Linux | 进程概念、进程状态(僵尸进程、孤儿进程、守护进程)、进程地址空间
文章目录
- 进程和程序
- 操作系统如何控制和调度程序
- 进程控制块–PCB
- 子进程
- 进程状态
-
- 僵尸进程
- 孤儿进程
- 守护进程(精灵进程)
- 进程地址空间
-
- 引言
- 页表
进程和程序
- 程序: 一系列有序的指令集合(就是我们写的代码)。
- 进程: 进程就是程序的一次执行,是系统进行资源分配和调度的独立单位。
一个程序可以创建多个进程,每个进程的文本段相同,但是数据段、堆、堆栈段却不同。
进程的特性:
- 动态性:进程是动态的;程序则是静态的。
- 并发性:多个进程能在同一时间段内同时运行。
- 独立性:系统中独立获得资源和进行调度的基本单位。
- 异步性:各进程按不可预知的速度各自运行。
程序最初以某种可执行格式驻留在外存上(如:磁盘)。操作系统运行程序时将需要用到的代码和所有静态数据加载(load)到内存中(惰性执行,暂时用不到的代码不加载),方便 CPU 运行进程时使用。
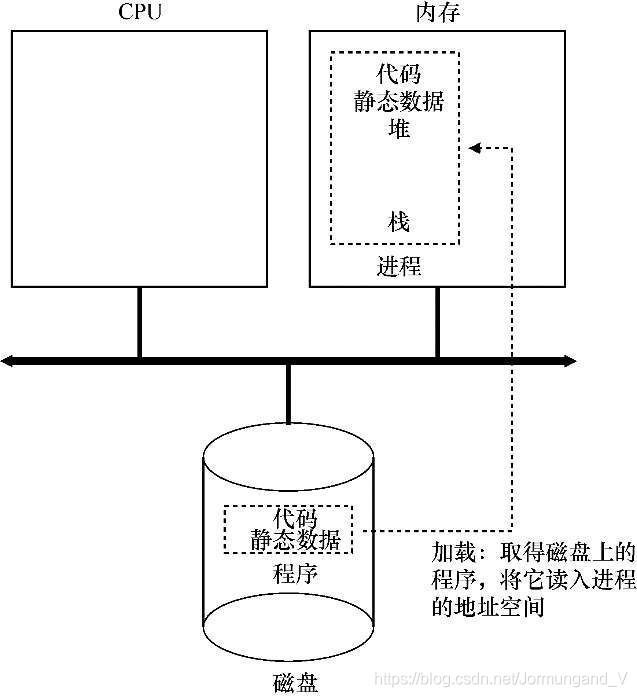
操作系统如何控制和调度程序
实际中,一个正常的系统可能会有上百个进程同时在运行,而我们只有少量的物理 CPU 可以使用,因此,如何满足诸多进程对于 CPU 的需求便成了重中之重。
按照冯诺依曼体系结构,所有的数据想要被CPU进行处理,第一步就是要将代码和数据加载到内存中。

操作系统通过 虚拟化CPU ,让一个进程只运行一个时间片,然后切换到其他进程,通过 快速切换 和 优先级调度 运行所有的程序,造成了同时运行的假象。这就是 时分共享CPU技术 ,也就是 CPU分时机制 。
但是,这里还存在着几个问题,CPU是如何在内存中找到每个程序的?CPU在来回调度时,如何能够从上一次运行的位置继续运行?如何能够保证继续处理上一条没有处理完的数据?
操作系统为了能够完成上述操作,设置了一个用于描述进程信息的数据结构—— PCB 。
进程控制块–PCB
