红外弱小目标检测:IPI算法解读及MATLAB复现
参考文献:[1] C. Gao et al., “Infrared Patch-Image Model for Small Target Detection in a Single Image,” vol. 22, no. 12, pp. 4996–5009, 2013.
本文整理论文笔记,并附MATLAB实现代码。
第一次比较正式地写论文阅读笔记,虽然目前的效率不高,但整理下来很有收获。感谢原作者的开源代码!
希望对读者们有所帮助,也欢迎大家一起讨论。
一、文献笔记
1. 核心思想
- IPI算法是单帧检测算法;
- 利用背景的非局部自相关性(non-local self-correlation of background),将目标检测转化为低秩矩阵和稀疏矩阵的优化问题。进而可利用主成分分析(stable principle component pursuit)求解;
- 该算法不仅可以检测目标,也可以预测背景。
2. 作者为什么会提出该算法?
1. 背景的变化会造成序列检测算法性能下降,因此研究基于单帧的检测算法很有必要。
文章中,作者提到对于一些背景不变(static background)的及目标在图像序列中具有连续性(consistent targets in adjacent frames),指定目标的先验知识,多帧算法的检测效果更好;但是在IRST系统中,会存在很多传感器平台在运动的应用场景,包含传感器运动(e.g. 图像传感器装在飞机上)和目标运动(e.g. 监控导弹),这些应用场景下得到的数据背景都会存在剧烈变化,且目标的运动存在不连续性(inconsisitent)。
2. 传统的弱小目标模型不一定适用于所有场景。
传统的弱小目标模型:目标成像很小,可认为是一个辐射点源,具有高斯分布特性,且各向同性的圆形,其灰度分布满足公式(1)
![]() …………………………(1)
…………………………(1)
式中,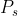 表示图像中目标的灰度峰值,
表示图像中目标的灰度峰值, 表示目标灰度在x,y方向的扩展参数,决定了目标的弥散程度,sigma越小,目标灰度分布越集中;sigma越大,目标灰度分布越弥散。
表示目标灰度在x,y方向的扩展参数,决定了目标的弥散程度,sigma越小,目标灰度分布越集中;sigma越大,目标灰度分布越弥散。
在实际的图像序列中,目标的灰度分布并不总是满足二维高斯分布,例如文章中列举了一些目标具有"flat top" shape, 如图1,且由于受成像距离、环境、目标类型的影响,目标的大小在2*2~10*10不等,目标的灰度峰值也很离散。(目标3D灰度分布图见附录1)
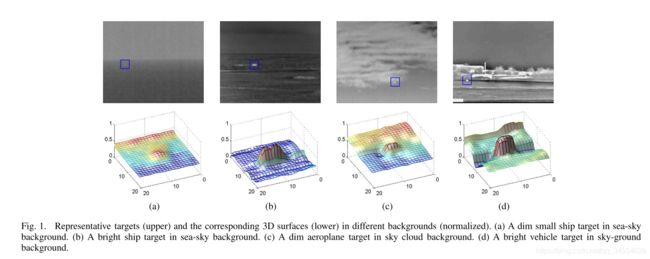
图1 弱小目标及其三维灰度分布图(摘自文献)。
3. 一些传统的目标检测算法对噪声敏感(sensitive to noise),且当目标尺寸范围较大时(size varies within a somewhat large range)检测效果不稳定(stably)。
可用公式(2)表示一幅红外图像:
![]() ……………………(2) ,
……………………(2) ,
式中,![]() 表示原始图像(original image),
表示原始图像(original image),![]() 表示目标图像(target image),
表示目标图像(target image),![]() 表示背景图像(background image),
表示背景图像(background image),![]() 表示噪声图像(noise image),
表示噪声图像(noise image), 表示像素位置。
表示像素位置。
作者指出,弱小目标检测算法的性能通常取决于对目标、背景、目标和背景的假设,假设的合理性决定了算法在应用中的鲁棒性。
一些传统的算法,如Top-hat,通过预测背景![]() ,进而抑制背景
,进而抑制背景![]() 来检测目标。这类方法的缺点即:对噪声敏感,以及空域滤波模板大小往往取决于目标尺寸这一先验知识,所以受目标尺寸的影响较大。
来检测目标。这类方法的缺点即:对噪声敏感,以及空域滤波模板大小往往取决于目标尺寸这一先验知识,所以受目标尺寸的影响较大。
本文所提算法是如何解决3条缺陷的?
