JavaWeb项目——基于Servlet实现的在线OJ平台 (项目问答+代码详解)
文章目录
- 项目演示
- 预先知识
-
- 请问 在处理用户同时提交代码时是 多进程处理还是 多线程处理?
- 你是如何创建多进程的逻辑的
- 如何获取到编译与运行后的结果?
- 编译运行模块
-
- 子进程之间如何并发?
- 文件读写操作为什么用 int 来接收每次读取的 byte字节流呢?
- 参数类--Question
- 返回值-- Answer
-
-
-
- 错误码
- 错误信息
- 运行程序得到的标准输出的结果
- 运行程序得到的标准错误的结果
-
-
- Task 编译运行过程的流程是什么?
- 约定临时文件名
-
-
-
- 创建了一个临时文件目录
- 创建代码类名
- 约定编译的代码文件名
- 约定存放编译错误信息的文件名
- 约定存放运行时标准输出的文件名
- 约定存放运行时标准错误的文件名
-
-
- 为什么要约定这么多临时文件呢?
- 文件读写操作
-
-
-
- FileUtil
- 文件读操作
- 为啥不用String,而用StringBuilder 呢?
-
- 文件写操作
-
-
- 实现保存源代码
- 实现编译功能
- 实现运行功能
- 编译运行正常
- 完整编译运行模块代码逻辑
-
- ComandUtil类--处理创建子进程,执行命令
- FileUtil类--文件读写操作
- Task类--完整的编译运行过程
- Question类-- 代码参数对象
- Answer类-- 返回值对象
- 题目管理模块
-
- 数据库设计
- 题目表设计
- JDBC 连接数据库
- 封装具体的类对应表中的信息
- 对数据库中的信息增删改查
- API 模块
-
- API 设计
-
- 1. API 与前端的那些界面相对应
- 2.具体要返回什么信息,什么格式来返回?
- 这个项目里面你具体实现了哪些api来进行前后端的交互呢?
- 返回数据的格式是什么?怎么返回这种格式?
- 设计API的时候,点击提交会发生什么?
- 如何将用户提交的代码发送到服务器中?
- API 设计小结
- API 实现
-
- 查找题目列表
- 查找题目详情
- 上传用户代码到服务器进行编译运行
-
- 这里我们要先提一个思路,因为用户提交的代码是不能直接进行编译的,那么怎么到服务器运行呢?
- 提交请求至服务器的全部逻辑
- 异常处理
项目演示
访问部署在Linux云服务器上的项目地址
主页显示项目相关信息,向下翻显示题目列表
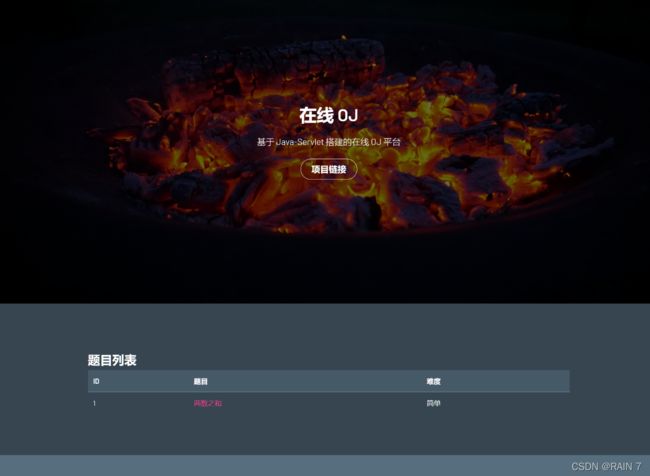
点击题目标题,展示题目详细信息。
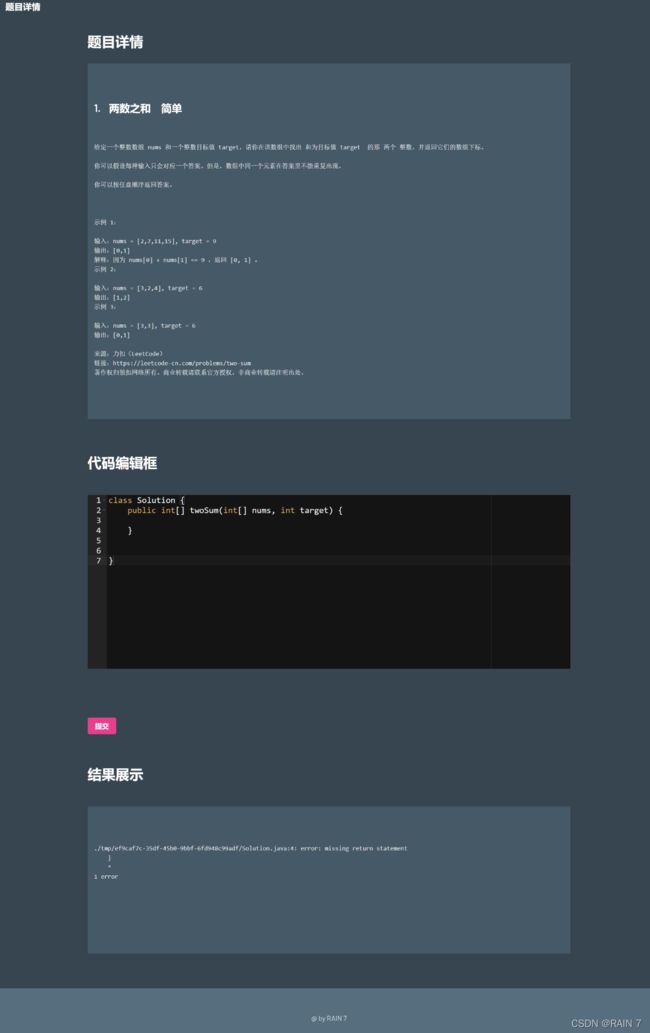
点击提交按钮,把用户编辑的代码上传到服务器上进行编译和运行,把返回的结果显示到结果展示栏。
访问部署在云服务器上的项目
在这个页面里面,首先我们可以看到映入眼帘的主页,在这个主页我们就可以看到一些有关项目的基本信息
这个项目是一个基于Java servlet实现的在线oj平台,然后再项目名称下面加了一个 项目源代码的gittee链接,
然后呢我们再往下翻,我们就能看到的是一个题目的列表了,作为一个在线oj的一个系统呢,里面肯定得有很多的编程题目,我们这里呢就通过一个题目列表把题目的基本信息给展示出来,每一行列表都会显示题目的id、标题、难度。
我们点击具体的题目标题以后呢,一点之后呢会跳转到另外一个界面,直接显示的就是题目的具体信息,显示展示的是题目的具体描述,当然了这里也包括题目的id、标题、难度、以及具体描述及要求
然后在下面呢有一个代码编辑框,在这个编辑框中我们就可以编译自己写的代码,就演示一下在代码框中写一下代码,在编辑代码的时候还会有代码高亮补全的功能,
点击提交,然后这个程序的执行结果就会显示在下面的结果展示框中,里面就提示我们通过了哪个测试用例,
如果这个代码中出现一些问题,比如说代码中少写了一个分号,再次点击提交,就会在结果框展示出错的具体提示。通过这个错误提示就可以提示用户代码中哪一行出现错误。
这就是关于当前的一个在线OJ项目的最基本的最核心流程。
预先知识
请问 在处理用户同时提交代码时是 多进程处理还是 多线程处理?
