《深度学习之pytorch实战计算机视觉》第9章 多模型融合(代码可跑通)
上一章《深度学习之pytorch实战计算机视觉》第8章 图像风格迁移实战(代码可跑通)讲了图像风格迁移实战,是个很有趣的应用。多模型融合是一种“集百家之所长”的方法。在使用单一的模型处理某个问题时,我们很容易遇到模型泛化瓶颈,模型的泛化能力因为一些客观因素受到了限制;另外,在建立好一个模型后,这个模型可能在解决某个问题的能力上表现比较出色,在解决其他问题时效果却不尽如人意。所以人们开始通过一些科学的方法对优秀的模型进行融合以突破单个模型对未知问题的泛化能力的瓶颈,综合各个模型的优点得到最优解决方法,这就是多模型融合。多模型融合的宗旨就是通过科学的方法融合各个模型的优势,以获得对未知问题的更强的解决能力。
9.1 多模型融合入门
我们先来看看在使用多模型融合方法融合神经网络模型的过程中会遇到哪些问题。
(1)首先,在使用融合神经网络模型的过程中遇到的第1个问题就是训练复杂神经网络非常耗时,因为优秀的模型一般都是深度神经网络模型,这些网络模型的特点是层次较深、参数较多,所以对融合了多个深度神经网络的模型进行训练,会比我们使用单一的深度神经网络模型进行参数训练所耗费的时间要多上好几倍。
对于这种情况,我们一般使用两种方法进行解决:挑选一些结构比较简单、网络层次较少的神经网络参与到多模型融合中;如果还想继续使用深度神经网络模型进行多模型融合,就需要使用迁移学习方法来辅助模型的融合,以减少训练耗时。
(2)其次,在对各个模型进行融合时,在融合方法的类型选择上也不简单,因为在选择不同的模型融合方法解决某些问题时其结果的表现不同,而且选择是针对模型的过程进行融合,还是仅针对各个模型输出的结果进行融合,这都是值得我们思考的。
结果融合法是针对各个模型的输出结果进行融合,主要包括结果多数表决、结果直接平均和结果加权平均这三种主要的类型。在结果融合法中有一个比较通用的理论,就是若我们想通过多模型融合来提高输出结果的预测准确率,则各个模型的相关度越低,融合的效果会更好,即各个模型的输出结果的差异性越高,多模型融合的效果就会越好。
9.1.1 结果多数表决
这个方法类似于生活中的多人投票表决,服从多数人的决定。需要注意的是:最后保证我们融合的模型个数为基数,偶数极有可能发现无法对的情况。
下面看一个例子。假设我们现在已经有三个优化好的模型,而且它们能够独立完成对新输入数据的预测,现在向这三个模型分别输入10个同样的新数据,然后统计模型的预测结果。如果模型预测的结果和真实的结果一样,那么将层次预测结果记录为True,反之记录为False。
模型的最终预测结果如表 9-1 所示。


可以看出,这三个模型的预测准确率分别是80%、80%和60%,现在我们使用结果多数表决法对统计得到的结果进行融合。以三个模型中的第1个新数据的预测结果为例,模型一对新数据的预测结果为True,模型二为False,模型三为True,通过多数表决得到的融合模型对新数据的预测结果为True,其他新数据的预测结果以此类推,最后得到多模型的预测结果如下:

通过统计结果的准确率可以发现,使用多模型融合后的预测准确率也是80%,虽然在准确率的表现上比最差的模型三要好,但是和模型一和模型二的准确率处于同一水平,没有体现出模型融合的优势,所以这需要注意:进行多模型融合并不一定能取得理想的效果,需要使用不同的方法不断地尝试。下面对之前的实例稍微进行改变,如下:

调整之后的模型预测准确率不变,再计算一次多模型融合的预测结果,如下表所示:

这时多模型融合的预测结果对10个新数据的预测准确率已经提升到了90%,在预测结果的准确率上超过了被融合的三个模型中的任意一个。为什么预测结果最后会发生这样的改变?这是因为我们扩大了模型三在预测结果上和模型一及模型二的差异性,这也印证了之前提的通用理论:参与融合的各个模型在输出结果的表现上差异性越高,最终的融合模型的预测结果越好。
9.1.2 结果直接平均
结果直接平均追求的是融合各个模型的平均预测水平,以提升模型整体的预测能力,但是与结果多数表决相比,结果直接平均不强调个别模型的突出优势,却可以弥补个别模型的明显劣势,比如参与融合的模型中有一个模型过拟合,另一个模型欠拟合,但是通过结果直接平均的方法能够很好地综合这两个模型的劣势,最后可预防融合模型过拟合和欠拟合的发生,如下:
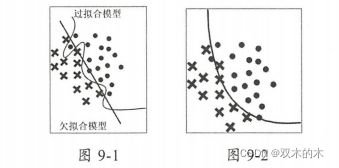
假设在图9-1中两个模型处理的是同一个分类问题,圆圈和叉号是不同类别,则两个模型在泛化能力上的表现都不尽如人意,左边模型出现了严重的过拟合,右边模型出现了严重的欠拟合;再看图9-2中采用“结果直接平均”得到的融合模型在泛化能力上表现不错,受噪声值的影响不大。所以,如果我们对两个模型进行融合并且使用“结果直接平均”方法,得到的结果在一定程度上弥补了各个模型的不足,还有可能取得比两个模型更好的泛化能力。
虽然结果直接平均的方法追求的是“平均水平”,但是使用结果直接平均的多模型融合在处理很多问题时取得了优于平均水平的成绩。
下面我们来看一个使用结果直接平均进行多模型融合的实例。依旧假设我们拥有三个优化好的模型,而且它们能够独立完成对新输入数据的预测,现在向这三个模型分别输入10个新数据,然后统计模型的预测结果。不过,我们对结果的记录使用的不是“True”和“False”,而是直接记录每个模型对新数据预测的可能性值,如果预测正确的可能性值大于50%,那么在计算准确率时就把这个预测结果看作正确的,三个模型的预测结果如下表所示:
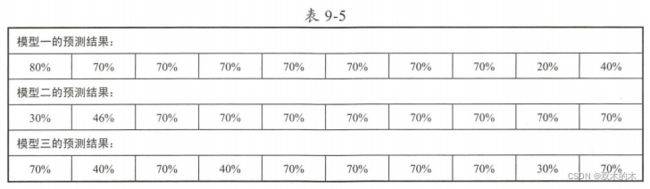
可以看出,这三个模型的预测结果的准确率分别是80%、80%和 60%,现在使用模型融合方法对这三个模型的输出结果进行直接平均。以三个模型中的第1个预测结果为例,模型一预测结果为80%,模型二预测结果为30%,模型三预测结果为70%,直接平均得到的融合模型预测结果为60%,其他新数据的预测结果以此类推,最后得到多模型的预测结果如下表所示:

通过对结果进行简单计算,我们便可以知道使用结果直接平均方法得到的融合模型的最终预测准确率是90%,在融合模型得到的对新数据的所有预测结果中,预测可能性值低于50%的只有一个,所以结果直接平均在总体的准确率上都好于被融合的三个模型,不过我们在经仔细观察后发现,融合的模型在单个数据的预测能力上并没有完胜其他三个模型,所以这也是结果直接平均的最大不足。
9.1.3 结果加权平均
我们可以将结果加权平均看作结果直接平均的改进版本,我们新增一个权重参数,用于控制各个模型对融合模型结果的影响程度。简单来说,我们之前使用结果直接平均融合的模型可以被看作由三个使用了一样的权重参数的模型按照结果加权平均融合而成的。所以结果加权平均的关键是对权重参数的控制,通过对不同模型的权重参数的控制,可以得到不同的模型融合方法,最后影响融合模型的预测结果。
下面再来看一个实例。假设我们现在已经拥有了两个优化好的模型,不是之前的三个,而且它们能够独立预测新的输入数据,向这两个模型分别输入10个同样的新数据,然后统计模型的预测结果,并直接记录模型对数据预测的可能性值,同样,如果预测正确的可能性值大于50%,那么在计算准确率时把这个预测结果看作正确的,两个模型的预测结果如下表所示。
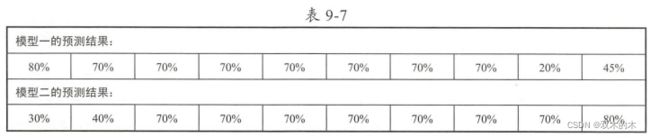
可以看出,这两个模型的预测结果的准确率均是80%,如果要对两个模型进行结果加权平均,那么首先需要设定各个模型的权重参数。假设模型一的权重值是0.8,模型二的权重值是0.2。我们首先看到模型一对第1个新数据的预测结果为80%,模型二为30%,通过结果加权平均得到的融合模型对新数据的预测结果为70%,计算方法如下:70% = 0.8x80% + 0.2x30%。
其他新数据的预测结果以此类推,最后得到多模型的预测结果如下表:

通过简单计算,我们知道使用结果加权平均融合的模型的预测准确率是90%,表9-8中预测可能性值低于50%的预测结果只有一个,融合的模型在预测结果准确率的表现上优于被融合的两个模型,而且融合模型对新数据的单个预测值也不低。下面再做一个实验,把模型一的权重值和模型二的权重值进行对调,即模型一的权重值变成了0.2,模型二的权重值变成了0.8,那么我们融合的模型的预测结果如下表所示:

这次结果的准确率降低到了80%,而且融合模型对新数据的单个预测值明显下降,可见调节各个模型的权重参数对最后的融合模型的结果影响较大。所以在使用权重平均的过程中,我们需要不断尝试使用不同的权重值组合,以达到多模型融合的最优解决方案。
9.2 PyTorch之多模型融合实战
下面基于PyTorch来实现一个多模型的融合,使用结果加权平均法,其基本思路是首先构建两个卷积神经网络模型,然后使用我们的训练数据集分别对这两个模型进行训练和对参数进行优化,使用优化后的模型对验证集进行预测,并将各模型的预测结果进行加权平均以作为最后的输出结果,通过对输出结果和真实结果的对比,来完成对融合模型准确率的计算。这里,在训练和优化模型的数据集及验证数据集时依然使用了在第7章中划分好的猫狗数据集。
使用VGG16架构和ResNet50架构的卷积神经网络模型参与本次模型的融合,然后按照结果加权平均法分别对这两个模型提前拟定好会使用到的权重值,对VGG16模型预测结果给予权重值0.6,对ResNet50的预测结果给予权重0.4。考虑到从头开始搭建、训练和优化需要大量时间,所以使用迁移学习。由于很多步骤都和之前迁移学习相似,代码也类似。因此,直接附上完整链接(可跑通)。
实现多模型融合的完整代码如下:
import torch
import torchvision
from torchvision import datasets, models, transforms
import os
from torch.autograd import Variable
import matplotlib.pyplot as plt
import time
#----------------------------------1数据导入
data_dir = 'DogsVSCats'
data_transform = {x:transforms.Compose([transforms.Scale([224,224]),
transforms.ToTensor(),
transforms.Normalize(mean = [0.5,0.5,0.5],std = [0.5,0.5,0.5])])
for x in ["train","valid"]}
image_datasets = {x:datasets.ImageFolder(root = os.path.join(data_dir,x),
transform = data_transform[x])
for x in ["train","valid"]}
dataloader = {x:torch.utils.data.DataLoader(dataset = image_datasets[x],
batch_size = 16,
shuffle = True)
for x in ["train","valid"]}
# X_example, y_example = next(iter(dataloader['train']))
index_classes = image_datasets["train"].class_to_idx#{'cat': 0, 'dog': 1}
example_classes = image_datasets["train"].classes#['cat', 'dog']
#---------------------------------2搭建模型,使用迁移学习
model_1 = models.vgg16(pretrained=False)
model_2 = models.resnet50(pretrained=False)
Use_gpu = torch.cuda.is_available()
#相应的模型调整
for parma in model_1.parameters():
parma.requires_grad = False
model_1.classifier = torch.nn.Sequential(torch.nn.Linear(25088, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 2))
for parma in model_2.parameters():
parma.requires_grad = False
model_2.fc = torch.nn.Linear(2048, 2)
if Use_gpu:
model_1 = model_1.cuda()
model_2 = model_2.cuda()
#---------------------------------3分别构造损失函数和优化器
loss_f_1 = torch.nn.CrossEntropyLoss()
loss_f_2 = torch.nn.CrossEntropyLoss()
optimizer_1 = torch.optim.Adam(model_1.classifier.parameters(), lr=0.00001)
optimizer_2 = torch.optim.Adam(model_2.fc.parameters(), lr=0.00001)
weight_1 = 0.6
weight_2 = 0.4
#---------------------------------4.模型训练
epoch_n = 5
time_open = time.time()
for epoch in range(epoch_n):
print('Epoch {}/{}'.format(epoch, epoch_n - 1))
print('-' * 10)
for phase in ['train', 'valid']:
if phase == 'train':
print('Training......')
model_1.train(True)
model_2.train(True)
else:
print('Validing......')
model_1.train(False)
model_2.train(False)
running_loss_1 = 0.0
running_corrects_1 = 0
running_loss_2 = 0.0
running_corrects_2 = 0
blending_running_corrects = 0
for batch, data in enumerate(dataloader[phase], 1):
X, y = data
if Use_gpu:
X, y = Variable(X.cuda()), Variable(y.cuda())
else:
X, y = Variable(X), Variable(y)
y_pred_1 = model_1(X)
y_pred_2 = model_2(X)
blending_y_pred = y_pred_1 * weight_1 + y_pred_2 * weight_2
_, pred_1 = torch.max(y_pred_1.data, 1)
_, pred_2 = torch.max(y_pred_2.data, 1)
#融合模型
_, blending_pred = torch.max(blending_y_pred.data, 1)
optimizer_1.zero_grad()
optimizer_2.zero_grad()