基于对上述研究现状的分析,作者提出了本文的算法:
- 利用局部区域构造(local patch construction)的方法,将传统的红外图像模型推广至新的infrared patch-image,IPI 模型;(解决了问题(2))
- 基于新模型,假设目标图T为稀疏矩阵,背景图B为低秩矩阵,进而将目标检测转化为分离低秩矩阵与稀疏矩阵的优化问题;
- 算法依据:背景主要是大面积缓慢变化的低频部分,如自然背景中的云层,其在空间上往往呈大面积的连续分布状态,在红外辐射的强度上也呈渐变过渡状态,使得其在灰度空间分布上具有较大相关性,这也是为什么我们在对背景预测时需要重点考虑背景辐射强度的起伏。本文提到,即使是图像中不相邻的背景之间也存在较强的相关性,因此可以将背景图B看作低秩矩阵。
- 将目标图T看作稀疏矩阵,仅利用的目标在整幅图中所占比例小这一假设(先验知识),未对目标的尺寸、目标的灰度值做假设,因此解决了问题(3),算法更具鲁棒性。
作者阐述了其所提算法的两个优点:
- 本文模型更符合真实性,对不同的目标尺寸和目标的SCR更具鲁棒性,应用场景更广泛。本文对目标和背景做出的假设(1)相较于整幅图像,目标的尺寸很小;(2)背景具有相关性
- 即使在缺乏对背景和目标尺寸先验知识的前提下,利用当前low-rank matrix recovery技术依然可以求解,算法的实现得到了保证。
3. IPI Model 介绍
3.1 patch-image的构建
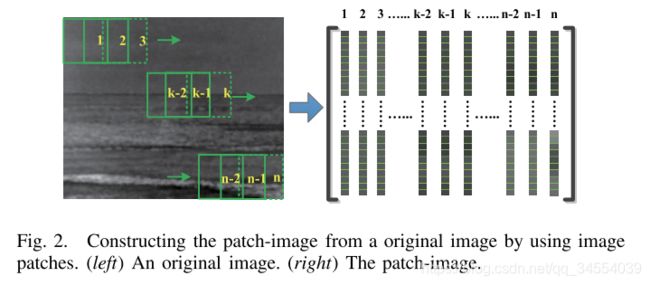
1. 指定一滑动窗口,从左上到右下依次得到每个Patch,然后将每个patch向量化为列向量,构成新的矩阵,由此得到patch-image;
2. patch-image的尺寸不仅取决于原图的大小,而且取决于滑动窗口的大小与其水平、垂直方向的滑动步长;(对一些特殊情况,(1)滑动窗口大小与原图大小相同(2)滑动窗口是与图像等高的列向量且滑动步长为1时,patch-image的大小与原图相同。
3.2 patch-image的重构
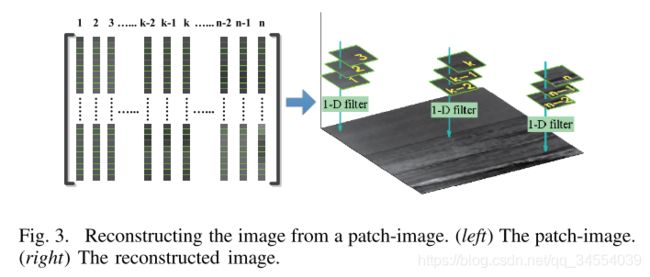
重构需要解决的问题是相邻图像块之间有重叠,对于重叠部分的像素值,可以通过求最大值、最小值、均值、中值等方式重构。
![]() .....……………………. (3) ,式中,x表示包含来自p个重叠patch的同一位置像素值的列向量,f表示max/ min/ mean/ median......
.....……………………. (3) ,式中,x表示包含来自p个重叠patch的同一位置像素值的列向量,f表示max/ min/ mean/ median......
3.3 Infrared Patch-Image Model
使用patch-imge构造方法,传统的红外图像模型(公式(2))可以构造为Infrared Patch-Image模型,使用公式(4)表示。
![]() …………………………………… (4)
…………………………………… (4)
传统的红外图像模型可以看作:滑动窗口是与图像等高的列向量且滑动步长为1时得到的。
4. 基于IPI Model 的目标检测
4.1 Target Patch-Image T
1. 什么是稀疏矩阵?