创建线程/销毁线程 都比 创建销毁进程更高效,所以很多Java的并发编程都是通用多线程的方式来实现的,但是这个项目 应用的是 多进程编程
多进程相比于多线程也有自己的优势
进程之间具有独立性
操作系统上同一时刻运行着很多个进程,如果某个进程挂了,不会影响到其他进程(因为每个进程都有各自的地址空间)
相比之下,多个线程之间共用同一个进程的内存空间,如果某个线程挂了,就很可能把整个服务器进程都弄崩溃了。
所以子进程来处理用户的请求虽然没有多线程处理那么高效,但是会更加的安全,更加的稳定,在我们当前的项目中稳定就非常的重要。
我们的在线OJ
有一个服务器进程(运行着 servlet,接收用户请求,返回响应)
用户提交的代码,其实也是一个独立的逻辑,处理用户的代码我们就得使用多进程的方式来处理。
因为我们无法控制用户提交的代码到底是什么,这个代码很可能是存在问题的,很可能是一运行就程序崩溃了,如果是多线程就会导致把整个服务器进程都给带走了的情况。而且在现实中一个服务器处理的用户量是很大的,我们也无法保证用户提交的代码都是没有问题的。
因此在我们 项目中为了让程序顺利执行,为了让服务器更加稳定,为了让用户提交的代码不影响服务器的运行,此处势必要使用多进程编程。
你是如何创建多进程的逻辑的
先创建 Runtime 的实例
Runtime runtime = Runtime.getRuntime();
Process process = runtime.ecex(“javac”)
方法里面填入要执行的程序命令字符串 javac,返回的结果是一个Process进程
当我们执行这个代码就相当于在cmd中输入了具体的指令
这样我们就成功创建了一个子进程,并让子进程具体去执行任务了。
如果我们的操作系统不认识我们执行的命令的话,那么把 javac所在的目录给加入到 PATH环境变量当中。
如何获取到编译与运行后的结果?
一个进程在启动的时候,就会自动打开三个文件:
1、标准输入 对应到键盘
2、标准输出 对应到显示器
3、标准错误 对应到显示器
javac是一个控制台程序,他的输出 ,是输出到 标准输出 和标准错误的文件当中的,如果我们要看到程序运行的效果,就得获取到这两个文件的内容
process.getInputStream,读入文件数据流。写入到对应文件中。
process.getErrorStream,读入标准错误数据流,写入到对应文件。
虽然子进程启动后也打开了这三个文件,但是子进程没有和IDEA终端连接,,所以我们要获取到子进程的标准输出和标准错误,把这里的内容写入到两个文件中。
编译运行模块
子进程之间如何并发?
在当前的场景中,希望子进程执行完毕后,在执行后续代码,需要让用户提交代码,编译执行代码,肯定是要在编译已执行完毕了,再把相应返回给用户。
一方面时安排子进程的执行顺序,
一方面需要让父进程知道子进程的执行状态。
通过 Process 类的waitFor 方法来实现进程的等待。
父进程执行到waitFor方法就会阻塞,一直阻塞到子进程执行完毕。,同时会返回一个int整数退出码,这个退出码就表示子进程的执行结果是否ok,如果子进程时代码执行完了正常退出,此时返回的是0,如果子进程代码执行了一半异常退出(抛出异常),此时返回的退出码就非0
编译运行我们用一个 CommandUtile这个类封装了这个创建一个子进程,执行命令的过程
- 通过一个Runtime类 获得一个 Runtime 实例,执行exec方法
- 获取标准输出,并写入到指定文件
- 获取标准错误,并写入到指定文件
- (每个子进程在最后都要进程等待)等待子进程结束, 拿到子进程的状态码,并返回结果。
如果返回为0 说明执行没有问题,如果返回1,说明执行有异常。
文件读写操作为什么用 int 来接收每次读取的 byte字节流呢?
read方法一次返回的是一个字节(byte),但是实际上却使用的是int来接受的!
这样做的理由如下:
1、Java中不存在无符号类型,byte这样的类型是有符号的(有正负),byte的表示范围 -128 ~ 127
但实际上我们在按照字节读取数据的时候,并不需要这样的数据来
进行算术运算,此时这里的正负就没有意义了
因此期望读到的结果是一个无符号的数字 0->255
因为我们就需要一个更大的范围来表示接收的数据
如果返回到 byte类型那么不能返回到255
所以呢我们使用int是比较合适的,
第二方面:
read读取完毕(读取到末尾),就会返回EOF,用-1来表示。
正是因为我们把读到的字节用 0-255 来接收,接下来我们才能使用-1 负数来表示EOF状态。
我们把创建子进程并执行命令的操作封装成为了一个CommandUtil类,所以呢 ,我们把 编译加运行这一个过程 封装成 Task类
compileAndRun 方法是 编译加运行,参数是要编译运行的java源代码,返回值是 编译运行的结果
编译出错/运行出错/运行正常
为了方便表示 参数和返回值,我们就创建几个类来表示具体的信息。
参数类–Question
这个类来表示 一个 Task 的输入内容
包含 要编译的代码
private String code;
生成各个属性的 getter 和 setter 方法
public class Question {
private String code;
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
返回值-- Answer
错误码
private int error;
约定如果 error为0 表示编译运行都 ok
error为1 表示编译出错
error为2 表示运行出错
错误信息
private String reason;
表示出错的提示信息
如果error为1 编译出错了,reason就放编译的错误信息
如果error为2 运行出错了,reason就放运行的错误信息
运行程序得到的标准输出的结果
private String stdout
运行程序得到的标准错误的结果
private String stderr
生成各个属性的 getter 和 setter 方法
public class Answer {
private int error ; // 0表示没问题 1表示编译出错 2表示运行出错
private String reason; // 错误的信息,具体哪错了
private String stdout; // 标准输出的结果
private String stderr; // 标准错误的结果
public int getError() {
return error;
}
public void setError(int error) {
this.error = error;
}
public String getReason() {
return reason;
}
public void setReason(String reason) {
this.reason = reason;
}
public String getStdout() {
return stdout;
}
public void setStdout(String stdout) {
this.stdout = stdout;
}
public String getStderr() {
return stderr;
}
public void setStderr(String stderr) {
this.stderr = stderr;
}
}
Task 编译运行过程的流程是什么?
