吴恩达机器学习笔记(八)——深入神经网络
注:在吴恩达老师的机器学习的视频中,神经网络部分更多的讨论是在分类方面的应用。
1. 代价函数
首先,我们拥有如下的神经网络架构,如下图所示:

然后我们拥有如下的训练集,如下图所示:
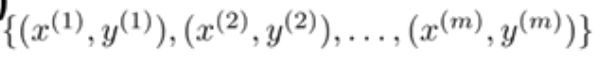
接下来我们需要定义两个概念:
L = 神经网络的总层数
sl = 第l层中的单元数(不包括偏置单元)如上图s1=3、s2=5
并且从之前的知识,我们也了解到:当进行二元分类的时候,输出层会只有一个单元。当进行多元分类的时候,输出层会有多个单元,因为输出的是一个向量。如下图所示:

因此对比于简单逻辑回归的代价函数,我们可以定义出神经网络的代价函数,具体如下图所示:
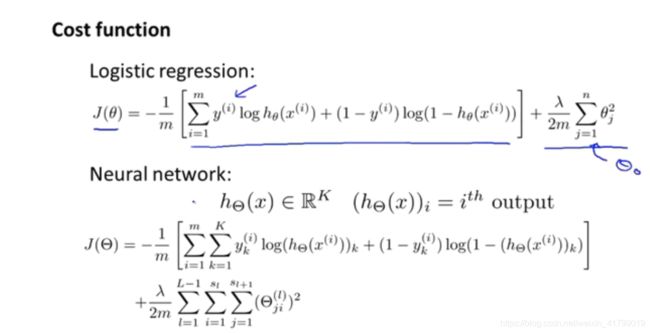
上图中需要注意的地方主要有以下几个:
- 当输出层有多个单元的时候,hθ(x)会是一个K维的向量。
- (hθ(x))i表示的是输出单元中,第i个单元的输出值。
- 第一个求和符号中的K,表示对K维向量计算误差值。
- 在正则化项中,和逻辑回归一样,我们不需要对偏执单元进行正则化,因此i和j的下标都是从1开始的。
2. 反向传播算法
注:这里介绍反向传播算法只是根据吴恩达老师视频中的知识进行介绍,可能比较简略。具体的反向传播算法的原理我会在下一篇文章中详细介绍。
对于上一个小节定义的代价函数,我们同样要进行梯度下降或者采用更为高级的优化算法去求得最优的参数θij(l)。
为了达到这个,我们在进行计算的时候,需要计算下面两项:

1.第一项就根据上面的表达式计算即可。
2.第二项直接计算就比较麻烦了,因此这里就引入了反向传播算法。
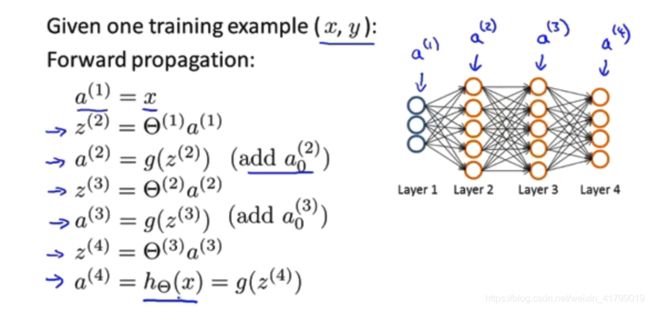
首先,我们需要根据输入层的数据,完成前向传播,具体如下图所示:
然后我们就可以进行反向传播,具体过程如下图:
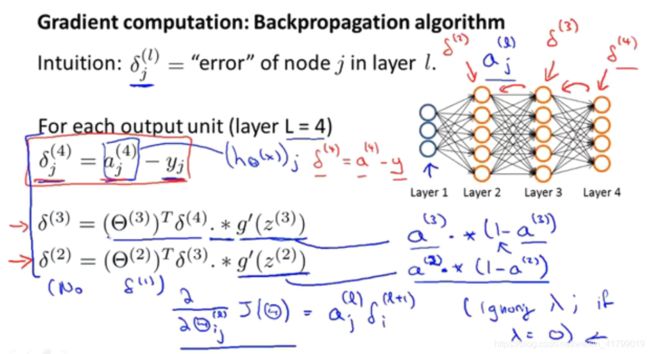
反向传播算法的具体流程如下面几点(具体推导在下一篇文章中会展示):
- 首先我们要定义一个δj(l),它代表第l层中第j个节点的误差值
- 然后因为我们通过训练集是可以知道真实值y的,因此输出层的误差是可以直接计算出来的,也就是δj(4)=aj(4)-yj 。 并且我们可以写成向量形式,从而得到δ(4)=a(4)-y
- 然后我们进一步可以得到δ(3)、δ(2),根据上面的公式计算即可。并且我们对公式进一步展开,还可以得到g’(z(3))=a(3)(1-a(3))、 g’(z(2))=a(2) *(1-a(2))。
- 需要注意的是,我们是不用计算δ(1)的,因为输入层是没有误差的
- 最后,我们就可以得到偏导数(忽略正则项的情况下),如下图所示:

接着,我们使用文字的形式来表述反向传播算法,如下图所示:

上图中需要注意的点有以下几个:
- Δij(l)其实是δ的大写形式,是用来求每一个样本的J(θ)对于θij(l)的偏导数之和,然后最后再取一个均值,也就是最后Dij(l)中除以m
- 需要注意的是图中的For i =1 to m 和 Δij(l)中的i不是同一个i
- Dij(l) 是处于for循环之外的
3. 图示理解反向传播算法
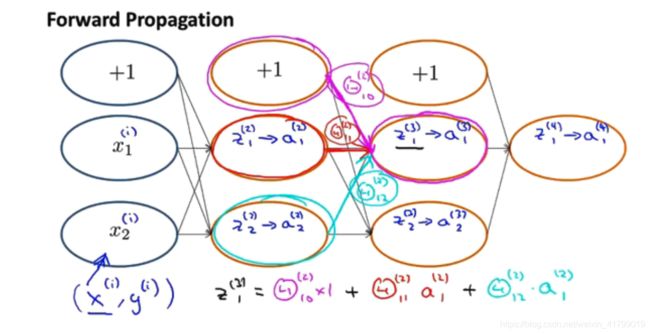
要理解反向传播,首先要理解前向传播算法。前向传播算法比较简单,相信小伙伴们也能够很轻松理解,所以这里就不过多解释了,直接上图,如下图所示:
接下来,我们来理解反向传播算法:
我们先定义一个式子,如果忽略神经网络的代价函数中的正则项,并且假设只有一个输出单元,那么下面两项是可以近似等价的,如下图所示:
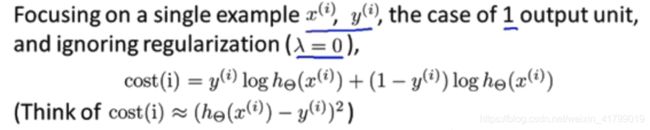
接着,我们对δj(l)进行定义(这里定义的δj(l)=cost(i)对zj(l)的偏导数会在下一篇文章中详细介绍),如下图所示:
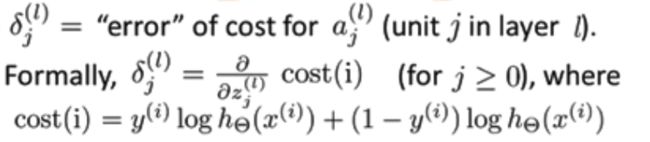
接着我们对反向传播的过程进行可视化,如下图所示:

上图中需要注意的点有以下几个:
- 上图中反向传播中δj(l)的计算,吴恩达老师省略了g’(z(l))=a(l)(1-a(l))的计算,可能老师是想让我们更加清晰的理解过程,它其实也相当于一个常数。
- 反向传播其实和正向传播原理是一致的,只是方向相反而已。也是用上一层的δj(l)乘以权重,再乘以导数项得到结果的。
- δj(l)通常不会包含偏置单元。
4. 展开参数
因为这一节老师使用Octave进行实现的,但我是使用python进行实现的,因此这里就不过多总结了。主要就讲了以下几个方面:
- 在一些高级优化算法调用时,theta一般都是默认是一个参数向量的。但是在神经网络中,theta是一个矩阵,这时就需要我们把theta首先转换成一个向量,计算完成后再reshape回原来的形状。
5. 梯度检测
在进行神经网络的具体实现的时候,很容易出bug,因此通常会使用梯度检测的方法来检验神经网络的实现是否正确。
具体的思想就是我们通常会使用一个表达式来近似某一点的导数,如下图所示:
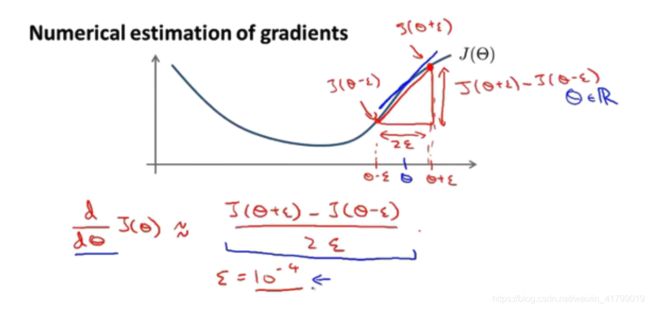
需要注意的点有以下几个:
- ε通常是一个很小的数,当ε无限小,其实取极限就是导数。
- 上图中使用的双侧差分。但是有人会使用[J(θ+ε)-J(θ)]/ε,这种叫做单侧差分。但是单侧差分准确率一般没有双侧差分高,因此一般不使用。
我们对上面的思想进行扩展,就可以得到向量形式,如下图所示:

具体实现的伪代码如下图所示:

最后,使用了这个方法之后,我们就需要比较所有参数的偏导数的计算和我们在进行反向传播得到的梯度进行比较。验证这两个数是否近似相等,如果是的话说明反向传播的计算是正确的,否则计算是有问题的。
最后的最后,我们需要记住,在进行实际的计算(计算得到最优theta)的过程中,我们必须要关掉梯度检测的代码,否则会运行的很慢。因为反向传播是效率很高的算法,而梯度检测则是很慢的,因此验证正确后就需要关掉。
6. 随机初始化
在线性回归和逻辑回归中,我们都需要初始化θ数组,并且我们通常会用0来进行初始化。
同样地,在神经网络中,我们也需要初始化θ数组,但是这时我们就不能使用0来进行初始化。具体问题如下图所示:

对于上图我们需要注意的有以下几点:
- 如果所有参数都初始化为0,那么将会导致所有权重都一样。也就是最开始a1(2)=a2(2),紧接着所有参数都是一样的。
- 在进行梯度变化的过程中,虽然之后都会进行变化,但是权重会始终保持一样,即蓝色的权重等于蓝色的权重,红色的权重等于红色的权重,绿色的权重等于绿色的权重,这样就会一直使a1(2)=a2(2),从而得不到很好的学习效果。
为了解决这个问题,就提出了随机初始化的思想,就是采用随机数来赋值权重,如下图所示:

7. 知识整合
下面通过前面学到的知识来整合神经网络构建的步骤。
1、我们要构建神经网络的整体架构。

我们需要注意以下几个点:
- 首先要确定输入层和输出层的单元数
- 然后,较为合理的默认选择是只有一层隐藏层(如图一架构)。如果有多个隐藏层,那么每个隐藏层的单元数最好相同(虽然更多的单元数会得到更好的结果,但是也要考虑到计算量)
- 隐藏层的单元数还应该和输入层的单元数相匹配,可以是1倍、2倍、3倍4倍等。
2、随机初始化权重
通常我们会把权重初始化为很小的值,接近于0
3、执行前向传播算法
对于任意的x(i)都计算出对应的hθ(x(i)),也就是得到输出层的向量
4、代码实现计算代价函数J(θ)
5、执行反向传播算法
通过执行反向传播算法,计算
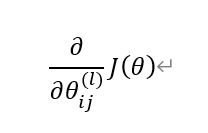
也就是进行如下过程:(第一次实现的时候建议用for循环,不要用向量化)

6、进行梯度检测
比较反向传播算法得到的导数值和估计的导数值是否近似相等。
检测完成后记得禁用梯度检测
7、进行梯度下降或使用高级优化算法
使用梯度下降或高级优化算法和反向传播算法相结合,从而去得到J(θ)的最小值和最优的权重θ。
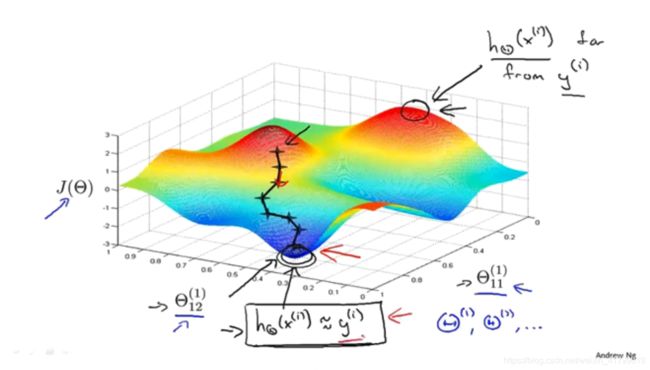
另外,因为神经网路的代价函数不是一个凸函数,因此可能寻找到的是局部最小值,但是对于大部分情况还是效果比较好的。
下面这个图就再一次展示了梯度下降的原理。其实反向传播算法计算的偏导数就是在计算梯度下降的方向。