在矩阵中,若数值为0的元素数目远多于非0元素的数目,则该矩阵称为稀疏矩阵。反之,称为稠密矩阵。
[摘自:百度百科https://baike.baidu.com/item/%E7%A8%80%E7%96%8F%E7%9F%A9%E9%98%B5]
2. 将目标图像T看作稀疏矩阵
尽管在实际拍摄的视频中,弱小目标的灰度、尺寸均在变化,但是对于整幅图来说,其所占比例仍然很小,因此可以将目标图像看作稀疏矩阵,见公式(5)。
![]() ……………………………………(5)
……………………………………(5)
式中,![]() 表示0-范数,代表了矩阵中非0元素的数量;k 的值取决于图像中目标的尺寸与数量,且
表示0-范数,代表了矩阵中非0元素的数量;k 的值取决于图像中目标的尺寸与数量,且![]() ,其中
,其中 ![]()
文献中,只对目标的“稀疏性”做了假设,即算法只对目标“小”这一特性做了量化。
4.2 Background Patch-Image B
上述提到,红外图像的背景具有相关性,即使像素位置相隔较远的两局部区域也具有相关性,可称为非局部自相关性(non-local self-correlation)。
基于这一特性,作者将背景图看作低秩矩阵,见公式(6)。
![]() …………………………………… (6)
…………………………………… (6)
式中, 为常数。本质上, 代表了背景的复杂程度,背景越复杂,的值越大,反之,背景越均匀,的值越小。
为常数。本质上, 代表了背景的复杂程度,背景越复杂,的值越大,反之,背景越均匀,的值越小。
此外,文中提到,图像中除non-local self-correlation特性外,还存在non-local self-similarity这一特性,很多纹理合成、图像复原和图像去噪的算法都是基于图像的non-local特性。
并且,有相关论文指出所有的背景图像块都来自低秩子空间的混合(a mixture of low-rank subspace clusters while not only one),当小目标位于高度非均匀背景下,使用多子空间聚类假设更为合适。但本文献中,由于背景具有非局部自相关性,使用一个低秩空间足以模拟背景。因此,为了降低算法的复杂度,本文仅使用一个低秩空间假设(only employ one low-rank subspace assumption)。
4.3 Noise Patch-Image N
本文假设随机噪声满足独立同分布,与公式(7),
![]() …………………… (7) 式中,
…………………… (7) 式中,![]() ,
, ![]() 表示F-范数,定义为
表示F-范数,定义为 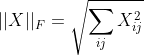 。
。
4.4 小目标检测模型(算法原理)
最终的目标是“检测目标”,因此得到目标图像T 是关键。
首先,假设红外图像不包含噪声,IPI Model 可简化为 D = T + B,求解目标图T即可转化为从原始图像矩阵中恢复稀疏矩阵与低秩矩阵的最优化问题,可使用主成分追踪(Principal Component Pursuit, PCP)来求解这一凸优化问题,见公式(8)。
![]() ………………………… (8)
………………………… (8)
式中,![]() 表示核范数,即奇异值之和;
表示核范数,即奇异值之和;![]() 表示1-范数,定义为
表示1-范数,定义为![]() ;
;  表示非负权重。
表示非负权重。
这里为了便于计算,使用![]() 分别取代了公式(6)中的
分别取代了公式(6)中的![]() 与公式(5)中的
与公式(5)中的![]() 。
。
使用主成分追踪(PCP)这一思想,有两点优势:
- 对于不同的图像,不需要估计公式(5)(6)中的k,r;