0.把question 中的code 写入到 Solution.java 文件中
1.创建子进程,调用javac进行编译,注意:编译的时候要有一个.java 文件
如果编译出错,javac就会把错误信息写入到stderr里,就用一个专门的文件 compileError来保存。
2.创建子进程,调用java命令并执行,执行刚才的 .calss文件
运行程序的时候,也会把Java子进程的标准输出和标准错误获取到,stdout.txt ,stderr.txt
3.父进程获取到刚才的编译执行的结果,并打包成Answer对象
父进程怎么获取到刚才的结果,读取上面存放信息的文件即可。
约定临时文件名
创建了一个临时文件目录
private static final String WORKDIR ="./tmp/";
创建代码类名
private static final String CLASS= “Solution”;
约定编译的代码文件名
private static final String CODE = WORKDIR+“Solution.java”;
约定存放编译错误信息的文件名
private static final String COMPILE_ERROR = WORKDIR+“compileError.txt”;
约定存放运行时标准输出的文件名
private static final String STDOUT = WORKDIR+“stdout.txt”;
约定存放运行时标准错误的文件名
private static final String STDERR = WORKDIR+“stderr.txt”;
为什么要约定这么多临时文件呢?
最主要的目的就是为了进行"进程间通信“
进程和进程之间是存在独立性的
一个进程是很难影响到其他进程的。
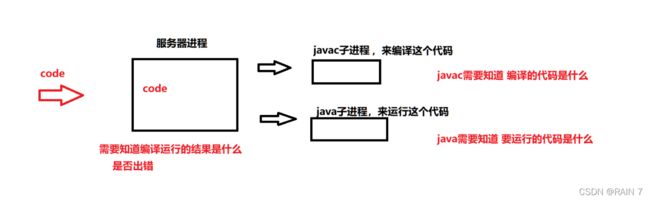
Linux系统 提供的进程间通信有很多手段
但是在这里我们使用过文件的方式来进行进程间通信
服务器进程写到 code所在的文件,javac 所在的进程读取 code文件的代码,java所在的进程又读取 javac进程写的文件 .class ,服务器进程最后拿到 java进程写的标准输出标准错误文件。
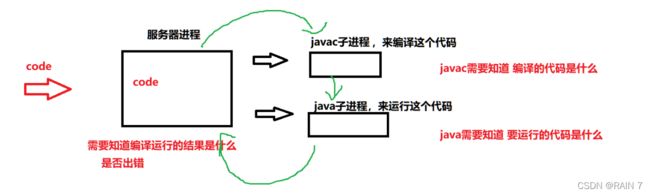
整体的流向大概就是这样
总之呢,我们使用很多临时文件主要是 为了让这些进程之间能够相互配合,让这些进程能够通信起来
文件读写操作
因为很多进程之间通信我们使用了 创建临时文件的方式,所以要涉及到很多的文件的一些操作,最后为了方便我们在代码中的 快速读写操作,我们可以对读写文件的操作封装成一个工具类,来帮助我们实现文件的读写操作。
FileUtil
这个类里面提供两个方法
一个负责读取整个文件的内容(字符串)读取完放到返回值中
一个负责写入整个字符串到文件中。这是我们当前要完成的两个任务。
基于我们学习过的 字节流字符流操作,来写一个具体的文件操作的方法。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TGrMpX9s-1648565227266)(DDEF5961D33A4389A4F1725BD9C59C4D)]
后续要读写的文件,就是这几个,这几个文件都是文本文件,因此使用字节流更合适一些~
对于文本文件来说,字节流和字符流都可以读写,字符流会省事一些,字节流可能麻烦一些(手动的处理编码格式)
文件读操作
public static String readFile(String filePath) {
FileReader fileReader = null;
StringBuilder sb = new StringBuilder();
try {
fileReader = new FileReader(filePath);
while (true){
int ch = fileReader.read();
if(ch==-1) {
break;
}
sb.append(ch+"");
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return sb.toString();
}
为啥不用String,而用StringBuilder 呢?
String是一个不可变对象!
里面持有的字符串内容是不可修改的,如果真要修改,必须要创建一个新的String对象,把旧的内容拷贝过去
StringBuilder 和 StringBuffer
基本用法都是一致的,StringBuffer是线程不安全的,StringBuilder是线程安全的
在这里 多个线程之间修改同一变量,会触发线程安全问题
但是在这里函数内部的局部变量,由于局部变量是在栈上的,你每个线程都有一个自己的栈,所以线程1栈上的数据,线程2 就很难访问到。
所以呢,我们当前就认为 这里的操作是修改局部变量,不涉及线程安全问题的。使用StringBuilder即可。
文件写操作
public static void writeFile(String filPath,String content) throws IOException {
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter(filPath);
fileWriter.write(content);
} catch (IOException e) {
e.printStackTrace();
}
fileWriter.close();
}
文件写的操作就很简单了,直接把content 的内容直接写入到文件中。
读写操作完成,大大方便了我们在之后的 读取文件内容,写入文件内容等操作。
实现保存源代码
因为我们都把文件放到 当前目录 的tmp目录下,如果我们没有事先创建好这个目录就需要 新建一个目录。
0、准备好用来存放南方临时文件的目录
File workDir = new File(WORKDIR);
if(!workDir.mkdirs()){
// 如果目录不存在的话,就创建多级目录
workDir.mkdirs();
}
1、根据提供的queution 对象中的 code 写入到一个 Solution.java 文件中
FileUtil.writeFile(CODE,question.getCode());
// CODE 是之前就定义的 存放Solution.java文件的目录,向这个目录里面写文件
实现编译功能
2. 创建编译的子进程 ,执行javac命令编译 Soulution.java 文件
String compileCmd = String.format("javac -encoding utf8 %s -d %s",CODE,WORKDIR);
ComandUtil.run(compileCmd,null,COMPILE_ERROR);
// 如果编译出错,这里的COMPILE_ERROR 就有内容,如果为空那么没有错误
String compileError = FileUtil.readFile(COMPILE_ERROR)
if(!"".equals(compileError)){
// 如果COMPILE_ERROR不为空,那么编译出错
// 如果出错,直接包装成一个Answer 对象,然后返回
answer.setError(1); // 错误码如果是1 ,那么就表明编译出错
answer.setReason(compileError);
return answer;
}
// 编译正确,继续执行运行的逻辑

-d 选项主要是指定生成的class文件在哪里,这里如果不指定好,生成的 .class 文件可能就跑到其他位置,此时后面进行运行的时候,可能就找不到了。
![]()
对于 javac 这个进程来说,他的标准输出,我们不关注!而是关注他的标准错误~
一旦编译错误,内容就会通过标准错误来反馈出来
我们不要把 javac 的标准输出和标准错误 和java进程的搞混
编译是否正确,我们通过读取 javac进程的 标准错误文件,
如果为空,那么就编译正常
如果不为空那么就编译错误,我们就将标准错误信息还有退出码返回给Answer 对象,返回。
如果编译正确就会得到 .class 文件
如果编译不正确,那么就会包装一个Answer对象,然后直接返回
实现运行功能
3.创建运行的子进程,执行java命令运行刚才生成的 .class 文件
String runCmd = String.format("java -classpath %s ",WORKDIR,CLASS);
ComandUtil.run(runCmd,STDOUT,STDERR);
String runError = FileUtil.readFile(STDERR);
if(!"".equals(runError)){
answer.setError(2);
answer.setReason(runError);
return answer;
}
![]()
这里的 -classpath 选项也很重要,因为我们当前的.class 文件到底在哪我们的java命令是不知道的,如果找不到这个.class文件,那么就会出现类加载不了的情况,所以为了处理这种情况,我们就需要显式的告诉java命令 .class 文件的路径是什么.
