Agent评估【Langchain】
Agent评估【LangChain&LangSmith】
简介
LangChain提供了三种LLM-Agent的评估方案
- 最终响应:评估代理的最终响应
- 单步:单独评估任何代理步骤(例如,是否选择了适当的工具)
- 轨迹:评估代理是否采用了预期路径(例如,工具调用)来得出最终答案
构建智能体
接下来将使用LangGraph构建一个Agent
环境设置
- 下载依赖项
pip install --upgrade --quiet langchain langsmith langchain-community langchain-experimental langgraph
- 配置langsmith跟踪【轨迹评估所必须要的条件】
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" # Update appropriately for self-hosted installations or the EU region
_set_env("LANGCHAIN_API_KEY")
配置数据库
在本教程中,我们将创建一个SQLite数据库。SQLite是一个轻量级的数据库,易于设置和使用。我们将加载chinook数据库,这是一个代表数字媒体商店的示例数据库。您可以在此处找到有关该数据库的更多信息。
为了方便起见,我们已将数据库(Chinook.db)托管在公共GCS存储桶上。
import requests
url = "https://storage.googleapis.com/benchmarks-artifacts/chinook/Chinook.db"
response = requests.get(url)
if response.status_code == 200:
# Open a local file in binary write mode
with open("Chinook.db", "wb") as file:
# Write the content of the response (the file) to the local file
file.write(response.content)
print("File downloaded and saved as Chinook.db")
else:
print(f"Failed to download the file. Status code: {response.status_code}")
我们将使用langchain_community包中提供的便捷SQL数据库包装器来与数据库进行交互。该包装器提供了一个简单的界面来执行SQL查询并获取结果。在本教程的后面部分,我们还将使用langchain_openai包来与OpenAI API进行交互,以便使用语言模型。
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
SQL Agent
使用LangGraph创建SQL Agent
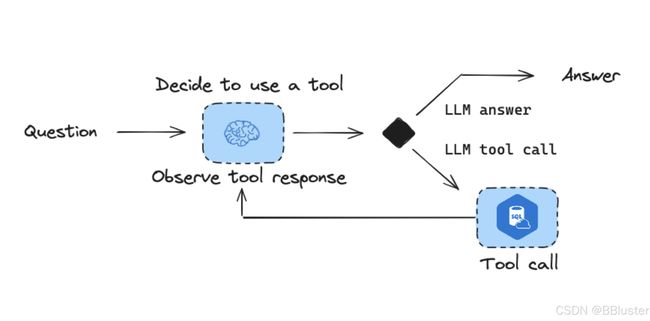
LLM
调用LLM,这里可以选择自己的LLM
from langchain_openai import ChatOpenAI
llm=ChatOpenAI(model="gpt-4o",temperature=0)
experiment_prefix="sql-agent-gpt4o"
metadata = "Chinook, gpt-4o base-case-agent"
Tool
我们将使用SQL工具包以及一些自定义工具来在执行查询之前对其进行检查,并从数据库中检查查询结果,以确认其不为空或与问题无关。
import json
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.graph import END, MessageGraph
from langgraph.prebuilt.tool_node import ToolNode
from langchain_core.messages import AIMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain.agents import tool
# SQL toolkit
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
tools = toolkit.get_tools()
# Query checking
query_check_system = """You are a SQL expert with a strong attention to detail.
Double check the SQLite query for common mistakes, including:
- Using NOT IN with NULL values
- Using UNION when UNION ALL should have been used
- Using BETWEEN for exclusive ranges
- Data type mismatch in predicates
- Properly quoting identifiers
- Using the correct number of arguments for functions
- Casting to the correct data type
- Using the proper columns for joins
If there are any of the above mistakes, rewrite the query. If there are no mistakes, just reproduce the original query.
Execute the correct query with the appropriate tool."""
query_check_prompt = ChatPromptTemplate.from_messages([("system", query_check_system),("user", "{query}")])
query_check = query_check_prompt | llm
@tool
def check_query_tool(query: str) -> str:
"""
Use this tool to double check if your query is correct before executing it.
"""
return query_check.invoke({"query": query}).content
# Query result checking
query_result_check_system = """You are grading the result of a SQL query from a DB.
- Check that the result is not empty.
- If it is empty, instruct the system to re-try!"""
query_result_check_prompt = ChatPromptTemplate.from_messages([("system", query_result_check_system),("user", "{query_result}")])
query_result_check = query_result_check_prompt | llm
@tool
def check_result(query_result: str) -> str:
"""
Use this tool to check the query result from the database to confirm it is not empty and is relevant.
