人工智能-作业6:CNN实现XO识别
目录
- 模型构建与测试
-
- 构建模型
- 训练模型
- 测试
- 准确率
- 查看模型
-
- 查看训练好模型的特征图
- 查看训练好模型的卷积核
- 代码
-
- 训练模型代码
- 测试模型代码
- 参考文章
模型构建与测试
构建模型
实现代码
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3)
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200)
self.fc2 = nn.Linear(1200, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
运行结果
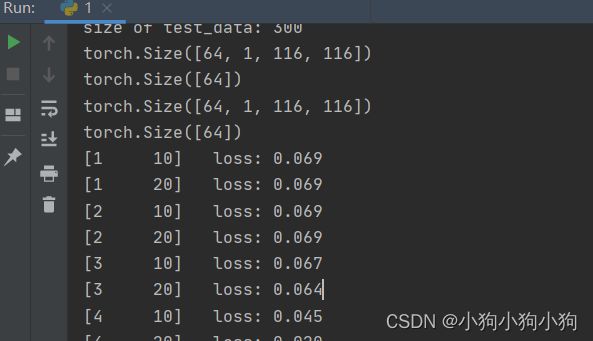
训练模型
实现代码
model = Net()
criterion = torch.nn.CrossEntropyLoss() # 损失函数 交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.1) # 优化函数:随机梯度下降
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(data_loader):
images, label = data
out = model(images)
loss = criterion(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
print('finished train')
# 保存模型
torch.save(model, 'model_name.pth') # 保存的是模型, 不止是w和b权重值
运行结果

测试
# 读取模型
model_load = torch.load('model_name.pth')
# 读取一张图片 images[0],测试
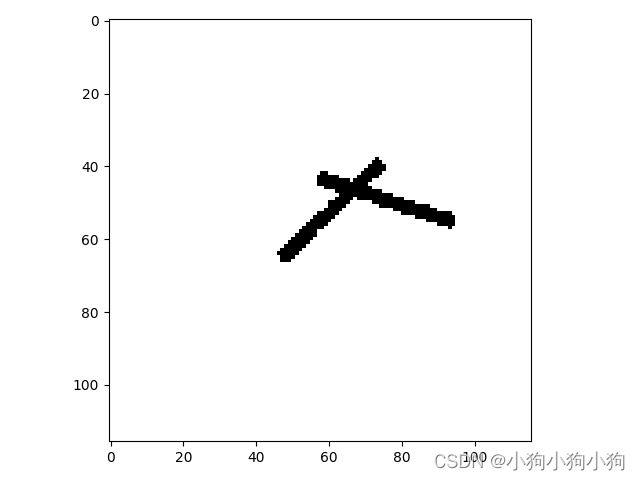
print("labels[0] truth:\t", labels[0])
x = images[0]
predicted = torch.max(model_load(x), 1)
print("labels[0] predict:\t", predicted.indices)
img = images[0].data.squeeze().numpy() # 将输出转换为图片的格式
plt.imshow(img, cmap='gray')
plt.show()
准确率
代码
# https://blog.csdn.net/qq_53345829/article/details/124308515
import torch
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.optim as optim
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'train_data'
path_test = r'test_data'
data_train = datasets.ImageFolder(path, transform=transforms)
data_test = datasets.ImageFolder(path_test, transform=transforms)
print("size of train_data:", len(data_train))
print("size of test_data:", len(data_test))
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
data_loader_test = DataLoader(data_test, batch_size=64, shuffle=True)
print(len(data_loader))
print(len(data_loader_test))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 读取模型
model = Net()
model.load_state_dict(torch.load('model_name1.pth', map_location='cpu')) # 导入网络的参数
# model_load = torch.load('model_name1.pth')
# https://blog.csdn.net/qq_41360787/article/details/104332706
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in data_loader_test: # 读取测试集
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
# "_," 的解释 https://blog.csdn.net/weixin_48249563/article/details/111387501
运行结果

查看模型
查看训练好模型的特征图
源代码
# 看看每层的 卷积核 长相,特征图 长相
# 获取网络结构的特征矩阵并可视化
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
# 定义图像预处理过程(要与网络模型训练过程中的预处理过程一致)
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'training_data_sm'
data_train = datasets.ImageFolder(path, transform=transforms)
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
outputs = []
x = self.conv1(x)
outputs.append(x)
x = self.relu(x)
outputs.append(x)
x = self.maxpool(x)
outputs.append(x)
x = self.conv2(x)
x = self.relu(x)
x = self.maxpool(x)
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return outputs
# create model
model1 = Net()
# load model weights加载预训练权重
# model_weight_path ="./AlexNet.pth"
model_weight_path = "model_name1.pth"
model1.load_state_dict(torch.load(model_weight_path))
# 打印出模型的结构
print(model1)
x = images[0]
# forward正向传播过程
out_put = model1(x)
for feature_map in out_put:
# [N, C, H, W] -> [C, H, W] 维度变换
im = np.squeeze(feature_map.detach().numpy())
# [C, H, W] -> [H, W, C]
im = np.transpose(im, [1, 2, 0])
print(im.shape)
# show 9 feature maps
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
# [H, W, C]
# 特征矩阵每一个channel对应的是一个二维的特征矩阵,就像灰度图像一样,channel=1
# plt.imshow(im[:, :, i])
plt.imshow(im[:, :, i], cmap='gray')
plt.show()
卷积后的特征图