后面判断运行是否正确 与前面的 判断编译是否正确的过程是一样的,都是判断 读取标准错误的文件,如果为空那么没有问题,如果不为空那么打包成一个Answer对象,返回answer.
编译运行正常
4. 父类获取到运行的结果 ,并且打包成Answer对象
answer.setError(0);
answer.setStdout(FileUtil.readFile(STDOUT));
return answer;
完整编译运行模块代码逻辑
ComandUtil类–处理创建子进程,执行命令
import java.io.*;
public class ComandUtil {
public static int run(String cmd,String stdout,String stderr) throws IOException, InterruptedException {
//1. 先创建Runtime实例,创建子进程
Process process = Runtime.getRuntime().exec(cmd);
//2. 获取到标准输出
if (stdout!=null) {
InputStream stdoutFrom = process.getInputStream();
OutputStream stdoutTo = new FileOutputStream(stdout);
while(true){
int ch = stdoutFrom.read();
if(ch==-1){
break;
}
stdoutTo.write(ch);
}
stdoutFrom.close();
stdoutTo.close();
}
// 3.获取到标准错误
if (stderr!=null) {
InputStream stderrFrom = process.getErrorStream();
OutputStream stderrTo = new FileOutputStream(stderr);
while(true){
int ch = stderrFrom.read();
if(ch==-1){
break;
}
stderrTo.write(ch);
}
stderrFrom.close();
stderrTo.close();
}
// 4.进程等待,获取到进程状态码,然会结果
// 如果返回0 那么执行正常 如果返回非0,有异常
int exitCode = process.waitFor();
return exitCode;
}
}
FileUtil类–文件读写操作
import javafx.scene.transform.Scale;
import java.io.*;
public class FileUtil {
public static String readFile(String filePath) throws IOException {
FileReader fileReader = null;
StringBuilder sb = new StringBuilder();
try {
fileReader = new FileReader(filePath);
while (true){
int ch = fileReader.read();
if(ch==-1) {
break;
}
sb.append(ch+"");
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
fileReader.close();
return sb.toString();
}
public static void writeFile(String filPath,String content) throws IOException {
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter(filPath);
fileWriter.write(content);
} catch (IOException e) {
e.printStackTrace();
}
fileWriter.close();
}
public static void main(String[] args) throws IOException {
FileUtil.writeFile("d:/test.txt","hello world");
String content = FileUtil.readFile("d:/test.txt");
System.out.println(content);
}
}
Task类–完整的编译运行过程
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class Task {
// 创建了一个临时文件目录
private static final String WORKDIR ="./tmp/";
// 创建代码类名
private static final String CLASS= "Solution";
// 约定编译的代码文件名
private static final String CODE = WORKDIR+"Solution.java";
// 约定存放编译错误信息的文件名
private static final String COMPILE_ERROR = WORKDIR+"compileError.txt";
// 约定存放运行时标准输出的文件名
private static final String STDOUT = WORKDIR+"stdout.txt";
// 约定存放运行时标准错误的文件名
private static final String STDERR = WORKDIR+"stderr.txt";
public Answer compileAndRun(Question question) throws IOException, InterruptedException {
Answer answer = new Answer();
//0.准备好用来存放南方临时文件的目录
File workDir = new File(WORKDIR);
if(!workDir.mkdirs()){
workDir.mkdirs();
}
// 1 、 根据提供的queution 对象中的 code 写入到一个 Solution.java 文件中
FileUtil.writeFile(CODE,question.getCode());
// 2. 创建编译的子进程 ,执行javac命令编译 Soulution.java 文件
String compileCmd = String.format("javac -encoding utf8 %s -d %s",CODE,WORKDIR);
ComandUtil.run(compileCmd,null,COMPILE_ERROR);
// 如果编译出错,这里的COMPILE_ERROR 就有内容,如果为空那么没有错误
String compileError = FileUtil.readFile(COMPILE_ERROR);
if(!"".equals(compileError)){
// 如果COMPILE_ERROR不为空,那么编译出错
// 如果出错,直接包装成一个Answer 对象,然后返回
answer.setError(1); // 错误码如果是1 ,那么就表明编译出错
answer.setReason(compileError);
return answer;
}
// 编译正确,继续执行运行的逻辑
// 3,创建运行的子进程,执行java命令运行刚才生成的 .class 文件
String runCmd = String.format("java -classpath %s ",WORKDIR,CLASS);
ComandUtil.run(runCmd,STDOUT,STDERR);
String runError = FileUtil.readFile(STDERR);
if(!"".equals(runError)){
answer.setError(2);
answer.setReason(runError);
return answer;
}
// 4. 父类获取到 运行的结果 ,并且打包成Answer对象
answer.setError(0);
answer.setStdout(FileUtil.readFile(STDOUT));
return answer;
}
public static void main(String[] args) {
}
}
Question类-- 代码参数对象
public class Question {
private String code;
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
Answer类-- 返回值对象
public class Answer {
private int error ; // 0表示没问题 1表示编译出错 2表示运行出错
private String reason; // 错误的信息,具体哪错了
private String stdout; // 标准输出的结果
private String stderr; // 标准错误的结果
public int getError() {
return error;
}
public void setError(int error) {
this.error = error;
}
public String getReason() {
return reason;
}
public void setReason(String reason) {
this.reason = reason;
}
public String getStdout() {
return stdout;
}
public void setStdout(String stdout) {
this.stdout = stdout;
}
public String getStderr() {
return stderr;
}
public void setStderr(String stderr) {
this.stderr = stderr;
}
}
题目管理模块
数据库设计
这个平台有一个最核心的功能,展示所有题目,点击题目链接,展示题目详情。
所以数据库我们要围绕着 题目建一个数据库,在数据库中建立一个 题目表,在项目中使用 JDBC 的方法进行连接数据库,进行数据库 数据的增删改查操作。
第一步,设计数据库。
我们在设计数据库的时候,要想到我们查找题目详情想要点开的信息。
牛客网的题目展示页
点开具体题目,展示的题目详情