"""
return query_result_check.invoke({"query_result": query_result}).content
tools.append(check_query_tool)
tools.append(check_result)
State
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import AnyMessage, add_messages
class State(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
SQL Assistant
from langchain_core.runnables import Runnable, RunnableConfig
# Assistant
class Assistant:
def __init__(self, runnable: Runnable):
self.runnable = runnable
def __call__(self, state: State, config: RunnableConfig):
while True:
# Append to state
state = {**state}
# Invoke the tool-calling LLM
result = self.runnable.invoke(state)
# If it is a tool call -> response is valid
# If it has meaningful text -> response is valid
# Otherwise, we re-prompt it b/c response is not meaningful
if not result.tool_calls and (
not result.content
or isinstance(result.content, list)
and not result.content[0].get("text")
):
messages = state["messages"] + [("user", "Respond with a real output.")]
state = {**state, "messages": messages}
else:
break
return {"messages": result}
# Assistant runnable
query_gen_system = """
ROLE:
You are an agent designed to interact with a SQL database. You have access to tools for interacting with the database.
GOAL:
Given an input question, create a syntactically correct SQLite query to run, then look at the results of the query and return the answer.
INSTRUCTIONS:
- Only use the below tools for the following operations.
- Only use the information returned by the below tools to construct your final answer.
- To start you should ALWAYS look at the tables in the database to see what you can query. Do NOT skip this step.
- Then you should query the schema of the most relevant tables.
- Write your query based upon the schema of the tables. You MUST double check your query before executing it.
- Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 5 results.
- You can order the results by a relevant column to return the most interesting examples in the database.
- Never query for all the columns from a specific table, only ask for the relevant columns given the question.
- If you get an error while executing a query, rewrite the query and try again.
- If the query returns a result, use check_result tool to check the query result.
- If the query result result is empty, think about the table schema, rewrite the query, and try again.
- DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database."""
query_gen_prompt = ChatPromptTemplate.from_messages([("system", query_gen_system),("placeholder", "{messages}")])
assistant_runnable = query_gen_prompt | llm.bind_tools(tools)
Graph Utilities
我们将定义一些实用函数来帮助我们实现智能体。具体来说,我们将为ToolNode添加一个后备机制来处理错误,并将这些错误反馈给智能体。
from langchain_core.messages import ToolMessage
from langchain_core.runnables import RunnableLambda
def create_tool_node_with_fallback(tools: list) -> dict:
return ToolNode(tools).with_fallbacks(
[RunnableLambda(handle_tool_error)], exception_key="error"
)
def _print_event(event: dict, _printed: set, max_length=1500):
current_state = event.get("dialog_state")
if current_state:
print(f"Currently in: ", current_state[-1])
message = event.get("messages")
if message:
if isinstance(message, list):
message = message[-1]
if message.id not in _printed:
msg_repr = message.pretty_repr(html=True)
if len(msg_repr) > max_length:
msg_repr = msg_repr[:max_length] + " ... (truncated)"
print(msg_repr)
_printed.add(message.id)
def handle_tool_error(state) -> dict:
error = state.get("error")
tool_calls = state["messages"][-1].tool_calls
return {
"messages": [
ToolMessage(
content=f"Error: {repr(error)}\n please fix your mistakes.",
tool_call_id=tc["id"],
)
for tc in tool_calls
]
}
Graph
基于Graph设计工作流Agent
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.graph import END, StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
# Graph
builder = StateGraph(State)
# Define nodes: these do the work
builder.add_node("assistant", Assistant(assistant_runnable))
builder.add_node("tools", create_tool_node_with_fallback(tools))
# Define edges: these determine how the control flow moves
builder.set_entry_point("assistant")
builder.add_conditional_edges(
"assistant",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
# "tools" calls one of our tools. END causes the graph to terminate (and respond to the user)
{"tools": "tools", END: END},
)
builder.add_edge("tools", "assistant")
# The checkpointer lets the graph persist its state
memory = SqliteSaver.from_conn_string(":memory:")
graph = builder.compile(checkpointer=memory)
运行Agent
questions = ["Which country's customers spent the most? And how much did they spend?",
"How many albums does the artist Led Zeppelin have?",
"What was the most purchased track of 2017?",
"Which sales agent made the most in sales in 2009?"]