池化后的特征图

激活后的特征图

查看训练好模型的卷积核
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 #有中文出现的情况,需要u'内容
# 定义图像预处理过程(要与网络模型训练过程中的预处理过程一致)
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'train_data'
data_train = datasets.ImageFolder(path, transform=transforms)
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
# print(images.shape)
# print(labels.shape)
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
outputs = []
x = self.maxpool(self.relu(self.conv1(x)))
# outputs.append(x)
x = self.maxpool(self.relu(self.conv2(x)))
outputs.append(x)
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return outputs
# create model
model1 = Net()
# load model weights加载预训练权重
model_weight_path = "model_name1.pth"
model1.load_state_dict(torch.load(model_weight_path))
x = images[0]
x = x.reshape([1, x.shape[0], x.shape[1], x.shape[2]])
# forward正向传播过程
out_put = model1(x)
weights_keys = model1.state_dict().keys()
for key in weights_keys:
print("key :", key)
# 卷积核通道排列顺序 [kernel_number, kernel_channel, kernel_height, kernel_width]
if key == "conv1.weight":
weight_t = model1.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, 0, :, :] # 获取第一个卷积核的信息参数
# show 9 kernel ,1 channel
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(k[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel1'
plt.title(title_name)
plt.show()
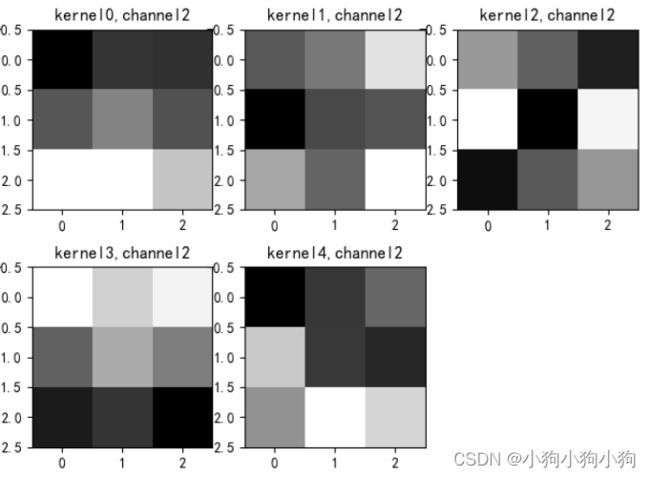
if key == "conv2.weight":
weight_t = model1.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, :, :, :] # 获取第一个卷积核的信息参数
print(k.shape)
print(k)
plt.figure()
for c in range(9):
channel = k[:, c, :, :]
for i in range(5):
ax = plt.subplot(2, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(channel[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel' + str(c)
plt.title(title_name)
plt.show()




代码
训练模型代码
import torch
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.optim as optim
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'train_data'
path_test = r'test_data'
data_train = datasets.ImageFolder(path, transform=transforms)
data_test = datasets.ImageFolder(path_test, transform=transforms)
print("size of train_data:",len(data_train))
print("size of test_data:",len(data_test))
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
data_loader_test = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(data_loader_test):
images, labels = data
print(images.shape)
print(labels.shape)
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net()
criterion = torch.nn.CrossEntropyLoss() # 损失函数 交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.1) # 优化函数:随机梯度下降
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(data_loader):
images, label = data
out = model(images)
loss = criterion(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
print('finished train')
# 保存模型 torch.save(model.state_dict(), model_path)
torch.save(model.state_dict(), 'model_name1.pth') # 保存的是模型, 不止是w和b权重值
# 读取模型
model = torch.load('model_name1.pth')
测试模型代码
import torch
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.optim as optim
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'train_data'
path_test = r'test_data'
data_train = datasets.ImageFolder(path, transform=transforms)
data_test = datasets.ImageFolder(path_test, transform=transforms)
print("size of train_data:", len(data_train))
print("size of test_data:", len(data_test))
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
data_loader_test = DataLoader(data_test, batch_size=64, shuffle=True)
print(len(data_loader))
print(len(data_loader_test))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 读取模型
model = Net()
model.load_state_dict(torch.load('model_name1.pth', map_location='cpu')) # 导入网络的参数
# model_load = torch.load('model_name1.pth')
# https://blog.csdn.net/qq_41360787/article/details/104332706
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in data_loader_test: # 读取测试集
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
参考文章
【2021-2022 春学期】人工智能-作业6:CNN实现XO识别