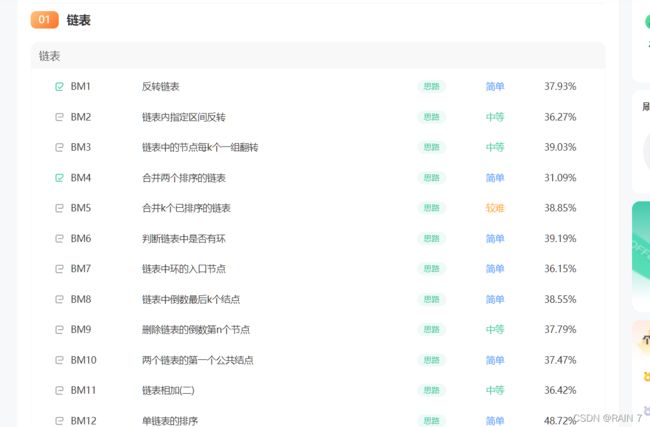
根据这两个页面,我们能够了解到,我们需要设计题目表的具体信息是什么。
题目展示页需要展示什么信息
1、 题目名字
2、 题目 id
3、题目难度
暂时就这三个核心点吧,有机会再扩充其他信息
题目详情页需要展示什么信息
1、 题目详情
2、默认存在的代码模板
3、测试用例代码
4、写的代码通过编译运行之后的结果展示
所以我们根据这些信息,来进行设计数据库中的 题目表
题目表设计

基础信息就是这些了,以后可以扩充功能信息。
我们现在项目main文件夹中创建一个 sql 的文件来写一下 建表建库的sql语句
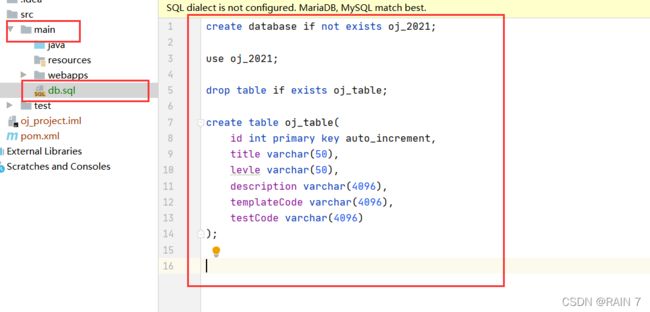
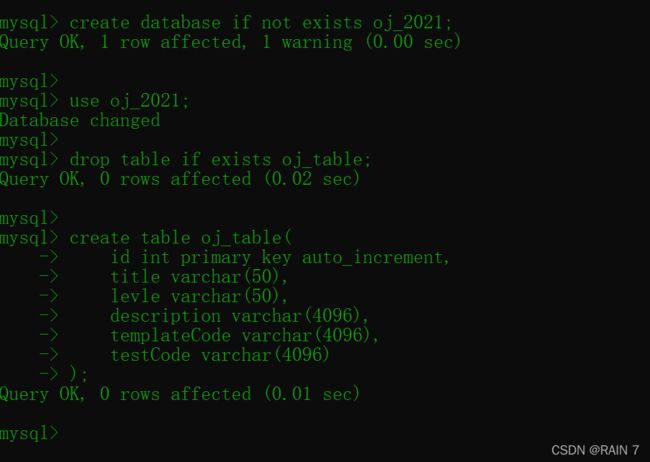
然后我们把写好的sql语句复制到 mysql 客户端上面,如果没有问题的话,就成功建库建表了。
JDBC 连接数据库
JDBC都是固定的写法,就不多说了…
把有关数据库的操作封装成一个DBUtil,里面的功能有:
获取数据库实例
获取数据库连接
回收资源
package common;
import com.mysql.cj.jdbc.MysqlDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class DBUtil {
//创建数据源DataSource
// DataSource 这个东西一般一个程序里有一个实例就够了~~
// 所以我们这里采用单例模式
private static volatile DataSource dataSource = null;
//数据库的URL
private static final String URL = "jdbc:mysql://127.0.0.1:3306/oj_project?characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true";
//数据库的用户名
private static final String USERNAME = "root";
//数据库的密码
private static final String PASSWORD = "";
// 目的是只创建出一个 DataSource 实例
private static DataSource getDataSource() {
if (dataSource ==null) {
synchronized (DBUtil.class) {
if (dataSource == null) {
// 没有被实例化过, 就创建一个实例
dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl(URL);
((MysqlDataSource)dataSource).setUser(USERNAME);
((MysqlDataSource)dataSource).setPassword(PASSWORD);
}
}
}
// 如果已经被实例化过了, 就直接返回现有的实例
return dataSource;
}
//获取连接
public static Connection getConnection() {
try {
return getDataSource().getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
// 回收资源
public static void close(Connection connection, PreparedStatement statement, ResultSet resultSet) {
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
封装具体的类对应表中的信息
将表中的信息封装成一个类 problem,在之后我们我进行增删改查操作
public class Problem {
//题目的编号
private int id;
//题目的标题
private String title;
//题目的难度级别
private String level;
//题目的详细描述
private String description;
//题目的模板代码
private String templateCode;
//题目的测试用例代码
private String testCode;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getLevel() {
return level;
}
public void setLevel(String level) {
this.level = level;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public String getTemplateCode() {
return templateCode;
}
public void setTemplateCode(String templateCode) {
this.templateCode = templateCode;
}
public String getTestCode() {
return testCode;
}
@Override
public String toString() {
return "Problem{" +
"id=" + id +
", title='" + title + '\'' +
", level='" + level + '\'' +
", description='" + description + '\'' +
", templateCode='" + templateCode + '\'' +
", testCode='" + testCode + '\'' +
'}';
}
public void setTestCode(String testCode) {
this.testCode = testCode;
}
}
对数据库中的信息增删改查
然后我们在java中对数据库中的内容题目信息进行增删改查操作
这个类里面有如下功能:
添加题目
删除题目
查找所有题目的 id、title、level
根据id查找题目的具体信息
package Util;
import common.DBUtil;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class ProblemdDao {
private static void testInsert() {
ProblemdDao problemdDao =new ProblemdDao();
Problem problem = new Problem();
problem.setTitle("两数之和");
problem.setLevel("简单");
problem.setDescription("给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。\n" +
"\n" +
"你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。\n" +
"\n" +
"你可以按任意顺序返回答案。\n" +
"\n" +
" \n" +
"\n" +
"示例 1:\n" +
"\n" +
"输入:nums = [2,7,11,15], target = 9\n" +
"输出:[0,1]\n" +
"解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。\n" +
"示例 2:\n" +
"\n" +
"输入:nums = [3,2,4], target = 6\n" +
"输出:[1,2]\n" +
"示例 3:\n" +
"\n" +
"输入:nums = [3,3], target = 6\n" +
"输出:[0,1]\n" +
"\n" +
"来源:力扣(LeetCode)\n" +
"链接:https://leetcode-cn.com/problems/two-sum\n" +
"著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。");
problem.setTemplateCode("class Solution {\n" +
" public int[] twoSum(int[] nums, int target) {\n" +
"\n" +
" }\n" +
"\n" +
" \n" +
"}");
problem.setTestCode(" public static void main(String[] args) {\n" +
" Solution solution = new Solution();\n" +
" \n" +
" // testcase1\n" +
" int[] nums = {2,7,11,15};\n" +
" int target = 9;\n" +
" int[] result = solution.twoSum(nums,target);\n" +
" if(result.length==2 && result[0]==0 && result[1]==1){\n" +
" System.out.println(\"Testcase1 OK!\");\n" +
" }else{\n" +
" System.out.println(\"Testcase1 failed!\");\n" +
" }\n" +
" \n" +
" \n" +
" // testcase2\n" +
" int[] nums2 = {3,2,4};\n" +
" int target2 = 6;\n" +
" int[] result2 = solution.twoSum(nums2,target2);\n" +
" if(result2.length==2 && result2[0]==1 && result2[1]==2){\n" +
" System.out.println(\"Testcase2 OK!\");\n" +
" }else{\n" +
" System.out.println(\"Testcase2 failed!\");\n" +
" }\n" +
" }");
problemdDao.insert(problem);
}
private static void testDelete(int id ) {
ProblemdDao problemDAO = new ProblemdDao();
problemDAO.delete(id);