操作系统为了能够使每个程序能够独立运行,在操作系统中为其配置了一个数据结构,也就是我们通常所说的 PCB(Process Control Block),这个数据结构在 Linux下是:task_struct
task_struct 中的内容:
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下文数据: 进程执行时处理器的寄存器中的数据。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和、使用的时钟数总和、时间限制、记账号等其他信息。
PCB有两种组织方式:
- 链接方式:将同一状态的进程PCB链成一个队列,多个状态对应多个不同的队列。
- 索引方式:将同一状态的进程归入一个索引表,多个状态对应多个不同的索引。
链接方式:
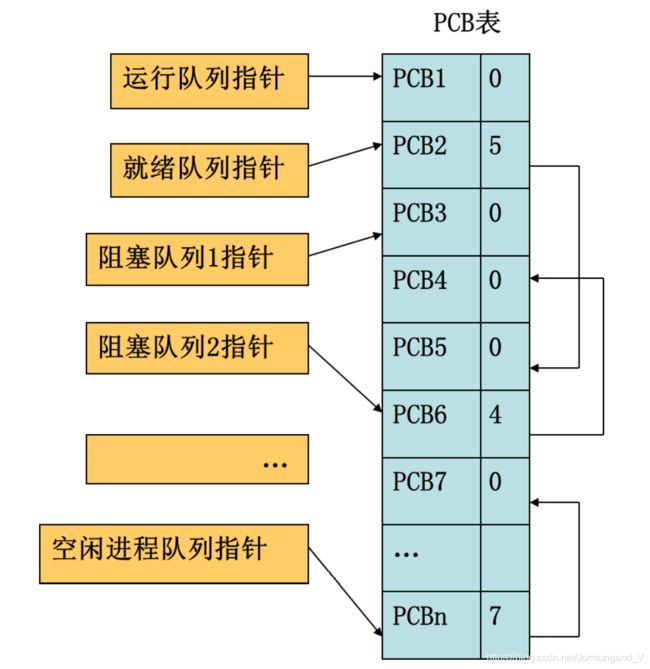
索引方式:
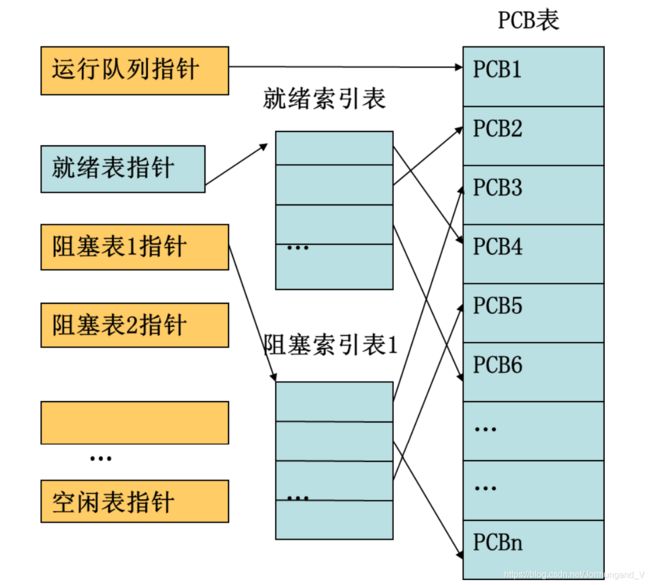
PCB是操作系统对一个运行中的程序(也就是进程)的描述,操作系统通过这个描述来实现对程序的运行调度:
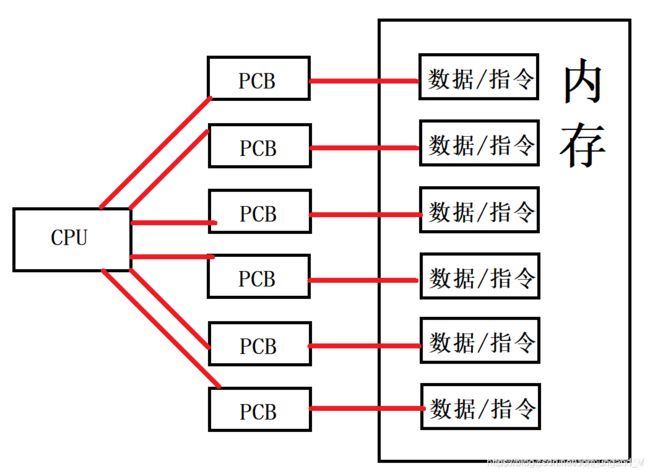
回到前面提出的问题:
- CPU通过PCB中的内存指针来找到程序在内存中的地址
- 通过上下文数据来记录运行中程序的各种信息
- 通过程序计数器来找到这个程序即将执行的下一条指令的地址
子进程
我们可以通过 fork 在一个 已经创建的进程内 创建一个 新的进程 ,这个 新的进程 就是 原先进程的 子进程 。
在子进程创建的时候,它从父进程的PCB中复制了很多数据,如内存指针、上下文数据、程序计数器等,所以它的代码、数据以及运行的位置,都与父进程一模一样。
由于代码段是只读的,所以两者的代码都一样,不可修改,而两者虽然虚拟地址相同,但物理地址不同,所以两者的数据都各自独立。
总结一下就是:父子进程代码共享,数据各自开辟空间。 (利用写时拷贝技术)
在 Linux 中,我们可以通过 fork 函数 来创建子进程
pid_t fork(void)
我们创建子进程,是希望它和父进程执行不一样的操作,那么我们该怎么实现呢?