- 转化为凸优化问题后,算法不仅对目标的尺寸、亮度变化具有鲁棒性,而且可以适应含不同杂波的背景。
其次,考虑图像中的噪声,问题转化为公式(9)。
![]() …………………………(9)
…………………………(9)
公式(9)所示凸优化问题,即从包含噪声的图像中同时分离目标图像T和背景图像B。在背景估计问题中,求解背景图也很重要,例如在一些复杂背景下拍摄的图像,求解背景图可以评估检测的可靠性,也可以用于运动成像系统中的图像配准。
公式(9)进一步演化为求解公式(10)的对偶问题。
![]() …………………………… (10)
…………………………… (10)
式中, 为非负权重,且在本文中取值不固定。
为非负权重,且在本文中取值不固定。
公式(10)为凸优化问题,可使用Accelerated Proximal Gradient(APG)方法求解。
4.5 完整算法
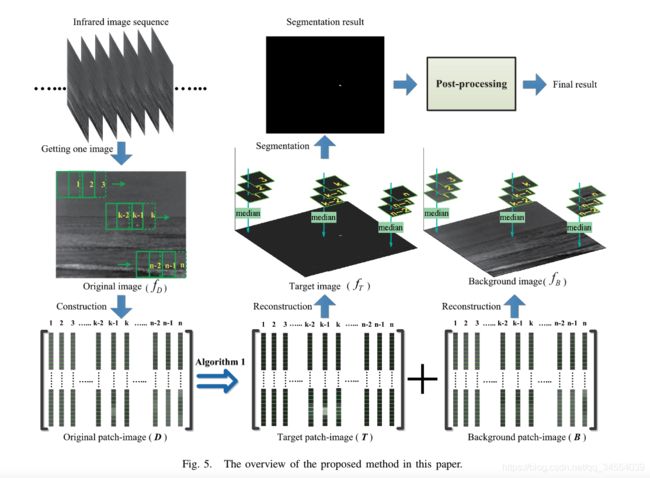
第一步:使用patch-image构建方法,得到IPI Model ,![]() ;
;
第二步:使用Algorithm 1 从图像D中分别求目标图T和背景图B;

算法中,![]() 表示矩阵
表示矩阵  的转置,
的转置, ![]() 门限函数;
门限函数;
……………………………… (11),式中 ![]() .
.
本文在算法1中的参数设置:
![]() , 其中[m,n]表示原图像
, 其中[m,n]表示原图像![]() 的大小;
的大小;![]() 分别为patch-image D 第2和第4个奇异值(从大到小排列)。
分别为patch-image D 第2和第4个奇异值(从大到小排列)。
第三步:使用patch-image B、T重构![]() ;
;
本文选用![]() 实现重构重叠区域的像素值,与mean相比,median的鲁棒性更强;如果不需要对背景进行预测,可以只重构目标图像以减少计算量。
实现重构重叠区域的像素值,与mean相比,median的鲁棒性更强;如果不需要对背景进行预测,可以只重构目标图像以减少计算量。
第四步:使用阈值分割对目标图像![]() 进行自适应分割;
进行自适应分割;
分割阈值的计算遵循公式(12) ![]() ……………………………… (12)
……………………………… (12)
式中, 分别为目标图像
分别为目标图像![]() 的灰度均值和标准差;
的灰度均值和标准差;![]() 为由实验测得的常量,
为由实验测得的常量,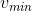 是为了降低虚警率。
是为了降低虚警率。
如果只检测“亮”目标,遵循的分割原则是满足:![]() 的为目标,否则为背景。
的为目标,否则为背景。
如果既要检测“亮”目标又要检测“暗”目标,使用双阈值分割原则![]() ,其中,
,其中,![]() ,
,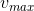 也是由实验得到的常量,可以降低虚警率
也是由实验得到的常量,可以降低虚警率
双阈值分割,目标像素值满足:![]() ,否则为背景。
,否则为背景。
第五步:后处理对分割结果进行细化。
可以采用连通域分析或形态学分析来细化分割结果。
此外,可以利用通过分析重构背景图像中,目标周围区域的背景复杂度来判断目标检测结果是否可靠,如果目标周围区域背景简单,则检测结果的可靠性更高。
但为了保证公平性,本文在与baseline方法做对比时,没有进行post-processing,而是直接用阈值分割结果与baseline方法做对比。
(所以,如果提出一种post-processing算法进一步提高阈值分割后的目标检测率是不是也是一个可以继续做下去的点呢?)
