Java用Jsoup爬取王者荣耀英雄图片
Jsoup
Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API, 可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup官网
jsoup: Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety https://jsoup.org/
https://jsoup.org/
王者荣耀
王者荣耀是是由腾讯游戏天美工作室群开发并运行的一款运营在Android、IOS、NS平台上的MOBA类国产手游。
爬取的网站
英雄资料列表页-英雄介绍-王者荣耀官方网站-腾讯游戏王者荣耀英雄介绍,全部英雄大全,英雄属性,英雄图片,英雄技能定位,英雄故事,英雄图文视频攻略,助您荣登最强王者宝座!https://pvp.qq.com/web201605/herolist.shtml
爬取分析
引入Jsoup依赖
org.jsoup
jsoup
1.13.1
对网站分析
去官网看网页源代码可知,英雄列表是在

代码如下
//Http请求
Connection conn = Jsoup.connect("https://pvp.qq.com/web201605/herolist.shtml");
//网页文档
Document doc = conn.get();
Element elementUL = doc.selectFirst("[class=herolist clearfix]");
Elements elementsLi = elementUL.select("li");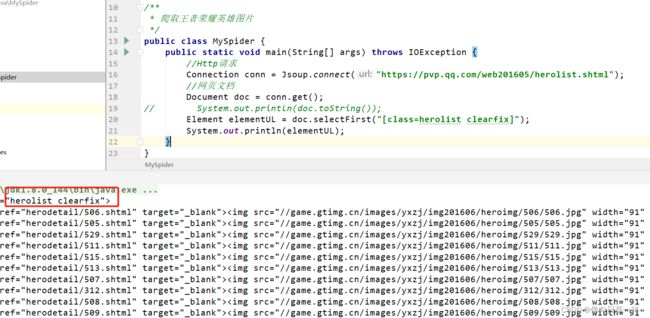
进一步分析网站你会发现,li里的图片都是小图,不清晰,当点击图片时会链接到该英雄的详情页面,我们应该获取这上面的图片


代码如下,其中获取到的详情页面地址是相对地址,得进行拼接
//循环遍历 取li
for (Element elementLi : elementsLi) {
Element elementA = elementLi.selectFirst("a");
String pickName = elementA.text();
System.out.println(pickName);
//爬虫继续前往下一个结点爬取
String attrHref = elementA.attr("href");
String path = "https://pvp.qq.com/web201605/" + attrHref;
//进入到path路径下的网页,下载图片
getPic(path, pickName);
}可以先输出pickName进行验证

详情页面
对详情页面进行分析,我们可以找到大图的位置,我们要获取的是这个图片地址,获取到图片地址后,接着IO读写把这些网络图片下载到本地即可。

浏览器打开图片地址,验证没问题
分析:
先获取class为zk-con1 zk-con的div,再获取style里的地址,再对地址进行截断拼接,最后用IO读这些网络图片,然后写入本地磁盘即可,这里我存入D盘下的javaSpider文件中,每个图片的命名用该英雄名字。

可先打印attrStyle,验证获取的style地址对不对

代码如下
/**
* 下载图片
*
* @param path
* @param pickName
*/
private static void getPic(String path, String pickName) throws IOException {
Connection conn = Jsoup.connect(path);
Document doc = conn.get();
Element elementDiv = doc.selectFirst("[class=zk-con1 zk-con]");
String attrStyle = elementDiv.attr("style");
//background:url('//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/167/167-bigskin-1.jpg') center 0
//截取字符串
int start = attrStyle.indexOf("'//") + 3;
int end = attrStyle.lastIndexOf("'");
//截取后,game.gtimg.cn/images/yxzj/img201606/skin/hero-info/167/167-bigskin-1.jpg
//String substring = attrStyle.substring(start, end);
URL url = new URL("https://" + attrStyle.substring(start, end));
//下载网络图片到本地
//IO 输入流 读取
BufferedInputStream in = null;
BufferedOutputStream out = null;
try {
in = new BufferedInputStream(url.openStream());
out = new BufferedOutputStream(new FileOutputStream(new File("D:\\javaSpider\\" + pickName + ".jpg")));
byte[] b = new byte[1024];
int len = -1;
while ((len = in.read(b, 0, 1024)) != -1) {
out.write(b, 0, len);
out.flush();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
in.close();
out.close();
}
}完整代码如下:
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.URL;
/**
* 爬取王者荣耀英雄图片
*/
public class MySpider {
public static void main(String[] args) throws IOException {
//Http请求
Connection conn = Jsoup.connect("https://pvp.qq.com/web201605/herolist.shtml");
//网页文档
Document doc = conn.get();
//System.out.println(doc.toString());
Element elementUL = doc.selectFirst("[class=herolist clearfix]");
//System.out.println(elementUL);
Elements elementsLi = elementUL.select("li");
//循环遍历 取li
for (Element elementLi : elementsLi) {
Element elementA = elementLi.selectFirst("a");
String pickName = elementA.text();
System.out.println(pickName);
//爬虫继续前往下一个结点爬取
String attrHref = elementA.attr("href");
String path = "https://pvp.qq.com/web201605/" + attrHref;
//进入到path路径下的网页,下载图片
getPic(path, pickName);
}
}
/**
* 下载图片
*
* @param path
* @param pickName
*/
private static void getPic(String path, String pickName) throws IOException {
Connection conn = Jsoup.connect(path);
Document doc = conn.get();
Element elementDiv = doc.selectFirst("[class=zk-con1 zk-con]");
String attrStyle = elementDiv.attr("style");
//background:url('//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/167/167-bigskin-1.jpg') center 0
//截取字符串
int start = attrStyle.indexOf("'//") + 3;
int end = attrStyle.lastIndexOf("'");
//截取后,game.gtimg.cn/images/yxzj/img201606/skin/hero-info/167/167-bigskin-1.jpg
//String substring = attrStyle.substring(start, end);
URL url = new URL("https://" + attrStyle.substring(start, end));
//下载网络图片到本地
//IO 输入流 读取
BufferedInputStream in = null;
BufferedOutputStream out = null;
try {
in = new BufferedInputStream(url.openStream());
out = new BufferedOutputStream(new FileOutputStream(new File("D:\\javaSpider\\" + pickName + ".jpg")));
byte[] b = new byte[1024];
int len = -1;
while ((len = in.read(b, 0, 1024)) != -1) {
out.write(b, 0, len);
out.flush();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
in.close();
out.close();
}
}
}