## Invoke
import uuid
_printed = set()
thread_id = str(uuid.uuid4())
config = {
"configurable": {
# Checkpoints are accessed by thread_id
"thread_id": thread_id,
}
}
msg = {"messages": ("user", questions[0])}
messages = graph.invoke(msg,config)
messages['messages'][-1].content
## Stream
_printed = set()
thread_id = str(uuid.uuid4())
config = {
"configurable": {
# Checkpoints are accessed by thread_id
"thread_id": thread_id,
}
}
events = graph.stream(
{"messages": ("user", questions[0])}, config, stream_mode="values"
)
for event in events:
_print_event(event, _printed)
评估
智能体评估可以至少关注3个方面:
- 响应:输入是一个提示和一个可选的工具列表。输出是智能体的最终响应。
- 单步:与之前一样,输入是一个提示和一个可选的工具列表。输出是工具调用。
- 轨迹:与之前一样,输入是一个提示和一个可选的工具列表。输出是工具调用的列表。
响应评估
我们可以评估智能体在任务中的整体表现。这基本上涉及将智能体视为一个黑盒子,并仅评估其是否完成了任务。
首先,创建一个评估智能体端到端性能的数据集。我们可以从这里获取一些与Chinook数据库相关的问题。【响应评估在严格意义上其实与LLM的评估方案类似,即使用数据集进行端到端的输出输入评估】
此评估的重点
- 数据集需要尽量基于Agent所部署的环境,例医疗方面的Agent即需要医疗方面的数据集进行测试
- Agent的评估结果效果基于数据集的质量,总体上来说数据集数量越多,评估效果的右离群点引起的变异性越低
from langsmith import Client
client = Client()
# Create a dataset
examples = [
("Which country's customers spent the most? And how much did they spend?", "The country whose customers spent the most is the USA, with a total expenditure of $523.06"),
("What was the most purchased track of 2013?", "The most purchased track of 2013 was Hot Girl."),
("How many albums does the artist Led Zeppelin have?","Led Zeppelin has 14 albums"),
("What is the total price for the album “Big Ones”?","The total price for the album 'Big Ones' is 14.85"),
("Which sales agent made the most in sales in 2009?", "Steve Johnson made the most sales in 2009"),
]
dataset_name = "SQL Agent Response"
if not client.has_dataset(dataset_name=dataset_name):
dataset = client.create_dataset(dataset_name=dataset_name)
inputs, outputs = zip(
*[({"input": text}, {"output": label}) for text, label in examples]
)
client.create_examples(inputs=inputs, outputs=outputs, dataset_id=dataset.id)
运行链路
def predict_sql_agent_answer(example: dict):
"""Use this for answer evaluation"""
msg = {"messages": ("user", example["input"])}
messages = graph.invoke(msg, config)
return {"response": messages['messages'][-1].content}
评估
这可以遵循我们在RAG中所做的,将生成的答案与参考答案进行比较。
from langchain import hub
from langchain_openai import ChatOpenAI
# Grade prompt
grade_prompt_answer_accuracy = prompt = hub.pull("langchain-ai/rag-answer-vs-reference")
def answer_evaluator(run, example) -> dict:
"""
A simple evaluator for RAG answer accuracy
"""
# Get question, ground truth answer, RAG chain answer
input_question = example.inputs["input"]
reference = example.outputs["output"]
prediction = run.outputs["response"]
# LLM grader
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
# Structured prompt
answer_grader = grade_prompt_answer_accuracy | llm
# Run evaluator
score = answer_grader.invoke({"question": input_question,
"correct_answer": reference,
"student_answer": prediction})
score = score["Score"]
return {"key": "answer_v_reference_score", "score": score}
from langsmith.evaluation import evaluate
experiment_results = evaluate(
predict_sql_agent_answer,
data=dataset_name,
evaluators=[answer_evaluator],
experiment_prefix=experiment_prefix + "-response-v-reference",
num_repetitions=3,
metadata={"version": metadata},
)
单步评估
代理通常会执行多个动作。虽然对它们进行端到端的评估很有用,但对单个动作进行评估也同样有用。这通常涉及到评估代理的单个步骤——即它决定做什么的LLM调用。
我们可以使用自定义评估器来检查特定的工具调用:
- 在这里,我们只需通过提示调用助手assistant_runnable,并检查生成的工具调用是否符合预期。
- 在这里,我们使用了一个专门的代理,其中工具是硬编码的(而不是与数据集输入一起传递的)。
- 我们为正在评估的步骤指定了参考工具调用,即expected_tool_call。
from langsmith.schemas import Example, Run
def predict_assistant(example: dict):
"""Invoke assistant for single tool call evaluation"""
msg = [ ("user", example["input"]) ]
result = assistant_runnable.invoke({"messages":msg})
return {"response": result}
def check_specific_tool_call(root_run: Run, example: Example) -> dict:
"""
Check if the first tool call in the response matches the expected tool call.
