展促进了GPU上的实时目标检测。但是,在图像分类和目标检测之间有些不同,目标检测既需要大的感受野,也需要low-level的特征来提高定位能力,但这个对图像分类不那么重要。这两项任务的差距限制了这些骨干网络的性能,并阻碍了在不损害检测精度下进一步压缩。
1.2 检测部分考虑
在检测部分,基于CNN的检测器可以分为two-stage检测器和one-stage检测器。
对于two-stage检测器,检测部分通常包括Region Proposal Network(RPN)和检测head(包括RoI warping和R-CNN子网络)。RPN首先产生RoIs,然后RoIs进一步完善RoIs。State-of-the-art two-stage检测器倾向于利用heavy detection part以获得更好的精度,但这对于移动设备台昂贵了。Light-Head R-CNN采用lightweight 检测器head,在GPU上实现了实时检测。但是,当采取较小的backbone时,Light-Head R-CNN仍旧在检测部分比骨干网络使用更多的时间,这导致弱backbone和强detection part的不匹配。这种不平衡不仅会导致很大的冗余,而且会使网络更易于过拟合。
One-stage检测器直接预测边界框和类别概率,被广泛认为是实时检测的关键。但是,由于one-state检测器不进行roi-wise的特征提取和识别,因此其结果比two-stage的检测器更加粗糙。对于轻量级检测器这个问题更加严重。它们无法实现在移动设备上进行实时检测,而且与大型检测器存在较大的精度差距。
上面描述说了这么多,总结起来如下:
- 目标检测任务和图像分类任务不同,因此骨干网络可以在不损失检测精度的同时进行压缩
- one-stage的检测器准确性不高,尤其是轻量级的检测器效果更加差,同时不能实现在移动设备上进行实时检测。
- two-stage检测器的精度较高,但其网络架构存在很多冗余和不匹配等问题,因此可以通过对检测器部分进行压缩来提高速度,实现实时检测。
为了实现实时检测,论文中提出了一个轻量级two-stage的通用目标检测器,叫做ThunderNet,如Fig2所示。在backbone部分,作者分析了之前轻量级骨干网络的缺点,提出了一种专为目标检测设计的轻量级骨干网络SNet。在detection part,作者遵循Light-Head R-CNN中的detection head设计,并进一步压缩了RPN和R-CNN子网络。为了消除small backbones和small feature maps带来的性能下降,作者提出了两个efficient architecture blocks, Context Enhancement Module(CEM)和Spatial Attention Module(SAM)。CEM组合了多尺度特征图来利用local和global的上下文信息,而SAM使用RPN中学习的信息来完善RoI warping中的特征分布。

最后, 作者研究了输入图像分辨率、backbone和detection head之间的平衡。
相比于轻量级的one-stage检测器,ThundeNet只以其40%的计算成本,就实现了PASCAL VOC和COCO benchmarks上的卓越性能。而且,ThundeNet在基于ARM的设备上以24.1fps的速度运行。据作者所知,这是ARM平台上首次报道的实时检测器。这些结果证明了two-stage检测器在实时目标检测中的有效性。
二、ThunderNet介绍
2.1 骨干网络
骨干网络提供输入图像的基本特征表示,并且对准确性和效率都有很大影响作者基于感受野和early-stage和late-stage的特征进行高效网络的设计。
- 感受野 感受野大小在CNN模型中起着重要作用。CNN只能捕获感受野内信息。因此,大的感受野可以利用更多的上下文信息,并且更有效地编码像素之间long-range的关系。这对于定位是重要的,尤其是对large objects的定位。
- early-stage特征和late-stage特征 在骨干网络中,early-stage特征图具有描述空间信息的low-level特征,而late-stage的特征图较小,具有high-level的特征,具有更高的辨别力。通常,定位对low-level特征较敏感,而high-level特征对分类至关重要。因此,early-stage和late-stage特征都很重要。
作者认为现有轻量级网络的设计违反了上述因素:
- shufflenet v1/v2 具有受限的感受野(121像素 vs 输入的320像素)
- shufflenetv2和moiblenetv2缺少early-stage特征
- Xception的high-level的特征不足
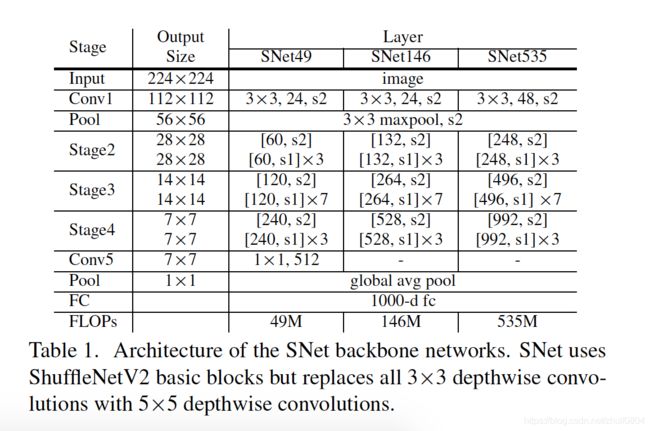
为此,作者在ShuffleNetv2的基础上构建了一个名为SNet的轻量级骨干网络用来实时检测: SNet49用来更快的预测,SNet535用来更好的精确性,SNet为了实现更好的折中speed/accuracy。作者是这样设计的:
- 把ShuffleNetv2中所有的3x3 depthwise卷积替换成了 5x5的depthwise卷积,感受野从121像素提高到193像素。
- 在SNet146和SNet535中,移除了Conv5,并且在early-stages增加了更多的通道。这可以使得生成更多的low-level特征,而没有额外的计算成本。
- 在SNet49中,作者把Conv5压缩到512通道,但增加early stage的通道数量,更好的平衡low-level和high-level特征。
结构如Table1所示。
另外,输入图像的分辨率应该与骨干网络的capability相匹配。这里引用论文中的一句话:
A small backbone with large inputs and a large backbone with small inputs are both not optimal.
