【Python】Spider 初探
本文为 one-ccs 原创文章,引用必须注明出处!
文章目录
-
- 你需要知道
- 准备
- 目标
- 开始
- 总结
- 还可以做什么
最初是看到了Python爬虫入门教程:超级简单的Python爬虫教程,就有点感兴趣。正好这几天有时间,就一头钻了进去。经过几天的研究,也算有了一些了解。
你需要知道
- HTML(超文本标记语言 ,Hyper Text Markup Language)
- 正则表达式(规则表达式,Regular Expression,在代码中常简写为regex、regexp或RE
- 编码
- python
urllib (Python 内置的 HTTP 请求库)
requests (第三方 HTTP 请求库,pip install requests)
re(Python 内置的 正则 库)
try: … except: …异常处理
准备
-
1.HTML
- HTML 简介 2. 正则表达式
- github - learn-regex
- 你是如何学会正则表达式的? 3. 编码
- 什么是字符编码 4. python
- urllib的详解使用
- urllib.parse解析链接
- urlretrieve() 函数下载图片
- requests库详解 --Python3
- python爬虫之requests的使用
- 从requests源码和scrapy源码分析编码问题
- Python正则表达式指南
- 异常处理
目标
以爬取壁纸吧的图片为例,输入首页地址,自动爬取所有页面的图片
开始
注:以下使用的所有库,在上一节“准备”中都给出了对应的链接,且你在里面能学到的必然远远超过接下来所学的,以下仅仅做为一个示例,抛砖引玉,让我们开始吧!
1. 使用 requests 获取网页源代码
本来是用的python内置的 urlllib 但是这个库用起来特麻烦(特别是处理字符串编码的时候),最后换成了第三方的 requests
''' 使用 requests '''
import requests
from requests.exceptions import ReadTimeout, HTTPError, RequestException
url = '...'
# 尝试执行 try 缩进的代码,捕获错误后执行对应语句,否则报错并结束程序的运行
try:
# 请求 url 获得一个 ''' 使用 urllib '''
from urllib import request
url = 'https://tieba.baidu.com/p/6197666814?pn=1'
# 请求 url 获得一个 2. 选择合适的正则表达式
随便打开一条帖子,复制图片地址。然后右击 -> 查看网页源代码 -> Ctrl+F -> 搜索复制的地址
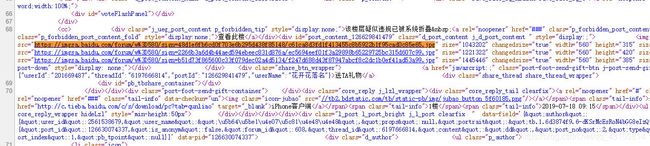
搜索成功,并且发现图片路径是使用的绝对路径,这下好办了!
![]()
观察链接规律,使用正则 (?<=src=").+?\.jpg
![]()

匹配多达83个,有许多都是不需要的链接。
对表达式进行优化 (?<=src=").+?\.jpg(?=" size="\d{4,7})
![]()
![]()
优化后匹配39个,正好。
3. 使用 re 筛选
''' 使用正则表达式筛选可用链接 '''
import requests
import re
url = '...'
response = requests.get(url)
text = response.text
# 正则表达式
regex = r'(?<=src=").+?\.jpg(?=" size="\d{4,7})'
# 编译正则表达式 4. 使用 urllib.request 下载
既然获取了下载链接,那么下一步自然就是把图片下载下来了
''' 下载 '''
# 保存地址,这里使用的相对路径
path = './download/01.jpg'
# 下载,这里忽略了回调函数
request.urlretrieve(match[0], path)
5. 获取第 n 页链接
现在下载首页的图片没有问题了,那怎么自动下载第 n 页呢?
又是推理时间:
第一页 .../p/6197666814?pn=1
第二页 .../p/6197666814?pn=2
观察可知只有最后一个数字发生了变化,那猜测,最后一个数字是不是代表页数呢?
可推出第6页会不会是 .../p/6197666814?pn=6呢?
经验证后,果然是这样
接下来就是一页一页的下载所有页面了,很容易就想到了循环使用字符串的 format 方法
''' 获取第 n 页链接 '''
url = '...'
# 字符串模板
url_model = url[:-4] + '{}'
page = 1 # 起始页
end_page = 100 # 结束页
while page <= end_page:
print(url_model.format('pn=' + str(page)))
page += 1
6. 结束
恭喜,你已经成功爬取了一堆预览图
ヽ(#`Д´)ノ 解决办法是,继续推理
预览图地址
/forum/w%3D580/sign=48d1e6...8/c61ca8d3fd1f413455c8b5922b1f95cad0c85e65.jpg
/forum/w%3D580/sign=2266b3...a/ec5694eef01f3a29898b65229725bc315d607c99.jpg
原图地址
/forum/pic/item/c61ca8d3fd1f413455c8b5922b1f95cad0c85e65.jpg
/forum/pic/item/ec5694eef01f3a29898b65229725bc315d607c99.jpg
观察发现文件名是不变的,只有路径变了
ok,那好办给所有下载链接变个装
''' 使用 url2fn 提取文件名 '''
def url2fn(url):
""" 返回 url 中的文件名 """
if not isinstance(url, str):
raise ValueError(
'The argument "url" should be a "str", but it is a "{}".'.format(type(url)))
flag = url[::-1].find('/')
if flag == -1:
return None
file = url[-flag:]
return file
''' 获取所有文件名 '''
filenames = map(url2fn, match)
for filename in filenames:
print(filename)
''' 组合链接 '''
# 获取所有文件名 7. 真的结束了
整理所有代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
import re
from requests.exceptions import ReadTimeout, HTTPError, RequestException
from urllib import request
def check_url(url):
"""对首页链接的特殊情况进行特殊处理
若首页链接没有带页码,则自动加上页码方便后续处理
"""
if url.find('?') == -1:
url += '?pn=1'
return url
def get_text(url):
"""返回网页源码"""
text = None
try:
# 请求 url 获得一个 总结
你学到了:
- 什么是 HTML
- 什么是 正则表达式
- python库 urllib,requests,re
- try: … except: …异常处理
还需要注意:Python爬虫基本上都是一次性的,但万物不离根,都是这么个思路,只需要根据实际情况制定不同的策略。
还可以做什么
- 提取域名
- 提取标题
- 提取文件名
- 根据 “./download/域名/标题/文件名” 的形式组织保存目录
- 提取日期
- 提取尾页页码
- 等等