}
private static List<Problem> testSelectAll(){
ProblemdDao problemdDao = new ProblemdDao();
List<Problem> problems = problemdDao.selectAll();
return problems;
}
private static Problem testSelectOne(int id){
ProblemdDao problemdDao = new ProblemdDao();
Problem problem = problemdDao.selectOne(id);
return problem;
}
//往数据库插入一条信息
public void insert(Problem problem){
//和数据库建立连接
Connection connection = DBUtil.getConnection();
//拼装sql语句
PreparedStatement statement =null;
String sql = "insert into oj_table values(null,?,?,?,?,?)";
try {
statement = connection.prepareStatement(sql);
statement.setString(1,problem.getTitle());
statement.setString(2,problem.getLevel());
statement.setString(3,problem.getDescription());
statement.setString(4,problem.getTemplateCode());
statement.setString(5,problem.getTestCode());
//3.执行sql
int ret = statement.executeUpdate();
if(ret==1){
System.out.println("题目插入成功!");
}else{
System.out.println("题目插入失败!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBUtil.close(connection,statement,null);
}
}
public void delete(int Id){
//建立连接
Connection connection=DBUtil.getConnection();
PreparedStatement statement=null;
//拼装SQL
String sql="delete from oj_table where id=?";
try {
statement=connection.prepareStatement(sql);
statement.setInt(1,Id);
//执行SQL
int ret=statement.executeUpdate();
if(ret==1){
System.out.println("题目删除成功!");
}else{
System.out.println("题目删除失败!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//释放连接
DBUtil.close(connection,statement,null);
}
}
//查找全部题目(用来实现题目列表功能)
//只需要查找 id title level
public List<Problem> selectAll(){
List<Problem> problems=new ArrayList<>();
//建立连接
Connection connection= null;
PreparedStatement statement=null;
//拼装SQL
String sql="select id,title,level from oj_table";
try {
connection = DBUtil.getConnection();
statement=connection.prepareStatement(sql);
//执行SQL
ResultSet resultSet=statement.executeQuery();
while(resultSet.next()){
Problem problem=new Problem();
problem.setId(resultSet.getInt("id"));
problem.setTitle(resultSet.getString("title"));
problem.setLevel(resultSet.getString("level"));
problems.add(problem);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
DBUtil.close(connection,statement,null);
}
return problems;
}
//查找指定题目(实现题目详情页面功能)
//需要Problem的每个字段
public Problem selectOne(int id) {
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
// 1.建立连接
connection = DBUtil.getConnection();
// 2.拼装SQL语句
String sql = "select * from oj_table where id=?";
statement = connection.prepareStatement(sql);
statement.setInt(1, id);
// 3. 执行SQL
resultSet = statement.executeQuery();
// 4. 遍历查询结果。(如果 id 是主键,按照id 查找的结果一定是唯一的)
if(resultSet.next()) {
Problem problem = new Problem();
problem.setId(resultSet.getInt("id"));
problem.setTitle(resultSet.getString("title"));
problem.setLevel(resultSet.getString("level"));
problem.setDescription(resultSet.getString("description"));
problem.setTemplateCode(resultSet.getString("templateCode"));
problem.setTestCode(resultSet.getString("testCode"));
return problem;
}
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
DBUtil.close(connection, statement, resultSet);
}
return null;
}
public static void main(String[] args) {
ProblemdDao problemdDao = new ProblemdDao();
// testInsert();
// testInsert();
// testInsert();
// testDelete(4);
// System.out.println(testSelectAll());
// System.out.println(testSelectOne(3));
// testDelete(1);
// testDelete(2);
// testDelete(3);
// testDelete(4);
testInsert();
System.out.println("插入数据成功!!!");
}
}
API 模块
我们实现了数据库的相关操作封装以后,
接下来就要实现服务器提供给的具体API
通过这些HTTP 接口来与前端进行交互
所以我们一定要考虑前端页面有哪些,具体的页面需要我们返回什么信息,以及返回什么格式的信息,这是很重要的,一定要提前商量好!
API 设计
1. API 与前端的那些界面相对应
我们前端具体要有哪几个显示页面,目前我们只考虑一个OJ系统最核心的相关功能。
题目列表页
题目详情页
2.具体要返回什么信息,什么格式来返回?
题目列表页
功能如下:
(1)展示当前题目的列表,向服务器请求 题目列表
题目详情页
功能如下:
(1)展示题目的详细要求,向服务器请求,获取指定题目的详细信息。
(2)能够有一个代码编辑框,来让用户编辑代码(这个过程不需要与服务器进行交互)
(3)有一个提交按钮,点击提交能把用户编辑的代码发到服务器上,服务器进行编译和运行并返回标准输出的结果。
这个项目里面你具体实现了哪些api来进行前后端的交互呢?
这个项目中,具体有关项目的Api. 要是根据前端页面来进行设计的。
在这个项目中,我们的前端页面主要有两个,一个是展示题目列表,一个是获取到题目详情页。
题目列表页
题目列表页的功能主要是向服务器进行请求,获取到数据库中的题目的相关信息。这里有向服务器端发送请求的一个操作,所以这里要设置一个API,来获取数据库题目列表

题目详情页
题目详情页主要有三个功能,
第一功能是提供这个题目的具体信息。
这里要向这个服务器发送一个http请求。获取到数据库中的题目的具体信息,并返回响应给前端页面。

这里存在一个问题,testCode测试用例 要不要返回给前端,不需要,所以我们不需要获取到testCode,或者把testCode固定设为空字符串
第二个功能就是在前端页面中有一个代码编辑框中,用户可以在这个代码编辑框中编写代码,这是一个纯前端的一个操作,没有向服务器发送HTTP请求,所以我们在这里不需要设计一个API。
第三个功能是有一个提交按钮,我们的用户在编写完相关代码点击提交按钮,这时会向这个服务器端发送一个http请求。然后在服务器端对用户上传的代码进行编译运行,并把结果返回给前端页面进行展示。这也也要设计一个API。

返回数据的格式是什么?怎么返回这种格式?
咱们现在比较流行的前后端交互的方式,主要是通过JSON 来组织的。JSON格式解析,需要引入第三方库 Jackson,引入Jackson依赖到pom.xml
具体的API 是怎么设计的,需要返回哪些信息?
题目列表页 :向服务器请求,返回题目列表
向服务器发送用户当前编写的代码,并获取到结果。
设计API的时候,点击提交会发生什么?
如何将用户提交的代码发送到服务器中?
post请求就把代码放到body中即可。
这里就涉及到一个本质的面试问题!
