(5-0)基于 Verilog HDL 的卷积神经网络 AI IP 设计
NOTES:如上,我们已经具备了成熟的车牌识别系统的卷积神经网络 Model,根据模型指定的不同层数及其具体参数,通过 Verilog HDL 设计一个个的 IP,以搭积木的方式,来完成卷积神经网络的硬件加速 IP 设计。
1、关于设计
 不同层次的矩阵维度
不同层次的矩阵维度
2、关于代码
2.1、UnResize
128*64 = 8192 个字符分割之后的二值化数据存储在一块 BRAM 中,然后通过基于 AXI4-Stream 流协议的形式进行输出,即当 UnResize IP 的 m_axis_tvalid && m_axis_tready 同时拉高的时候,便开始一个一个地输出数据(延时为 2)。(可通过Vivado 的 Tools - Create and Package New IP - Create AXI4 Peripheral - Add Interface - M00_AXIS)
2.2、Resize
对 128*64 的 4*2 窗口进行操作,取 2*2 和 3*2 的第二行和第三行作为一个窗口,当超过一个 1,则输出 1,反之输出 0,这样,就能够达到输出 32*32 的目的了。(当然,这里涉及到行缓存,状态机如行缓存中有效操作中换行中终止计时中的状态机 - 定时器模块)
2.3、First_Fill
第一层填充之前,有一个 Ready_Resize 的状态机 - 定时器模块,这是由于我们的输入数据流是连续的,而前面的缩放操作并不能够连续输出数据流,比如换行的时候就会中断数据流的产生,所以,我们需要一个 FIFO 来暂时缓存大部分的数据,使得其接下来能够连续进行输出然后输入到下一个单元中。
当连续的 32*32 数据流开始到来的时候,我们暂时缓存到 FIFO 中,开启状态机 - 定时器模块,进行 0 填充,此时,需要一个数据选择器,选择 0 数据还是有效的 32*32 数据,填充完毕之后,则转换到有效数据的数据,然后再填充再输入,直到填充完毕,输出为 34*34 的矩阵维度。
2.4、First_CNN
由于填充是连续填充的,所以 34*34 的数据输出也是连续输出的,所以这里就不需要添加一个连续使能的状态机 - 定时器模块。
值得注意的是,由于第一层卷积层是采用查找表的形式,所以无需所谓的窗口乘加操作和激活函数 ReLU 操作(这里,是因为输入特征图为像素为单比特二进制数据,并且,通过基于 Python 上的数据我们发现,在经过 ReLU 模块之前,大部分的数值为为负值,在经过 ReLU 模块之后,大部分的数值为 0,即数据的输出具有稀疏性。那么,我们可以通过已给的卷积参数以及所有可能的 9 位二进制的所有情况来直接手动计算出对应的输出值 K(K << N),K 为稀疏度,所以就采用了最符合 Xilinx FPGA 架构的查找表的形式来进行设计,简直 Nice)。这边需要 8 份查找表,所以卷积完之后,便输出 32*32*8 的矩阵维度;
2.5、First_Pool
同样,由于前面的卷积模块输出的数据流不是连续的,所以在第一层池化层之前,有一个 Ready_CNN 的状态机 - 定时器模块和一个 FIFO 来暂时缓存大部分的数据,使得其接下来能够连续进行输出然后输入到下一个单元中。
然后池化层就是对 2*2 的窗口进行寻找最大值操作,通过比较操作,输出 4 个数中的最大值,作为池化层的输出,所以最终的池化层输出 16*16*8 的矩阵维度。
2.6、Second_Fill
同样,由于前面的卷积模块输出的数据流不是连续的,所以在第一层池化层之前,有一个 Ready_Pool 的状态机 - 定时器模块和多个 FIFO 来暂时缓存大部分的数据,使得其接下来能够连续进行输出然后输入到下一个单元中。
类似前面的 First_Fill 操作,最终输出 18*18*8 的矩阵维度。
2.7、Second_CNN
紧接着前面的连续数据流,进行卷积操作,共 8 张输入特征图,针对每张输入特征图,有 3*3*8 的卷积核,所以最终输出为 16*16*8 的矩阵维度。
2.8、Second_ReLU
线性激活函数,针对每个数据输出,有如下公式:Output = Max(Feature,0)。
2.9、Second_Pool
同样,由于前面的卷积模块输出的数据流不是连续的,所以在第一层池化层之前,有一个 Ready_Second_CNN 的状态机 - 定时器模块和多个 FIFO 来暂时缓存大部分的数据,使得其接下来能够连续进行输出然后输入到下一个单元中。
同样,池化层就是对 2*2 的窗口进行寻找最大值操作,输出 4 个数中的最大值,作为池化层的输出,所以最终的池化层输出 8*8*8 的矩阵维度。
2.10、Full_Connect
同样,由于前面的卷积模块输出的数据流不是连续的,所以在第一层池化层之前,有一个 Ready_Second_CNN 的状态机 - 定时器模块和多个 FIFO 来暂时缓存大部分的数据,使得其接下来能够连续进行输出然后输入到下一个单元中。
然后进行张量(三维矩阵)的展开,展开成一维列向量,也就是 8*8*8 展开为 512*1,如何展开呢?就是按照顺序,先是第一张图的 8*8 特征图按照从左到右自顶向下展开为 64*1 的列向量,然后依次再按照特征图的顺序拼接,即可拼接为 512*1 的列向量维度。
这里,进行矩阵的分块操作,如下所示(这部分属于加速策略部分,这里不加以赘述,后续会有一个专门的章节来详解):
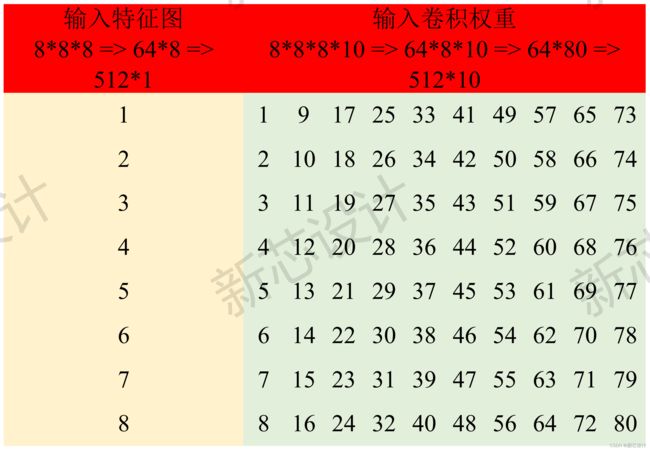 全连接层中矩阵分块的设计策略
全连接层中矩阵分块的设计策略
2.11、Softmax
全连接层的输出是 10*1 的数组,比较十个数据的大小,找出最大的那个数据,接着输出最大数据所在的位置,该位置(Index)就是所识别的字符。
2.12、整体流程如上(温故而知新)
3、关于工程
关注“新芯设计”公众号,发送 AI Verilog 即可获取(区分大小写)。