4.6 算法的复杂度分析
本文所提算法的计算时间来自3个方面:(1)PCP 计算,即从原图D中分离目标T与背景B;(2)图像重构;(3)阈值分割。
算法的时间复杂度为:![]() 。
。
二、MATLAB复现算法
源码来自文献作者的github:https://github.com/gaocq/IPI-for-small-target-detection <——完整代码在这里
2.1 构造patch-image
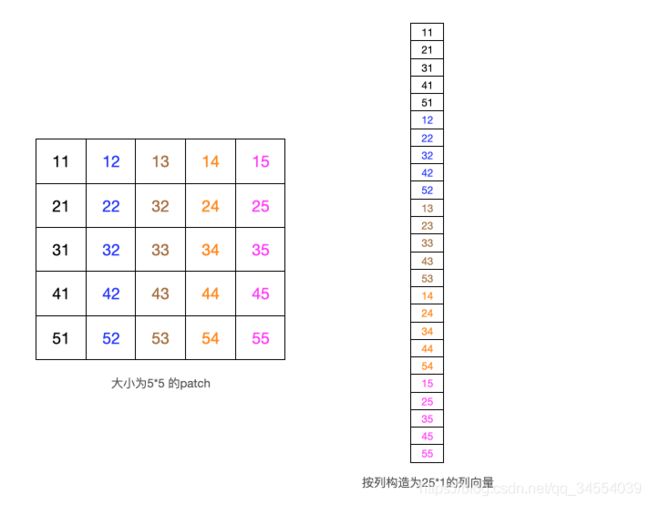
如下图,展示了大小为5*5的patch如何被构造为25*1的列向量。
下图,展示了当图像大小为20*20,patch大小为5*5,patch的水平、垂直方向每次的移动步长均为1时,如何由![]() 构造
构造 ,最终得到的D的大小为:
,最终得到的D的大小为: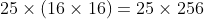
可以引申出一个公式:当原图像大小为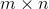 ,patch的大小为
,patch的大小为![]() ,patch在水平和垂直方向的移动步长分别为
,patch在水平和垂直方向的移动步长分别为![]() 时,
时,
最终得到的patch数量为:![]() ,最终得到的patch-image的大小为:
,最终得到的patch-image的大小为:![]() 。
。

A = [];
h = 20;
w = 20;
for i = 1:h
for j = 1:w
A(i,j) = j*10 + i;
end
end
A = A';
%% 构造patch-image
B = zeros(h,w);
dw = 5;
dh = 5;
x_step = 1;
y_step = 1;
D = [];
for i = 1:y_step:h-dh+1
for j = 1:x_step:w-dw+1
temp = A(i:i+dh-1, j:j+dw-1);
D = [D, temp(:)];
end
end2.2 低秩稀疏矩阵恢复
参考资料:https://zhuanlan.zhihu.com/p/114693135
该博文提到了交替方向方法(Alternating direction methods, ADM),实现了低秩、稀疏矩阵恢复,同时提到了鲁棒主成分分析(Robust PCA)。
本论文使用加速近端梯度下降法(Accelerated Proximal Gradient, APG)求解该低秩、稀疏矩阵分离这一凸优化问题。
下面给出本文作者提供的APG_IR函数接口,该函数至少输入两个参数:D -- 表示 pathc-iamge, lambda -- 在本文中取值为:![]() , 其中[m,n]表示原图像
, 其中[m,n]表示原图像![]() 的大小。
的大小。
输出 A_hat 表示为低秩矩阵,E_hat为稀疏矩阵。
function [A_hat,E_hat] = APG_IR(D, lambda, maxIter, tol, ...
lineSearchFlag, continuationFlag, eta, mu, outputFileName)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Paremeter Explanation
%
% D - m x n matrix of observations/data (required input)
% lambda - weight on sparse error term in the cost function (required input)
%
% tol - tolerance for stopping criterion.
% - DEFAULT 1e-7 if omitted or -1.
% maxIter - maximum number of iterations
% - DEFAULT 10000, if omitted or -1.
% lineSearchFlag - 1 if line search is to be done every iteration
% - DEFAULT 0, if omitted or -1.
% continuationFlag - 1 if a continuation is to be done on the parameter mu
% - DEFAULT 1, if omitted or -1.
% eta - line search parameter, should be in (0,1)
% - ignored if lineSearchFlag is 0.
% - DEFAULT 0.9, if omitted or -1.
% mu - relaxation parameter
% - ignored if continuationFlag is 1.
% - DEFAULT 1e-3, if omitted or -1.
% outputFileName - Details of each iteration are dumped here, if provided.