GET 和POST 的区别

id很关键,关键服务器要根据id从数据库中拿到测试用例代码。用户提交的代码拼接成一个完整的可以编译运行的代码,然后服务器才能够编译运行,返回响应。
API 设计小结
接下来的开发,主要是为了实现这几个具体的API,在这里也提醒大家一句:在们在实现Web开发的时候,前后端交互一定是一个非常重要,非常关键的一个环节,这里API 设计的是否合理直接关系到后面的代码编写,所以一定要和前端后端沟通好具体的信息格式等内容在编写代码逻辑。
API 实现
查找题目列表
@WebServlet("/problem")
public class problemServlet extends HttpServlet {
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 规定响应的格式以及字符集
resp.setContentType("application/json");
resp.setCharacterEncoding("utf8");
// 查找题目列表
List<Problem> problems = new ArrayList<Problem>();
problemdao problemdao = new problemdao();
problems = problemdao.selectAll();
// 将problems 的内容装换成JSON格式的字符串
String resqString = objectMapper.writeValueAsString(problems);
// 写入到resp响应中
resp.getWriter().write(resqString);
}
}
查找题目列表的路由是 “/problem” ,后面不带参数。
将数据库中的内容得到后,转换成JSON格式的字符串写入到响应中。
设置返回HTTP响应的body部分,我们呢要规定body的类型是JSON
查找题目详情
查找题目详情,此时路由/problem如果有参数,那么就是请求查找路由详情。
在刚才的查找题目列表的API中,加上一个判断queryString 的id是否存在,如果查到了,就按照这个id在数据库中进行查找并返回对应的题目,装换成JSON格式返回给响应。
@WebServlet("/problem")
public class problemServlet extends HttpServlet {
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setStatus(200);
resp.setContentType("application/json");
resp.setCharacterEncoding("utf8");
String id = req.getParameter("id");
if("".equals(id) || id==null){
// 查找题目列表
List<Problem> problems = new ArrayList<Problem>();
problemDao problemdao = new problemDao();
problems = problemdao.selectAll();
// 将problems 的内容装换成JSON格式的字符串
String resqString = objectMapper.writeValueAsString(problems);
// 写入到resp响应中
resp.getWriter().write(resqString);
}else{
// 查询对应id 的题目详情
Problem problem = new Problem();
problemDao problemdao = new problemDao();
problem = problemdao.selectOne(Integer.parseInt(id));
String respString = objectMapper.writeValueAsString(problem);
resp.getWriter().write(respString);
}
}
上传用户代码到服务器进行编译运行
这里我们要先提一个思路,因为用户提交的代码是不能直接进行编译的,那么怎么到服务器运行呢?
用户提交的代码,只是一个 Solutuion这样的类,里面包含了一个核心方法。
而要是想能够单独的编译运行,就需要一个main方法
main方法就在测试用例代码中,测试用例代码就在数据库中。
我们只需要截取 用户代码到最后一个 } 之前,然后将 测试用例的 main方法拼接过来,再加上 },就变成了一个完整的可编译运行的代码了。
0、创建一个 compileServlet 继承HTTPServlet,重写doPost方法
1、为了更方便的取到 请求和响应的具体信息,我们自己创建一个静态内部类,分别表示请求的信息 和响应的信息。
(当前针对编译运行请求来说,请求和响应都是JSON格式的数据,为了方便解析和构造,就可以创造两个类,来对应两个JSON结构)

static class compileRequest{
int id;
String code;
}
static class compileResponse{
int error;
String reason;
String stdout;
}
2、先要搞清楚处理post请求的逻辑
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 1. 读取 请求的正文 ,按照 JSON 格式进行解析
// 读取正文只能 getInputStream() 读取字节流
// 2. 按照id 从数据库中查找到题目的详情 --> 拿到这个题目的测试用例
// 3. 把测试用例 和 用户提交的代码进行拼接,拼装成一个完整的代码
// 4. 创建一个Task实例,调用里面的 compileAndRun 来进行编译运行这个完整的代码
// 5. 根据 Task返回的结果包装成一个 HTTp 响应返回
}
提交请求至服务器的全部逻辑
- 读取 请求的正文 ,按照 JSON 格式进行解析 读取正文只能 getInputStream() 读取字节流
- 按照id 从数据库中查找到题目的详情 --> 拿到这个题目的测试用例
- 把测试用例 和 用户提交的代码进行拼接,拼装成一个完整的代码
- 创建一个Task实例,调用里面的 compileAndRun 来进行编译运行这个完整的代码
- 根据 Task返回的结果包装成一个 HTTp 响应返回
读取请求正文的方法readBody()
private String readBody(HttpServletRequest req) throws UnsupportedEncodingException {
//1 .根据 请求头 中的 ContentLength 能够拿到 body 的长度
int length = req.getContentLength();
// 按照这个长度创建一个缓冲数组
byte[] buffer = new byte[length];
InputStream inputStream = null;
try {
// 通过req的 getInputStream() 方法,获得 body的流对象
inputStream = req.getInputStream();
//基于这个流对象,读取内容,返回到一个byte[]数组中即可
inputStream.read(buffer);
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
// 把这个byte数组构造成一个字符串即可
return new String(buffer,"utf8");
}
最后我们在构建字符串的时候,加了字符编码方式,为什么呢?
return new String(buffer,utf8);
这个代码就相当于,把一个二进制的文件,转换成一个文本数据。
byte[] 单纯的二进制 ,以字节为单位
String 就是一个文本数据,以字符为单位
到底在这个情境下,是几个字节算一个字符呢?
