机器学习概念总结笔记(一)——机器学习算法分类、最小二乘回归、岭回归、LASSO回归
原文:https://cloud.tencent.com/community/article/137341
机器学习概念总结
1,机器学习算法分类
1)监督学习: 有train set,train set里面y的取值已知。
2)无监督学习:有train set, train set里面y的取值未知。
3)半监督学习:有train set, train set里面y的取值有些知道有些不知道。
4)增强学习:reinforcement learning, 无train set。
2,常见算法
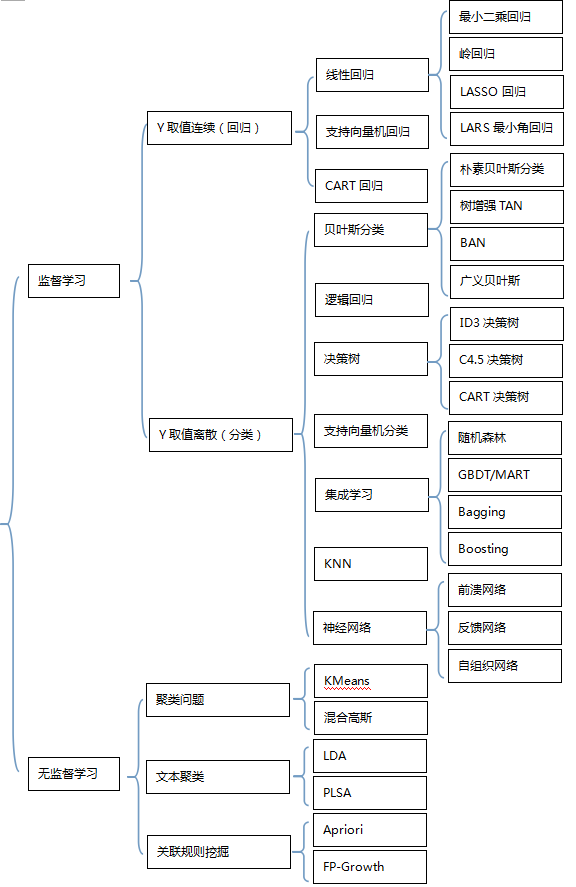
3,算法概念学习
1)最小二乘回归
最小二乘回归(英文名:Ordinary Least Squares Regression[OLS], 又叫Generalized Least Squares[GLS])是常见的线性回归方法。最小二乘法的基本原则是:最优拟合直线应该使各点到直线的距离的和最小,也可表述为距离的平方和最小。
经典线性回归模型的基本假设:(1),残差具有零均值;(2)var <∞,即残差具有常数方差,且对于所有x值是有限的;(3)残差项之间在统计意义上是相互独立的;(4)残差项与变量x无关;(5)残差项服从正态分布;
如果满足假设(1)-(4),由最小二乘法得到的估计量具有一些特性,它们是最优线性无偏估计量(Best Linear Unbiased Estimators,简记BLUE)。1)线性(linear):意味着x与随机变量y之间是线性函数关系;2)无偏(unbiased):意味着平均而言,实际由样本数据得到的x的参数值与其总体数据中的真实值是一致的;3)最优(best):意味着在所有线性无偏估计量里,OLS估计量具有最小方差。
回归常见的3个必须要解决的问题在于:
1)Heterroskedasticity异方差性: 残差的方差不为常数, 残差与x相关(eg,x变大,残差变大), 违反了假设2和4
2)Autocorrelation自相关性:残差项之间自相关,违反了假设3
3)Multicollinearity多重共线性:多个x之间不独立,即xi与xj之间存在相关性。
2)岭回归
岭回归(英文名:ridge regression, Tikhonov regularization)是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法(OLS回归),通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
一般线性回归是最小二乘法回归,残差计算是平方误差项。岭回归(Ridge Regression)是在平方误差的基础上增加正则项,通过确定的值可以使得在方差和偏差之间达到平衡:随着的增大,模型方差减小而偏差增大。
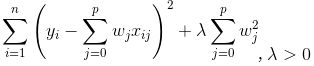
岭回归是对最小二乘回归的一种补充,它损失了无偏性,来换取高的数值稳定性,从而得到较高的计算精度。通常岭回归方程的R平方值会稍低于普通回归分析,但回归系数的显著性往往明显高于普通回归,在存在共线性问题和病态数据偏多的研究中有较大的实用价值。
备注:回归问题时,如果x选择个数太多,会导致模型复杂度膨胀性增大。如果x选择太少,可能导致模型的预测能力不够。x选择数目过多,一方面太复杂,另外一方面会使得构建出来的模型对train set的数据over-fit,导致这个模型应用于test set时效果并不好。因此需要有一个机制来做特征选择,即需要对x的集合有所取舍。特征选择有3种类型:1)子集选择;2)收缩方法(Shrinkage method),又叫做正则化(Regularization),这里就会出现岭回归方法和LASSO回归方法。3)维数缩减,即降维
3)LASSO回归
LASSO回归(英文名: Least Absolute Shrinkage and Selectionator Operator)其实本质是一种降维方法, 由Tibshirani(1996)提出。这种算法通过构造一个惩罚函数获得一个精炼的模型;通过最终确定一些指标的系数为零,LASSO算法实现了指标集合精简的目的。这是一种处理具有复共线性数据的有偏估计。Lasso的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,得到解释力较强的模型。