"""
# Expected tool call
expected_tool_call = 'sql_db_list_tables'
# Run
response = root_run.outputs["response"]
# Get tool call
try:
tool_call = getattr(response, 'tool_calls', [])[0]['name']
except (IndexError, KeyError):
tool_call = None
score = 1 if tool_call == expected_tool_call else 0
return {"score": score, "key": "single_tool_call"}
experiment_results = evaluate(
predict_assistant,
data=dataset_name,
evaluators=[check_specific_tool_call],
experiment_prefix=experiment_prefix + "-single-tool",
num_repetitions=3,
metadata={"version": metadata},
)
我们可以使用自定义评估器来检查工具调用的轨迹:
- 在这里,我们只需通过提示调用代理graph.invoke。
- 在这里,我们使用了一个专门的代理,其中工具是硬编码的(而不是与数据集输入一起传递)。
- 我们使用find_tool_calls提取被调用的工具列表。 自定义函数可以以各种用户定义的方式处理这些工具调用。
- 我们可以检查是否以任意顺序调用了所有预期的工具:contains_all_tool_calls_any_order
- 我们可以检查是否按顺序调用了所有预期的工具,同时允许插入工具调用contains_all_tool_calls_in_order
- 我们可以检查是否以确切的顺序调用了所有预期的工具:contains_all_tool_calls_in_order_exact_match
def predict_sql_agent_messages(example: dict):
"""Use this for answer evaluation"""
msg = {"messages": ("user", example["input"])}
messages = graph.invoke(msg, config)
return {"response": messages}
def find_tool_calls(messages):
"""
Find all tool calls in the messages returned
"""
tool_calls = [tc['name'] for m in messages['messages'] for tc in getattr(m, 'tool_calls', [])]
return tool_calls
def contains_all_tool_calls_any_order(root_run: Run, example: Example) -> dict:
"""
Check if all expected tools are called in any order.
"""
expected = ['sql_db_list_tables', 'sql_db_schema', 'sql_db_query_checker', 'sql_db_query', 'check_result']
messages = root_run.outputs["response"]
tool_calls = find_tool_calls(messages)
# Optionally, log the tool calls -
#print("Here are my tool calls:")
#print(tool_calls)
if set(expected) <= set(tool_calls):
score = 1
else:
score = 0
return {"score": int(score), "key": "multi_tool_call_any_order"}
def contains_all_tool_calls_in_order(root_run: Run, example: Example) -> dict:
"""
Check if all expected tools are called in exact order.
"""
messages = root_run.outputs["response"]
tool_calls = find_tool_calls(messages)
# Optionally, log the tool calls -
#print("Here are my tool calls:")
#print(tool_calls)
it = iter(tool_calls)
expected = ['sql_db_list_tables', 'sql_db_schema', 'sql_db_query_checker', 'sql_db_query', 'check_result']
if all(elem in it for elem in expected):
score = 1
else:
score = 0
return {"score": int(score), "key": "multi_tool_call_in_order"}
def contains_all_tool_calls_in_order_exact_match(root_run: Run, example: Example) -> dict:
"""
Check if all expected tools are called in exact order and without any additional tool calls.
"""
expected = ['sql_db_list_tables', 'sql_db_schema', 'sql_db_query_checker', 'sql_db_query', 'check_result']
messages = root_run.outputs["response"]
tool_calls = find_tool_calls(messages)
# Optionally, log the tool calls -
#print("Here are my tool calls:")
#print(tool_calls)
if tool_calls == expected:
score = 1
else:
score = 0
return {"score": int(score), "key": "multi_tool_call_in_exact_order"}
experiment_results = evaluate(
predict_sql_agent_messages,
data=dataset_name,
evaluators=[contains_all_tool_calls_any_order,contains_all_tool_calls_in_order,contains_all_tool_calls_in_order_exact_match],
experiment_prefix=experiment_prefix + "-trajectory",
num_repetitions=3,
metadata={"version": metadata},