%
% [A_hat, E_hat] - estimates for the low-rank part and error part, respectively
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
if nargin < 2
error('Too few arguments') ;
end
if nargin < 4
tol = 1e-6 ;
elseif tol == -1
tol = 1e-6 ;
end
if nargin < 3
maxIter = 1000 ;
elseif maxIter == -1
maxIter = 1000 ;
end
if nargin < 6
continuationFlag = 1 ;
elseif continuationFlag == -1 ;
continuationFlag = 1 ;
end
if ~continuationFlag
if nargin < 8
mu = 1e-3 ;
elseif mu == -1
mu = 1e-3 ;
end
end
% mu = 1e6 ;
DISPLAY_EVERY = 20 ;
DISPLAY = 0 ;
%% Initializing optimization variables
[m, n] = size(D) ;
t_k = 1 ; % t^k
t_km1 = 1 ; % t^{k-1}
tau_0 = 2 ; % square of Lipschitz constant for the RPCA problem
X_km1_A = zeros(m,n) ; X_km1_E = zeros(m,n) ; % X^{k-1} = (A^{k-1},E^{k-1})
X_k_A = zeros(m,n) ; X_k_E = zeros(m,n) ; % X^{k} = (A^{k},E^{k})
if continuationFlag
mu_0 = norm(D) ;
mu_k = 0.99*mu_0 ;
mu_bar = 1e-9 * mu_0 ;
else
mu_k = mu ;
end
[U S V] = svd(D, 'econ');
s = diag(S);
mu_k = s(2);
mu_bar = 0.005 * s(4);
tau_k = tau_0 ;
converged = 0 ;
numIter = 0 ;
NOChange_counter = 0;
pre_rank = 0;
pre_cardE = 0;
% tol = 1e-6 ;
%% Start main loop
while ~converged
Y_k_A = X_k_A + ((t_km1 - 1)/t_k)*(X_k_A-X_km1_A) ;
Y_k_E = X_k_E + ((t_km1 - 1)/t_k)*(X_k_E-X_km1_E) ;
G_k_A = Y_k_A - (1/tau_k)*(Y_k_A+Y_k_E-D) ;
G_k_E = Y_k_E - (1/tau_k)*(Y_k_A+Y_k_E-D) ;
[U S V] = svd(G_k_A, 'econ');
diagS = diag(S) ;
% temp = max(diagS(150), mu_k/tau_k);
% X_kp1_A = U * diag(pos(diagS - temp)) * V';
X_kp1_A = U * diag(pos(diagS- mu_k/tau_k)) * V';
% X_kp1_E = sign(G_k_E) .* pos( abs(G_k_E) - lambda* temp );
X_kp1_E = sign(G_k_E) .* pos( abs(G_k_E) - lambda* mu_k/tau_k );
% rankA = sum(diagS>temp);
rankA = sum(diagS>mu_k/tau_k);
cardE = sum(sum(double(abs(X_kp1_E)>0)));
t_kp1 = 0.5*(1+sqrt(1+4*t_k*t_k)) ;
temp = X_kp1_A + X_kp1_E - Y_k_A - Y_k_E ;
S_kp1_A = tau_k*(Y_k_A-X_kp1_A) + temp ;
S_kp1_E = tau_k*(Y_k_E-X_kp1_E) + temp ;
stoppingCriterion = norm([S_kp1_A,S_kp1_E],'fro') / (tau_k * max(1, norm([X_kp1_A, X_kp1_E],'fro'))) ;
if stoppingCriterion <= tol
converged = 1 ;
end
if continuationFlag
mu_k = max(0.9*mu_k, mu_bar) ;
end
t_km1 = t_k ;
t_k = t_kp1 ;
X_km1_A = X_k_A ; X_km1_E = X_k_E ;
X_k_A = X_kp1_A ; X_k_E = X_kp1_E ;
numIter = numIter + 1 ;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% The iteration process can be finished if the rank of A keeps the same
% many times;
if pre_rank == rankA
NOChange_counter = NOChange_counter +1;
if NOChange_counter > 10 && abs(cardE-pre_cardE) < 20
converged = 1 ;
end
else
NOChange_counter = 0;
pre_cardE = cardE;
end
pre_rank = rankA;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% In practice, the APG algorithm, sometimes, cannot get
% a strictly low-rank matrix A_hat after iteration process. Many
% singular valus of the obtained matrix A_hat, however, are extremely small. This can be considered
% to be low-rank to a certain extent. Experimental results show that the final recoverd
% backgournd image and target image are good.
