获取弹窗文本_批量下载北大法宝的法律法规文本

引言
因项目需要,我计划从北大法宝下载一些法律法规文本,仅以此文记录我的心得体会。本文不会将项目涉及到的所有源代码都直接挂出来,只贴一些代码片段,聪明的你应该能够很轻松地把代码片段连成可用的完整脚本。
模拟登录
北大法宝的大部分功能都需要在登录状态下使用,我新注册的账号可以有7天的试用期,非常不错,美滋滋。如果老铁们愿意花点小钱的话,可以在某平台上买到一个可用的账号。
浏览器上的登录过程就不说了,只说一下python的模拟登录。
北大法宝的模拟登录非常简单,只要发送下面这个POST请求就可以了,可以看到用户名和密码都是以明文形式传递的。

使用requests的Session()发送这个POST请求,就可以让服务器记住登录状态了。
def login(self, username, password):
'''
登录北大法宝,需要提供用户名与密码
:param username: 用户名
:param password: 与用户名相对应的密码
:return None: Session会自动保持登录状态
'''
# 登录网址
url = "https://login.pkulaw.com/login"
# 使用Session发送POST请求,登录北大法宝
self.s.post(url=url, data = {"LoginName": username, "LoginPwd": password}, headers=self.headers)浏览器中的批量下载
如果要下载某个主题的法律法规文本,显然,我们需要向服务器提供一个关键词。在浏览器中的操作是:在搜索框内输入你感兴趣的关键词,然后回车。

我以开发区为关键词,敲完回车以后,浏览器告知我,它检索到了482篇文本。如下图所示:

我们勾选上图中的全选框,然后点击批量下载,会出现下面的弹窗:
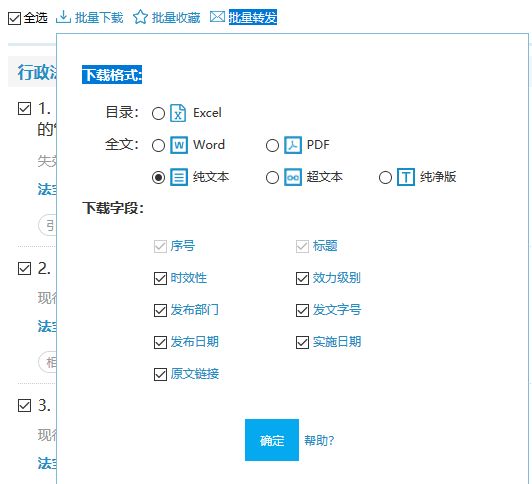
点击确定按钮以后,就下载了一个压缩包。有一个小问题是,这里虽然说是全选,但实际上只选了八份文件。因为当前页面就只放了八份文件,如下图所示:

不过还好,上图中有一个更多按钮可以点,点一下这个更多按钮,我们就能拿到更多的文本了。

从图中能够看出,当前检索出来的内容是行政法规这个小类,除行政法规外,还有司法解释、部门规章、行业规定等。虽然当前页面显示的内容的范围变窄了,但是可以一次性下载100篇文本了,还是非常不错的。
如果只是简单地下载几百篇文本,手动下载挺好的,比脚本快得多。但如果下载的量比较多,这种机械性的重复难免会让人有些难受。下面来说说如何用脚本完成批量下载任务。
python实现批量下载
我们按照上面的流程一直走到点击确认按钮这一步,此时只要一点击这个确认按钮,浏览器就会下载压缩包。我们在点击确认按钮之前打开开发者工具,看看浏览器向服务器发送了什么请求,如果能够用脚本复现这个请求,不就能用python实现批量下载了嘛。
比较难受的是,点击完确认按钮以后,浏览器打开了一个新的窗口,下载任务创建完以后,它又自动关掉了。因为开发者工具只能捕获到当前标签页(或许是我不会设置),所以我们是看不到浏览器发送的请求。经百度,浏览器是可以设置成新窗口打开时,自动弹出开发者工具的,这样的话就可以在另一个窗口的开发者工具里面看到浏览器向服务器发送的请求了。
我用的是谷歌核的edge浏览器,可以在开发者工具的设置里面勾上下图中的选项。