4)LARS回归
LARS回归(英文名: Least Angle Regression,最小角回归)。Efron于2004年提出的一种变量选择的方法,类似于向前逐步回归(Forward Stepwise)的形式。从解的过程上来看它是LASSO回归的一种高效解法。
最小角回归和模型选择比较像,是一个逐步的过程,每一步都选择一个相关性最大的特征,总的运算步数只和特征的数目有关,和训练集的大小无关。最小角回归训练时的输入为特征矩阵 X={X1,X2,...,XP},和期输出向量Y={y1,y2,...,yN},Xi 是长度为N的矩阵,N表示训练集的大小,P则是特征的数目。还有一点需要注意的是,向量Xi 和 Y 都是正则化之后的向量,即它们的元素的均值为0,且每个向量的长度都是1,这样做的目的是为了后面计算相关性以及角度的方便。
有点像Forward Stepwise(向前逐步回归),但和Forward Stepwise不同点在于,Forward Stepwise每次都是根据选择的变量子集,完全拟合出线性模型,计算出RSS,再设计统计量(如AIC)对较高的模型复杂度作出惩罚,而LARS是每次先找出和因变量相关度最高的那个变量, 再沿着LSE的方向一点点调整这个predictor的系数,在这个过程中,这个变量和残差的相关系数会逐渐减小,等到这个相关性没那么显著的时候,就要选进新的相关性最高的变量,然后重新沿着LSE的方向进行变动。而到最后,所有变量都被选中,估计就和LSE相同了。
LARS的算法实际执行步骤如下: 1. 对Predictors进行标准化(去除不同尺度的影响),对Target Variable进行中心化(去除截距项的影响),初始的所有系数都设为0,此时残差 r 就等于中心化后的Target Variable。 2. 找出和残差r相关度最高的变量X_j。 3. 将X_j的系数Beta_j 从0开始沿着LSE(只有一个变量X_j的最小二乘估计)的方向变化,直到某个新的变量X_k与残差r的相关性大于X_j时。4. X_j和X_k的系数Beta_j和Beta_k,一起沿着新的LSE【Least Squares Estimate最小二乘估计】(加入了新变量X_k的最小二乘估计)的方向移动,直到有新的变量被选入。5. 重复2,3,4,直到所有变量被选入,最后得到的估计就是普通线性回归的OLS。
5)支持向量回归
SVR支持向量回归(英文名: Support-Vector Regression)。支持向量机( SVM )是一种比较好的实现了结构风险最小化思想的方法。它的机器学习策略是结构风险最小化原则 为了最小化期望风险,应同时最小化经验风险和置信范围)
支持向量机方法可以用于回归和分类, 它的基本思想:( 1 )它是专门针对有限样本情况的学习机器,实现的是结构风险最小化:在对给定的数据逼近的精度与逼近函数的复杂性之间寻求折衷,以期获得最好的推广能力;( 2 )它最终解决的是一个凸二次规划问题,从理论上说,得到的将是全局最优解,解决了在神经网络方法中无法避免的局部极值问题;
( 3 )它将实际问题通过非线性变换转换到高维的特征空间,在高维空间中构造线性决策函数来实现原空间中的非线性决策函数,巧妙地解决了维数问题,并保证了有较好的推广能力,而且算法复杂度与样本维数无关。
目前, SVM 算法在模式识别、回归估计、概率密度函数估计等方面都有应用,且算法在效率与精度上已经超过传统的学习算法或与之不相上下。 对于经验风险R,可以采用不同的损失函数来描述,如e不敏感函数、Quadratic函数、Huber函数、Laplace函数等。核函数一般有多项式核、高斯径向基核、指数径向基核、多隐层感知核、傅立叶级数核、样条核、 B 样条核等,虽然一些实验表明在分类中不同的核函数能够产生几乎同样的结果,但在回归中,不同的核函数往往对拟合结果有较大的影响。