% Alternatively, we can make the rank of matrix A_hat lower using the following truncation.
% This trick can make the APG algorithm faster and the performance of our algorithm is still satisfied.
% Here we set the truncated threshold as 0.3, while it can be adaptively set based on your actual scenarios.
if rankA > 0.3 * min([m n])
converged = 1 ;
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
if DISPLAY && mod(numIter,DISPLAY_EVERY) == 0
disp(['Iteration ' num2str(numIter) ' rank(A) ' num2str(rankA) ...
' ||E||_0 ' num2str(cardE)])
end
if nargin > 8
fprintf(fid, '%s\n', ['Iteration ' num2str(numIter) ' rank(A) ' num2str(rankA) ...
' ||E||_0 ' num2str(cardE) ' Stopping Criterion ' ...
num2str(stoppingCriterion)]) ;
end
if ~converged && numIter >= maxIter
disp('Maximum iterations reached') ;
converged = 1 ;
end
end
A_hat = X_k_A ;
E_hat = X_k_E ;
2.3 重构背景图与目标图
这一部分完全是构造的相反步骤,依次取D图中的一列将其重构为patch,按照滑动步长进行遍历并重构。
%% 重构原图
AA = zeros(h,w,100);
C = zeros(h,w);
temp = zeros(dh, dw);
index = 0;
for i = 1:y_step:h-dh+1
for j = 1:x_step:w-dw+1
index = index + 1;
temp(:) = D(:,index);
C(i:i+dh-1, j:j+dw-1) = C(i:i+dh-1, j:j+dw-1) + 1; % 记录每个像素点重叠的次数(被滑动窗口遍历的次数)
for ii = i:i+dh-1
for jj = j:j+dw-1
AA(ii, jj, C(ii,jj)) = temp(ii-i+1, jj-j+1);
end
end
end
end
f_B = zeros(h, w);
%% 使用median恢复重叠区域的像素值
for i=1:h
for j=1:w
if C(i,j) > 0
f_B(i,j) = mean(AA(i,j,1:C(i,j)));
end
end
end2.4 对比实验
IPI Model的算法思路很清晰,本质就是将目标检测转化为恢复低秩、稀疏矩阵的优化问题。
但作者花很大篇幅去介绍了为什么“红外图像的弱小目标检测”可一转化为“恢复低秩、稀疏矩阵”的优化问题,这里作者就做出了两点假设:
(1)目标尺寸小,尽管目标尺寸大小可能在2*2~10*10不等,但目标相对整幅图所占像素数仍不超过0.15%,将其看作“稀疏矩阵”条件成立;
(2)假设背景具有非局部子相关性 non-local self-correlation,将其看作“低秩矩阵”条件成立。
本文算法基于上述两点假设,同时提出了IPI Model,打破了将弱小目标看作“二维高斯”分布的传统模型,相比之下,IPI Model 更具一般性。
学习到这里,笔者也对该算法进行了分解和尝试:本文算法的时间主要用在了patch-image的构造与重构,使用相同的图像,构造与不构造patch-image的时间相差接近10倍。如果不构造patch-image ,直接使用APG_IR分解原图像,结果如下:不构造patch-image,直接使用APG在原图上做低秩、稀疏矩阵的恢复,处理5张图共耗时1.48s,从结果看很不理想,背景结果不理想,但得到的目标图背景相比之前似乎变纯净了,减少了很多边缘噪声,背景更加平滑。

构造patch-image的输出结果:构造patch-iamge并重构(这里图像大小为150*200,patch大小为50*50,水平垂直步长均为10),使用APG算法恢复,处理相同的5张图片,共耗时14.6988s.

对比之下,可以看到,构造patch-image, 使用IPI Model 的分解结果明显更好。
之前一直没搞明白为什么作者一定要构造patch-image,对低秩、稀疏矩阵的优化的数学原理也没想明白,自己想当然做了上面的尝试。后来和大神师兄交流了一下,发现自己之前对论文内容的思考太欠缺了,所以来更新一下。
补充几点基础知识:
1. 什么是矩阵的秩?为什么可以将背景看作低秩矩阵?