最简单的方法就是通过
fork的返回值来进行代码分流,父进程的返回值是子进程的pid,而子进程的返回值是0,通过对返回值的判断,即可完成代码的分流。
但是这种方法的代码十分冗余,还有一种更加优秀的方法——程序替换。
进程状态
进程有三种基本状态:

- 执行状态(
running):- 进程正在
CPU上执行; - 只能有一个进程处于执行状态(单
CPU);
- 进程正在
- 就绪状态(
ready):- 进程已获得除
CPU外的所有资源,等待分配CPU就可执行; - 可以有多个进程处于就绪状态,组成就绪队列。
- 进程已获得除
- 阻塞状态(
waiting):- 进程因自身原因(如:等待I/O资源)而暂停执行,也称 “等待状态” 或 “睡眠状态” 。
- 可以有多个进程处于阻塞状态,组成阻塞队列
但是在 Linux 中,将状态细分到了六种:
- R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。
- S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠(
interruptible sleep)。 - **D磁盘休眠状态(Disk sleep):**有时候也叫不可中断睡眠状(
uninterruptible sleep),在这个状态的进程通常会等待IO的结束。 - T停止状态(stopped): 可以通过发送
SIGSTOP信号给进程来停(T)进程。这个被暂停的进程可以通过发送SIGCONT信号让进程继续运行。 - X死亡状态(dead): 这个状态只是一个返回状态,你不会在任务列表里看到这个状态
- Z僵死状态(Zombies): 进程已经退出了但是资源还没有完全被释放的一种状态。
僵尸进程
当子进程退出的时候,如果父进程没有读取到子进程的返回值,这时子进程就进入了 僵死状态 。
这时就处于一个很尴尬的局面,子进程实际上已经退出了,但是父进程认为它还在执行,所以并没有释放它的资源,所以子进程会一直卡在进程表中,等待父进程读取退出状态代码。此时的 子进程 就被称为 僵尸进程 ,它持有的资源一直无法释放,也无法再将其杀死。
对于僵尸进程,即使是 kill -9 对其也没有作用。这时只有两种解决方法:
- 进程等待
- 退出父进程
父进程退出,子进程保存退出的状态就没有任何意义了,因此就被释放了。 但是这并不是一个合理的方式,如果为了解决僵尸进程而刻意退出还不应该退出的父进程,不是很好的解决方法,我们应该避免僵尸进程的产生。
从上面可以看出,僵尸进程是非常危险的,因为我们无法通过正常途径将其解决,同时它会一直占用着我们的资源,同时 PCB 还需要对它的状态进行维护。并且一个用户所能创建的进程数量是有限的,如果一个父进程创建了大量的子进程而不进行回收,当达到上限时,我们就无法创建新的程序。
孤儿进程
如果父进程先于子进程退出,那么没有父进程的子进程会怎么样呢?持有资源不被回收?就像僵尸进程一样一直占用资源?
实际上,失去了父进程后的子进程被称为 “孤儿进程” ,但并不是没有父进程,而是会被 1 号进程 init 统一收养,然后由 Init 进程回收。
守护进程(精灵进程)
守护进程:一种特殊的孤儿进程,父进程是一号进程,运行在后台,与终端和登陆会话脱离关系,不受影响。
守护进程通常是一种运行在系统后台的批处理程序,默默的做一些循环往复的事情。
进程地址空间
引言
我们利用一个全局变量val,看看修改子进程中的变量val,父进程会不会发生变化,他们的地址又是否相同:

因为子进程运行的位置和父进程一样,所以先让父进程睡眠一会,让子进程先修改。

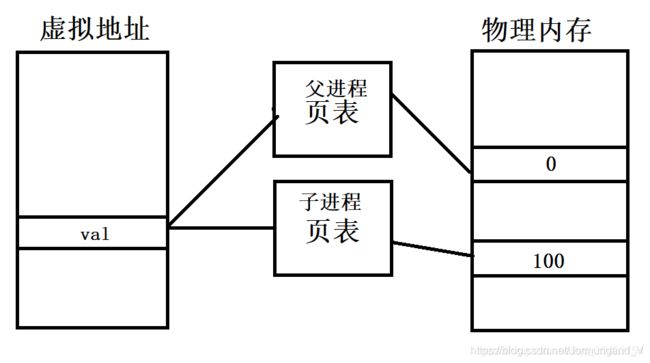
奇怪的事情发生了,明明子进程已经修改了 val ,但是父进程的却没变,同时明明父子进程中全局变量 val 的大小都不一样,但是他们的地址确还是一样的,这就有些不符合逻辑了,因为一个地址中不可能有两个同名的变量。
这里就让我们确定了一件事情,我们在代码中所看到的地址,并不是真正的地址,而是虚拟内存地址。
页表
操作系统再引入虚拟地址空间的时候还引入了一种东西,叫做 页表 。
通过页表来映射虚拟地址和物理地址的关系,不同的进程有不同的页表。上面例子中访问的 val 地址就是 val 在页表的编号,在页表中查找该编号对应的物理内存从而访问 val 数据。
- 通过在虚拟地址来使数据进行连续的存储,然后再通过页表映射到物理内存上,来实现离散式的存储,提高了内存的利用率。
- 同时页表可以针对某个地址设置访问权限,让某个地址设置为只读,通过这种方法来实现内存的访问控制。
- 为了能够使进程具有独立性,彼此之间不会相互干预,每一个进程都会有它自己的页表和虚拟地址空间。
现在我们探讨几个问题:
为什么父子进程的代码相同,且无法修改?
- 因为通过页表将代码段的权限设置为只读,所以无法修改。
为什么父子进程数据各自开辟空间?
- 其实父子进程一开始物理地址和虚拟地址都是相同的,但是当任意一个进程中数据发生变化的时候,这个时候操作系统会找到另外一块物理空间,将数据全部拷贝过去给发生修改的进程使用,并且修改原来的物理空间的权限,使原来的物理空间给另一个进程使用。