支持向量回归算法主要是通过升维后,在高维空间中构造线性决策函数来实现线性回归,用e不敏感函数时,其基础主要是 e 不敏感函数和核函数算法。若将拟合的数学模型表达多维空间的某一曲线,则根据e 不敏感函数所得的结果,就是包括该曲线和训练点的“ e管道”。在所有样本点中,只有分布在“管壁”上的那一部分样本点决定管道的位置。这一部分训练样本称为“支持向量”。为适应训练样本集的非线性,传统的拟合方法通常是在线性方程后面加高阶项。此法诚然有效,但由此增加的可调参数未免增加了过拟合的风险。支持向量回归算法采用核函数解决这一矛盾。用核函数代替线性方程中的线性项可以使原来的线性算法“非线性化”,即能做非线性回归。与此同时,引进核函数达到了“升维”的目的,而增加的可调参数是过拟合依然能控制。
6)CART回归
CART(英文名: Classification And Regression Tree分类回归树),是一种很重要的机器学习算法,既可以用于创建分类树(Classification Tree),也可以用于创建回归树(Regression Tree)。 将CART用于回归分析时就叫做CART回归。
CART算法的重要基础包含以下三个方面:(1)二分(Binary Split):在每次判断过程中,都是对观察变量进行二分。CART算法采用一种二分递归分割的技术,算法总是将当前样本集分割为两个子样本集,使得生成的决策树的每个非叶结点都只有两个分枝。因此CART算法生成的决策树是结构简洁的二叉树。因此CART算法适用于样本特征的取值为是或非的场景,对于连续特征的处理则与C4.5算法相似。(2)单变量分割(Split Based on One Variable):每次最优划分都是针对单个变量。(3)剪枝策略:CART算法的关键点,也是整个Tree-Based算法的关键步骤。剪枝过程特别重要,所以在最优决策树生成过程中占有重要地位。有研究表明,剪枝过程的重要性要比树生成过程更为重要,对于不同的划分标准生成的最大树(Maximum Tree),在剪枝之后都能够保留最重要的属性划分,差别不大。反而是剪枝方法对于最优树的生成更为关键。
当数据拥有众多特征并且特征之间关系十分复杂时,构建全局模型的想法就显得太难了,也略显笨拙。而且,实际生活中很多问题都是非线性的,不可能使用全局线性模型来拟合任何数据。一种可行的方法是将数据集切分成很多份易建模的数据,然后利用线性回归技术来建模。如果首次切分后仍然难以拟合线性模型就继续切分。在这种切分方式下,树结构和回归法就相当有用。
创建回归树时,观察值取值是连续的、没有分类标签,只有根据观察数据得出的值来创建一个预测的规则。在这种情况下,Classification Tree的最优划分规则就无能为力,CART则使用最小剩余方差(Squared Residuals Minimization)来决定Regression Tree的最优划分,该划分准则是期望划分之后的子树误差方差最小。创建模型树,每个叶子节点则是一个机器学习模型,如线性回归模型。
回归树与分类树的思路类似,但叶节点的数据类型不是离散型,而是连续型,对CART稍作修改就可以处理回归问题。CART算法用于回归时根据叶子是具体值还是另外的机器学习模型又可以分为回归树和模型树。但无论是回归树还是模型树,其适用场景都是:标签值是连续分布的,但又是可以划分群落的,群落之间是有比较鲜明的区别的,即每个群落内部是相似的连续分布,群落之间分布确是不同的。所以回归树和模型树既算回归,也称得上分类。
回归是为了处理预测值是连续分布的情景,其返回值应该是一个具体预测值。回归树的叶子是一个个具体的值,从预测值连续这个意义上严格来说,回归树不能称之为“回归算法”。因为回归树返回的是“一团”数据的均值,而不是具体的、连续的预测值(即训练数据的标签值虽然是连续的,但回归树的预测值却只能是离散的)。所以回归树其实也可以算为“分类”算法,其适用场景要具备“物以类聚”的特点,即特征值的组合会使标签属于某一个“群落”,群落之间会有相对鲜明的“鸿沟”。如人的风格是一个连续分布,但是却又能“群分”成文艺、普通和2B三个群落,利用回归树可以判断一个人是文艺还是2B,但却不能度量其有多文艺或者多2B。所以,利用回归树可以将复杂的训练数据划分成一个个相对简单的群落,群落上可以再利用别的机器学习模型再学习。
模型树的叶子是一个个机器学习模型,如线性回归模型,所以更称的上是“回归”算法。利用模型树就可以度量一个人的文艺值了。回归树和模型树也需要剪枝,剪枝理论和分类树相同。为了获得最佳模型,树剪枝常采用预剪枝和后剪枝结合的方法进行。