就需要给他指定一下字符集,知道编码方式,也就知道了那些字节要放到一起构造成一个字符。
Java中的char不就是固定了两个字节吗?(按照unicode方式编码)
但是从请求中读取的body不一定是这样的,需要在构造String的时候告诉当前的byte 是按照什么方式编码,最终构造成 unicode 的方式。
得到body的正文之后还得赋值给 CompileRuest对象
// 得到 body中的JSON字符串后,要给请求的对象赋值
CompileRequest compileRequest = objectMapper.readValue(body,CompileRequest.class);
这里的readValue 就是genuine类对象,获取到CompileRequest这个类都有哪些属性,叫啥名字,依次遍历这些属性。例如拿到 id属性,就去JSON字符串中找到key为id 的键值对,赋值给CompileRequest 的 id字段中
拿到测试用例代码,并和用户提交的代码进行拼装
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 1. 读取 请求的正文 ,按照 JSON 格式进行解析
// 读取正文只能 getInputStream() 读取字节流
String body = readBody(req);
// 得到 body中的JSON字符串后,要给请求的对象赋值
CompileRequest compileRequest = objectMapper.readValue(body,CompileRequest.class);
// 2. 按照id 从数据库中查找到题目的详情 --> 拿到这个题目的测试用例
problemDao problemDao = new problemDao();
Problem problem = problemDao.selectOne(compileRequest.id);
String testCode = problem.getTestCode();
String requestCode = compileRequest.code;
String finalCode = marge(requestCode,testCode);
// 3. 把测试用例 和 用户提交的代码进行拼接,拼装成一个完整的代码
// 4. 创建一个Task实例,调用里面的 compileAndRun 来进行编译运行这个完整的代码
// 5. 根据 Task返回的结果包装成一个 HTTp 响应返回
}
具体的拼装代码的逻辑
private String marge(String code, String testCode) {
int index = testCode.lastIndexOf("}");
if(index==-1){
// 说明提交的代码没有找到},显然是非法的代码
return null;
}
//根据找到的下标进行字符串截取
String tmp = testCode.substring(0,index);
return tmp+testCode+"\n}";
}
所谓的合并就是 把testcode 里面的main 方法给嵌入到 requestCode中。
做法就是 把testCode 给放到Solution 的最后一个 } 的前面即可。
(1) 先在 requestCode 查找以下最后一个 } 的位置 lastIndexOf,如果index==-1,说明没有找到就返回null
(2) 根据刚才的结果,进行字符串截取。
(3) 把刚才截取的结果拼接上测试用例的代码,在拼接上一个}即可。
编译运行finalCode
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 1. 读取 请求的正文 ,按照 JSON 格式进行解析
// 读取正文只能 getInputStream() 读取字节流
String body = readBody(req);
// 得到 body中的JSON字符串后,要给请求的对象赋值
CompileRequest compileRequest = objectMapper.readValue(body,CompileRequest.class);
// 2. 按照id 从数据库中查找到题目的详情 --> 拿到这个题目的测试用例
// 3. 把测试用例 和 用户提交的代码进行拼接,拼装成一个完整的代码
problemDao problemDao = new problemDao();
Problem problem = problemDao.selectOne(compileRequest.id);
String testCode = problem.getTestCode();
String requestCode = compileRequest.code;
String finalCode = marge(requestCode,testCode);
// 4. 创建一个Task实例,调用里面的 compileAndRun 来进行编译运行这个完整的代码
// 5. 根据 Task返回的结果包装成一个 HTTp 响应返回
Task task = new Task();
Question question = new Question();
Answer answer = null;
question.setCode(finalCode);
try {
answer = task.compileAndRun(question);
} catch (InterruptedException e) {
e.printStackTrace();
}
CompileResponse compileResponse = new CompileResponse();
compileResponse.error = answer.getError();
compileResponse.reason = answer.getStderr();
compileResponse.stdout = answer.getStdout();
String respString = objectMapper.writeValueAsString(compileResponse)
resp.getWriter().write(respString);
}
接下来,我们来处理一下里面异常请求的情况
异常处理
如果我们查找题目的id 找不到具体的信息,那么就会返回null,我们就需要告诉前端页面,查找的题目不存在。

如果用户提交的代码不符合要求,拼装的时候就会找不到},返回一个null
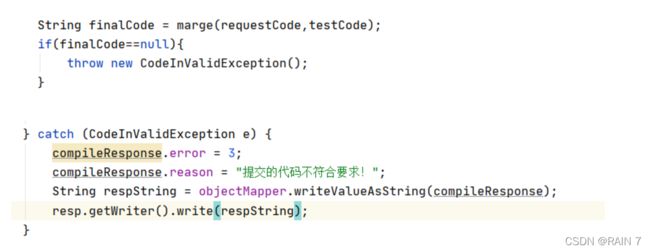
用户提交的代码中如果带有影响服务器的代码字段,我们会编译期间遍历代码中的字段,如果包含 黑名单中的字段,返回结果,提示提交代码可能危害服务器。
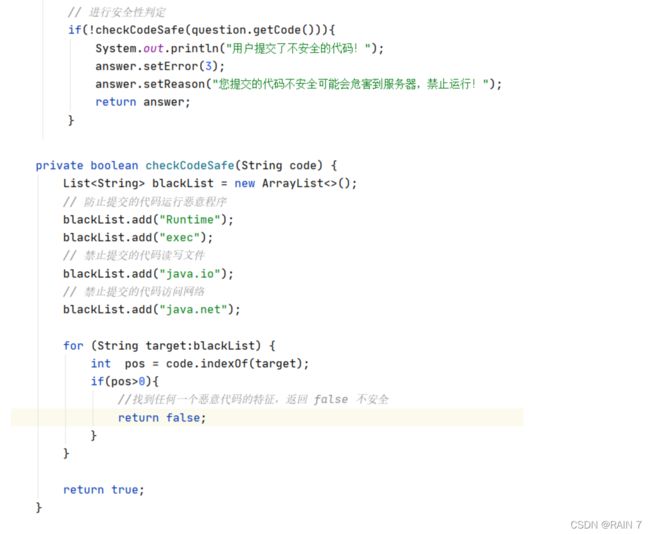
区分不同目录的文件
现在有一个严重的问题,每次有一个请求过来,都需要生成这样一组临时文件,如果同一时刻有N个请求过来了,这些请求的临时文件的名字和所在的目录都是一样的,此时多个请求之间就会痴线""相互干扰"的情况
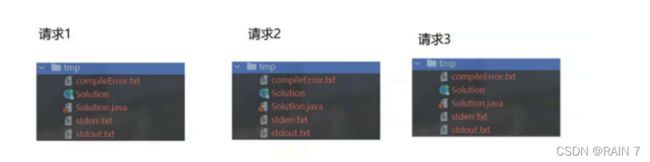
这三个请求中的题目的id 和提交代码是一样的吗? 显然不一样,因为这三个请求来自于三个不同的用户啊。
在之前的编译运行之后,每个子进程的文件都放在了 tmp目录下面,会导致最后的文件管理很混乱,所以在这里我们就引入了UUID 的使用
我们使用的方法就是 让每一个请求,都有一个自己的目录来生成这些临时文件,这样的话就不存在干扰了。
因此咱们要做的事情就是让每个请求创建的WORKDIR目录都不相同。
UUID是计算机中一个非常常用的概念,表示一个全世界都唯一的id
每次生成一个UUID,这个UUID就是唯一的(背后也是通过一系列算法实现的)
每次请求都生成一个以UUID命名的临时目录,请求生成的临时文件都放到这个临时目录就可以了,由于UUID不同,所以请求之间就不再相互影响了。
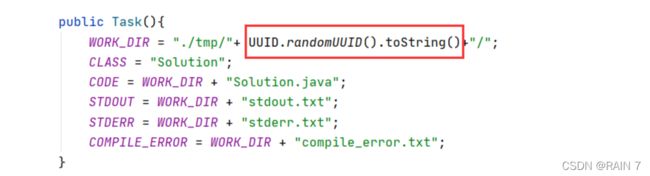
在Task类中初始化的时候,在构造方法里面加一个UUID 的临时目录。
后端部分就到这里了,我们把前端的相关资源也配置到项目中,一块打包到Linux系统的 tomcat上,开放Linux上tomcat的端口号即可访问。
希望大家多多练习!!
贴一下项目源码:想看的可以看看
项目展示:http://82.156.167.56:8080/oj_2021/index.html
Gitee源码:https://gitee.com/rain7-7/daily-code-practice—java/tree/5129ac10588aedb49c2dce7cb1a9d3e9c5a20046/2021_oj_project