但是下载任务创建完毕以后,新创建的窗口又关闭了,开发者工具也跟着不见了。机智的我是这么操作的:在点击完确定按钮后,迅速地断掉了wifi。只要手够快,这个请求得不到服务器的返回,就会在这里卡一下。心疼家里网太好的老铁,完全没有这种操作的空间。
用手机把它发送的请求拍下来了:
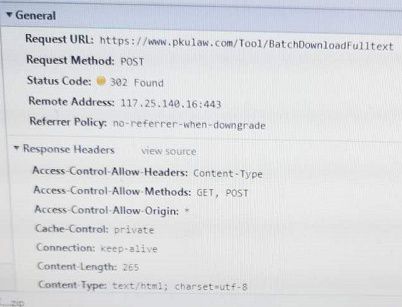

经试验,我直接向服务器发送这个请求,我就能拿到我想要的压缩包。其他所有的参数都是定值,只有gids这个参数会发生变化,稍稍检查一下网页的源代码就会发现gids其实就是勾选上的文本的链接,或者说是文本的id。假如我们拿到了所有的文本id,使用下面的代码就可以下载压缩包了:
def download(self, gids):
'''
将给定的文本压缩包下载到给定位置
:param gids: 待下载文本的gids
'''
# 下载链接
url = 'https://www.pkulaw.com/Tool/BatchDownloadFulltext'
form_data = {
'typeName': "fullTxt",
'keepFields': "true",
'keepFblxInFulltext': "true",
'keepRelatedFile': "true",
'library': self.current_class,
'flag': "undefined",
'gids': gids,
'curLib': self.current_class,
'downloadType': 'DownloadFullText',
'currentUrl': "https://www.pkulaw.com"
}
# 下载并存储压缩包
resp = self.s.post(url=url, data=form_data, headers=self.headers).content
with open('tmp.zip', "wb") as f:
f.write(resp)页面中文本的id很难找么?一定也不难,我们只要解析一下当前检索页面所有的文本链接就行了 。比如说如果某个文本的链接是:https://pkulaw.com/chl/4e0c2ac34db8dab6bdfb.html ,链接里面的4e0c2ac34db8dab6bdfb就是它的id。 假如我们手上有源文件,用下面的代码就能抽取出所有的id了,由id拼接gids也就是个join()。
html = etree.HTML(resp).xpath("//div[@class='list-title']//a[1]/@href")
gids = [re.search(r'.*/(.*?).html', h).group(1) for h in html]
return ",".join(gids)现在所有的问题都变成了,我们如何获取当前检索页面的源代码呢?不难发现,检索页面的源代码是如下POST请求发出后返回的:

这个POST请求的payload比较长,但其中大多数参数都是定值,很容易构造,除了下面这个参数以外:

假设我们已经知道了QueryBase64Request,用下面的代码就能拿到检索页的源代码:
url = "https://www.pkulaw.com/law/search/RecordSearch"
form_data = {
'Menu': 'law',
'Keywords': '',
'SearchKeywordType': 'DefaultSearch',
'MatchType': 'Exact',
'RangeType': 'Piece',
'Library': self.current_class,
'ClassFlag': self.current_class,
'GroupLibraries': '',
'QueryOnClick': 'False',
'AfterSearch': 'True',
'PreviousLib': self.current_class,
'pdfStr': '',
'pdfTitle': '',
'IsSynonymSearch': 'true',
'RequestFrom': '',
'IsAdv': 'False',
'ClassCodeKey': class_code,
'GroupByIndex': '0',
'OrderByIndex': '4',
'ShowType': 'Default',
'GroupValue': '',
'TitleKeywords': '',
'FullTextKeywords': '',
'Pager.PageIndex': page_index, # 控制页码
'RecordShowType': 'List',
'Pager.PageSize': '100', # 一页显示100条数据
'QueryBase64Request': self.base64str, # 检索条件
'VerifyCodeResult': self.verify_code, # 验证码(如果必要的话)
'isEng': 'chinese',
'OldPageIndex': '',
'newPageIndex': '',
'X-Requested-With': 'XMLHttpRequest',
}
resp = self.s.post(url=url, data=form_data, headers=headers).text如果我们在网页的源代码中搜索QueryBase64Request,就会发现这个字符串就明晃晃地放在网页的源代码当中:

到这里为止,我们就能用python下载压缩包了。如果要下载不同的页面,只需要修改相应参数以获取不同的检索结果页的源代码就行了。(我的代码片段中用变量表示的字段都是可以修改的)
验证码的处理
北大法宝也是有反爬虫措施的,服务器设置了一个检索上限,如下图所示:

只要用户想要查看200条以后的数据,就需要通过一个简单的滑动验证码才行,如果一页是100条数据的话,那么在查询第三页及以后的数据时,每页都要滑动下面的验证码:

我们可以把验证码产生、滑动、核验通过这一过程中所有的请求都列在下面:
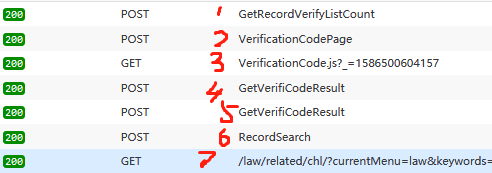
这几个请求的逻辑是非常清晰的,首先问服务器产生验证码的上限是多少(1),服务器告知为200,当尝试检索200以后的信息时,就需要向服务器所要一份验证码(2),验证码的逻辑(3)和验证码的素材(4)都需要从网上下载。滑动小滑块,松开鼠标以后,浏览器要把我们滑动验证码的结果发送给服务器(5),服务器如果校验通过了,就会给我们发送我们请求的资源(6,7)。
因为这个验证码与我们请求数据的多少有直接关系,不是放慢访问速度就能解决的,所以我们必须要解决它才行,万幸解决这个验证码是非常简单的。
我们依然使用倒叙的方式来描述整个过程,图中的第六步是我们最关心的步骤,因为它返回了我们想要的源文件。这个经过验证码洗礼后的请求,和无需验证码认证的请求有什么不同之处呢?
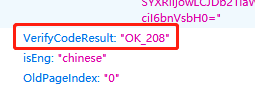
只要比对第二页(无需验证码)的请求和第三页(需要验证码)的请求,不难发现两个请求的差别在于,第三页的请求需要在参数里面挂上OK_208。直觉告诉我们这个208可能就是缺口所在的位置,使用微信的截图工具在选取截图区域的时候,上面会有数字告诉我们当前截取的区域大小,不难发现,确实如此,这里要带上的数字就是验证码缺口最左边的距离图片最左侧的长度。
再看第5个请求的返回,不难发现,这个数字是服务器返回给我们的:
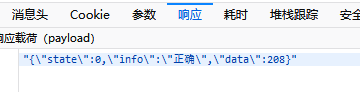
现在问题就变成了,我们要如何构造第5个请求。如果我们能够构造好这里的请求,不就能够通过验证码了嘛。看下这个请求的请求体:

经试验,第一个参数act是个定值,timespan的取值无关痛痒。关键点在于如何拿到point和datelist两个参数,这两个参数的含义也是非常直白的,point就是你滑动滑块最后停下来的位置,datelist就是鼠标滑动的轨迹,记录的是在每个时间戳上鼠标拖动的长度。显然,我们需要计算出缺口所在的位置,然后用一定的方法拟合出鼠标轨迹,完成这两项操作以后,我们就能通过验证码了。
opencv提供的matchTemplate可以非常完美地解决第一个问题,具体帮助文档可见:

假如我们有小缺口图片和背景图片,使用下面的代码就能够给出缺口所在的位置了:
slider = cv2.imread(self.slide, 0)
captcha = cv2.imread(self.bg, 0)
result = cv2.matchTemplate(captcha, slider, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
return max_loc[0]有了缺口的位置以后,我们要拟合出鼠标轨迹来。我使用下面代码来拟合鼠标轨迹:
def _generate_track(self, target: int) -> str:
'''
根据拿到的答案生成相应的轨迹
:param target: 想要生成的轨迹的横坐标
:return str: 返回计算好的轨迹
'''
template_track = [1, 3, 4, 6, 7, 9, 10, 11, 12, 13, 15, 16, 17, 18,
19, 20, 21, 23, 23, 25, 26, 27, 28, 29, 30, 31,
32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 44, 45, 46, 47]
threshold = max(template_track)
scale = target // threshold
if target>threshold:
num_track = template_track[:3] + [t*scale for t in template_track]
else:
num_track = [t for t in template_track if t < target]
# 经过上面处理的轨迹最后停下来的位置如果不是目标点,调整到终点
last_num = num_track[-1]
if target != last_num:
gap = target - last_num
num_track.append(last_num + gap//2)
num_track.append(target)
# 数字轨迹处理好了以后就开始处理时间戳了
start_time = int(time.time() * 1000)
time_track = [start_time] * len(num_track)
for index in range(1, len(num_track)):
time_track[index] = time_track[index-1] + random.randint(17, 27)
# 拼接数字轨迹和时间轨迹
result = ""
for i,t in zip(num_track, time_track):
if result:
result += "|"
result += f"{i},{t}"
return result代码当中的列表是我拖动滑块完成一次验证码校验以后记录下来的鼠标轨迹,代码完成的工作实际上就是把我记录的轨迹放大一点或只截取其中的一份。并不知道北大法宝的验证码带不带行为认证,反正我生成的鼠标轨迹很容易通过服务器的校验。
问题现在就变成了,我怎么去拿验证码的图片?这个就非常简单了,我们构造一下第四个请求就可以了。滑块的图片和背景图的图片都是以base64格式的字符串传递过来的,可以用下面的代码完成图片的转换、切割与重组(因为服务器发过来的图是乱的)。
def _get_captcha(self):
'''
向服务器发送请求拿到一张验证码
'''
url = "https://www.pkulaw.com/VerificationCode/GetVerifiCodeResult"
form_data = {
'act': 'getcode',
'spec': '300*200',
}
headers = self.headers.copy()
headers.update({
'Host': 'www.pkulaw.com',
'Origin': 'https://www.pkulaw.com',
'Referer': 'https://www.pkulaw.com/',
'X-Requested-With': 'XMLHttpRequest',
})
resp = json.loads(self.s.post(url=url, headers=headers, data=form_data).json())
with open(self.slide, "wb") as f:
f.write(base64.b64decode(resp.get("small")[21:]))
with open(self.bg, "wb") as f:
f.write(base64.b64decode(resp.get("normal")[21:]))
print("成功地从服务器获取到验证码!")
# 从服务拿到的图片是错位的图片,要进行复原
# TODO: 直接使用IO流读取图片,不存盘减少IO
bg = Image.open(self.bg, 'r')
img_x,img_y = bg.size
new_img = Image.new('RGB', (img_x, img_y))
split_width = img_x // 10
split_height = img_y // 2
# 代码转换自`VerificationCode.js`
order_array = [int(t) for t in resp['array'].split(",")]
for index in range(len(order_array)):
# index代表拼接后图片上的序号
# num代表拼接前图片上的序号
num = order_array.index(index)
# 还原后的坐标点
y = split_height if index > 9 else 0
x = split_width * (index-10) if index>9 else split_width*index
# 还原前的坐标点
origin_y = split_height if num > 9 else 0
origin_x = split_width * (num-10) if num>9 else split_width*num
# 从还原前的坐标点处切图像,拼接到还原后的坐标点上
new_img.paste(bg.crop((origin_x, origin_y, origin_x+split_width, origin_y+split_height)),
(x,y,x+split_width, y+split_height))
new_img.save(self.bg)运行结果
用关键词经济来做实验,看看我们的思路和最后的脚本有没有什么大的问题吧。


放慢对服务器的访问速度,脚本的运行还是非常给力的~