作者设置的网络输入是320x320像素。
2.2 压缩RPN和detection head
Two-stage检测器通常采用large RPN和heavy detection head。论文中对两者进行了压缩。
- RPN压缩 把原来的3x3x256的常规卷积替换成5x5的depthwise卷积 + 1x1x256的常规卷积。增大卷积核是为了扩大感受野并编码更多的上下文信息。对于anchor boxes,采取了5种尺度的 { 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 } \lbrace32^2, 64^2, 128^2, 256^2, 512^2\rbrace {322,642,1282,2562,5122}、5种宽高比 { 1 : 2 , 3 : 4 , 1 : 1 , 4 : 3 , 2 : 1 } \lbrace1:2, 3:4, 1:1, 4:3, 2:1\rbrace {1:2,3:4,1:1,4:3,2:1}
- detection head压缩 在RoI之前,利用Light-Head R-CNN的方式,产生 5 x 7 x 7通道数的特征图(将10替换成了5,这是因为ThunderNet中的骨干网络和输入图像的尺寸更小)。RoI pooling采用PSRoI pooling, 得到5x7x7的特征图。之后利用1024-d的全连接层。
2.3 Context Enhancement Module
Light-Head R-CNN采用了Global Convolutional Network(GCN)来产生thin的特征图。它显著地增加了感受野,但引入了巨大的计算成本。作者放弃了这种设计。
但为了有足够大的感受野,编码足够的上下文信息,作者设计了Context Enhancement Module(CEM)。CEM的主要思想是聚合不同尺度的local context信息和global context信息来产生更加具有区别性的特征,如Fig3所示。

在CEM中,来自三个尺度的特征图需要合并: C 4 , C 5 C_4, C_5 C4,C5和 C g l b C_{glb} Cglb。 C 4 C_4 C4和 C 5 C_5 C5在SNet146和SNet535中表示Stage3和Stage4的输出,在SNet49中表示Stage3和Stage5的输出, C g l b C_{glb} Cglb是对 C 5 C_5 C5进行global average pooling得到的特征向量。作者采用1x1的卷积将每个特征图的通道数压缩为5x7x7=255。 C 5 C_5 C5进行2倍上采样, C g l b C_{glb} Cglb进行广播,最后三者的特征图的维度相同。
CEM通过利用local和global context,有效地扩大了感受野,并且改善了thin特征图的表示能力。相比于FPN,其更加计算友好。
2.4 Spatial Attention Module
在RoI pooling时,我们希望背景区域的特征较少,而前景区域的特征较高。但是,与大模型相比,ThunderNet使用了轻量级的骨干网络和小分辨率的输入图像,因此网络本身很难学习正确的特征分布。
因此作者,作者设计了计算友好的Spatial Attential Module(SAM)来显示的re-weight在RoI之前的特征图。SAM的主要思想是使用RPN的知识来改善特征图的特征分布。RPN在有监督的情况下被训练用来识别前景。因此,RPN的中间特征可以被用来区分前景特征和背景特征。
SAM接受两个输入,分别是来自RPN的中间特征 F R P N F^{RPN} FRPN和来自CEM的thin特征图 F C E M F^{CEM} FCEM, 如Fig4所示,SAM的输出 F S A M F^{SAM} FSAM被定义为:
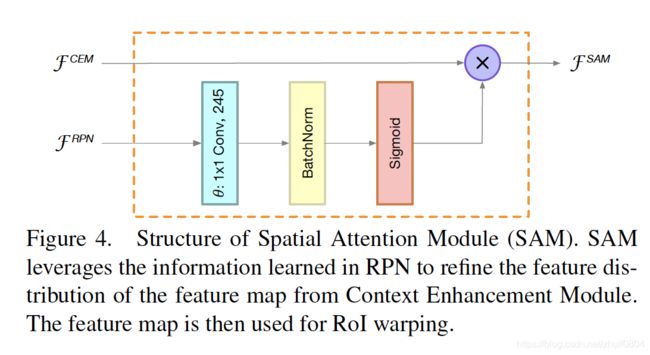
F S A M = F C E M ∗ s i g m o i d ( θ ( F R P N ) ) F^{SAM} = F^{CEM} * sigmoid(\theta(F^{RPN})) FSAM=FCEM∗sigmoid(θ(FRPN))
θ \theta θ时1x1的卷积,被用来维度调整,来匹配 F R P N F^{RPN} FRPN和 F C E M F^{CEM} FCEM的通道。Sigmoid函数用来限制值在[0,1]
三、ThunderNet的实验结果
ThunderNet在VOC和COCO的实验结果
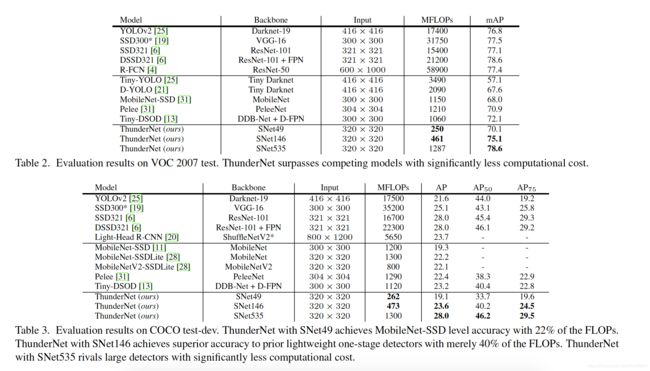
其它的一些实验在这里就不列出了。