树回归中,为成功构建以分段常数为叶节点的树,需要度量出数据的一致性。分类决策树创建时会在给定节点时计算分类数据的混乱度。那么如何计算连续型数值的混乱度呢? 事实上, 在连续数据集上计算混乱度是非常简单的–度量按某一特征划分前后标签数据总差值,每次选取使数据总差值最小的那个特征做最佳分支特征为了对正负差值同等看待,一般使用绝对值或平方值来代替上述差值)。为什么选择计算差值呢》差值越小,相似度越高,越可能属于一个群落咯。那么如果选取方差做差值,总方差的计算方法有两种:(1)计算数据集均值std,计算每个数据点与std的方差,然后n个点求和。(2)计算数据集方差var,然后var_sum = var*n,n为数据集数据数目。Python Matrix中可以利用var方法求得数据集方差,因此该方法简单、方便。
与Gini Gain对离散特征和连续特征的处理方法类似,多值离散特征需要选择最优二分序列,连续特征则要找出最优分裂点。那么,每次最佳分支特征的选取过程为:function chooseBestSplitFeature()(1)先令最佳方差为无限大bestVar=inf。(2)依次计算根据某特征(FeatureCount次迭代)划分数据后的总方差currentVar(,计算方法为:划分后左右子数据集的总方差之和),如果currentVar
7)CART分类
当将CART用于分类问题时需要构建CART分类树。
创建分类树递归过程中,CART每次都选择当前数据集中具有最小Gini信息增益的特征作为结点划分决策树。ID3算法和C4.5算法虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支、规模较大,CART算法的二分法可以简化决策树的规模,提高生成决策树的效率。对于连续特征,CART也是采取和C4.5同样的方法处理。为了避免过拟合(Overfitting),CART决策树需要剪枝。预测过程当然也就十分简单,根据产生的决策树模型,延伸匹配特征值到最后的叶子节点即得到预测的类别。
CART与C4.5的不同之处是节点分裂建立在GINI指数这个概念上,GINI指数主要是度量数据划分或训练数据集的不纯度为主。GINI值越小,表明样本的纯净度越高(即该样本只属于同一类的概率越高)。衡量出数据集某个特征所有取值的Gini指数后,就可以得到该特征的Gini Split info,也就是GiniGain。不考虑剪枝情况下,分类决策树递归创建过程中就是每次选择GiniGain最小的节点做分叉点,直至子数据集都属于同一类或者所有特征用光了。
因为CART二分的特性,当训练数据具有两个以上的类别,CART需考虑将目标类别合并成两个超类别,这个过程称为双化。GINI指数是一种不等性度量,通常用来度量收入不平衡,可以用来度量任何不均匀分布,是介于0~1之间的数,0-完全相等,1-完全不相等。分类度量时,总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)。对于一个数据集T,其Gini计算方式为:

分析分类回归树的递归建树过程,不难发现它实质上存在着一个数据过度拟合问题。在决策树构造时,由于训练数据中的噪音或孤立点,许多分枝反映的是训练数据中的异常,使用这样的判定树对类别未知的数据进行分类,分类的准确性不高。因此试图检测和减去这样的分支,检测和减去这些分支的过程被称为树剪枝。树剪枝方法用于处理过分适应数据问题。通常,这种方法使用统计度量,减去最不可靠的分支,这将导致较快的分类,提高树独立于训练数据正确分类的能力。决策树常用的剪枝常用的简直方法有两种:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。预剪枝是根据一些原则及早的停止树增长,如树的深度达到用户所要的深度、节点中样本个数少于用户指定个数、不纯度指标下降的最大幅度小于用户指定的幅度等;后剪枝则是通过在完全生长的树上剪去分枝实现的,通过删除节点的分支来剪去树节点,可以使用的后剪枝方法有多种,比如:代价复杂性剪枝、最小误差剪枝、悲观误差剪枝等等。CART常采用事后剪枝方法,构建决策树过程中的第二个关键就是用独立的验证数据集对训练集生长的树进行剪枝。