参考:https://blog.csdn.net/manduner/article/details/80564414
这里涉及到线性方程组的“高斯消元法”、“行阶梯矩阵”两个很基本的概念。
矩阵的秩定义:在矩阵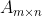 的行阶梯矩阵中,其非零行的行数称为矩阵的秩,记为
的行阶梯矩阵中,其非零行的行数称为矩阵的秩,记为![]() .
.
秩的物理意义:反映了矩阵行、列之间的相关性,如果矩阵的各行、列之间是不相关的,则矩阵满秩。
而矩阵行、列之间的相关性反映了矩阵的结构信息,所以如果矩阵表达的是结构信息,其各行/列之间存在一定的相关性,则矩阵一般是低秩的。
这也就可以理解为什么作者要构造patch-image了。
如下图,可粗略理解,构造成行向量后,由于图像背景相邻像素之间有相关性,所以背景可以看作稀疏矩阵。
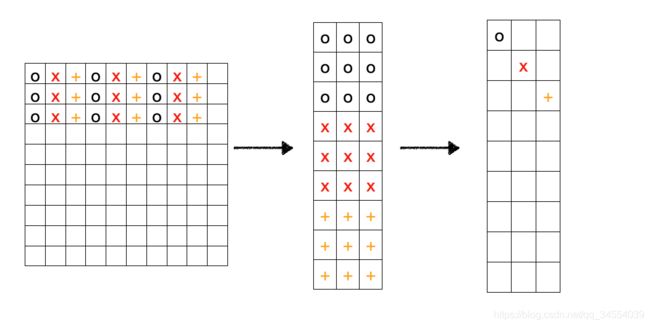
原图像的行、列之间相关性肯定不如patch-image,甚至由于噪声的影响,图像矩阵很可能是满秩的,直接拿来做优化是不可行的。
2. 鲁棒主成分分析 Robust PCA
参考链接:https://www.cnblogs.com/Eufisky/p/12805652.html
https://blog.csdn.net/zouxy09/article/details/24971995
L0范数:向量中非0元素的个数;
L1范数:向量中各个元素的绝对值之和。
L1范数和L0范数都可以实现稀疏,但L1具有更好的优化特性,应用更广泛。
2.5 论文实验结论
文中,作者通过控制变量共做了2组实验,实验参数分别为patch的大小(size)以及水平、垂直方向的滑动步长(sliding step);选择的实验结果的评价指标为:使用阈值分割固定各组实验的虚警率为2.5/图像数量时,使用目标检测率和目标的平均信杂比SCR的提升作为结果评价指标。
第一组:固定patch的大小,改变滑动步长。
| 实验参数 | 选取patch的大小为50*50,滑动步长的大小分别为6,8,10,12,14(水平、垂直方向的步长相同) |
| 实验结果 | 当目标尺寸小时,滑动步长越小,效果越好;随着目标尺寸变大,步长越大,检测效果越好。 |
| 实验结论 | 当滑动步长比较小时,重叠部分的像素比较多,做重构时使用的像素数量也比较多。滑动步长对目标检测的效果影响并不大, |
第二组:改变patch的大小。
| 实验参数 | 选取patch的大小为30*30,40*40,50*50,60*60,70*70,80*80,81* 81,82*82,83*83;滑动步长分别为5,7,9,10,12,14,14,14,14 |
| 实验结果 | 当patch的大小为80*80时,检测效果最好,当patch的大小大于80时,检测率逐渐下降。 |
| 实验结论 | patch size对检测结果的影响比sliding step大。 |
与baseline method做比较,这里选择的baseline method包括 Top-hat, Max-Mean, Max-Median.
| 实验参数 | 选取了两组(p_w*ph,sliding_step)分别是(50*50,9)(80*80,14),baseline方法选择的filter size 为15*15 |
| 实验结果 | 本文算法对目标尺寸的鲁棒性更强。Top-hat算法的检测率随目标尺寸的增大而提高,而Max-mean, Max-median反之。 |
三、后记
IPI检测算法算是单帧的红外弱小目标检测的经典算法,但是该算法的时间复杂度较高。文中的实验部分作者花了较大篇幅去介绍如何合成含弱小目标的仿真图像,合成图像为算法的实验结果提供了实验依据,实验结果很充分,如果数据集不足,可以参考这种方法。