loss_1 = loss_f_1(y_pred_1, y)
loss_2 = loss_f_2(y_pred_2, y)
if phase == 'train':
loss_1.backward()
loss_2.backward()
optimizer_1.step()
optimizer_2.step()
running_loss_1 += loss_1.item() #data[0]
running_corrects_1 += torch.sum(pred_1 == y.data)
running_loss_2 += loss_2.item()
running_corrects_2 += torch.sum(pred_2 == y.data)
blending_running_corrects += torch.sum(blending_pred == y.data)
if batch % 500 == 0 and phase == 'train':
print('Batch {},Model1 Train Loss:{:.4f},Model1 \
Train ACC:{:.4f},Model2 \
Train Loss:{:.4f},Model2 Train ACC:{:.4f},\
Blending_Model ACC:{:.4f}'.format(batch, running_loss_1 / batch, 100 * running_corrects_1 / (16 * batch),
running_loss_2 / batch, 100 * running_corrects_2 / (16 * batch),
100 * blending_running_corrects / (16 * batch)))
epoch_loss_1 = running_loss_1 * 16 / len(image_datasets[phase])
epoch_acc_1 = 100 * running_corrects_1.cpu().numpy() / len(image_datasets[phase])
epoch_loss_2 = running_loss_2 * 16 / len(image_datasets[phase])
epoch_acc_2 = 100 * running_corrects_2.cpu().numpy() / len(image_datasets[phase])
epoch_blending_acc = 100 * blending_running_corrects.cpu().numpy() / len(image_datasets[phase])
print('Epoch,Model1 Loss:{:.4f},Model1 ACC:{:.4f},Model2 Loss:{:.4f},Model2 ACC:{:.4f},Blending_Model ACC:{:.4f}'.format(
epoch_loss_1,epoch_acc_1,epoch_loss_2,epoch_acc_2,epoch_blending_acc))
time_end = time.time() - time_open
print(time_end)输出结果如下:
Epoch 0/4
----------
Training......
Epoch,Model1 Loss:0.7221,Model1 ACC:45.5000,Model2 Loss:0.7594,Model2 ACC:50.0000,Blending_Model ACC:50.0000
Validing......
Epoch,Model1 Loss:0.8887,Model1 ACC:50.0000,Model2 Loss:0.8838,Model2 ACC:52.0000,Blending_Model ACC:54.0000
Epoch 1/4
----------
Training......
Epoch,Model1 Loss:0.7186,Model1 ACC:54.0000,Model2 Loss:0.7198,Model2 ACC:54.5000,Blending_Model ACC:56.0000
Validing......
Epoch,Model1 Loss:0.8900,Model1 ACC:48.0000,Model2 Loss:0.8552,Model2 ACC:50.0000,Blending_Model ACC:50.0000
Epoch 2/4
----------
Training......
Epoch,Model1 Loss:0.7201,Model1 ACC:49.5000,Model2 Loss:0.7034,Model2 ACC:56.0000,Blending_Model ACC:59.0000
Validing......
Epoch,Model1 Loss:0.8906,Model1 ACC:46.0000,Model2 Loss:0.8938,Model2 ACC:50.0000,Blending_Model ACC:50.0000
Epoch 3/4
----------
Training......
Epoch,Model1 Loss:0.7190,Model1 ACC:51.0000,Model2 Loss:0.7040,Model2 ACC:60.5000,Blending_Model ACC:61.0000
Validing......
Epoch,Model1 Loss:0.8765,Model1 ACC:50.0000,Model2 Loss:0.9241,Model2 ACC:48.0000,Blending_Model ACC:46.0000
Epoch 4/4
----------
Training......
Epoch,Model1 Loss:0.7202,Model1 ACC:50.5000,Model2 Loss:0.7020,Model2 ACC:60.5000,Blending_Model ACC:57.0000
Validing......
Epoch,Model1 Loss:0.8958,Model1 ACC:50.0000,Model2 Loss:0.8771,Model2 ACC:54.0000,Blending_Model ACC:54.0000
8.5479576587677在输出结果中,Model1代表VGG16模型的输出结果,Model2代表ResNet50模型的输出结果,Blending_Model代表融合模型的输出结果。我们从输出结果的准确率发现,通过结果加权平均得到的融合模型在预测结果的准确率上优于VGG16和ResNet50这两个模型,所以我们进行多模型融合的方法是成功的。(【说明】由于我只使用了部分训练数据集和迭代次数只有5次,模型的准确率还是有优化空间的。)
9.3 小结
多模型融合的方法非常受大众喜爱,比如在Kaggle比赛中就经常会用到各种各样的多模型融合实例。其实多模型融合的内容不仅仅局限于本章所介绍的内容,因为本章讲到的只是用于模型输出结果的融合方法,而且这些方法还在不断创新,所以我们最主要的还是要发挥自己的想象力和创造力,这样才有可能发现更多、更优的模型融合方法。
说明:记录学习笔记,如果错误欢迎指正!写文章不易,转载请联系我。