详解进程的相关概念(冯诺依曼体系,操作系统,PCB,进程状态,进程创建)--超详细讲解(图文并茂)
文章目录
- 1.冯诺依曼体系结构
- 2.操作系统(Operator System)
-
- 2.1 基本概念
- 2.2 作用
- 2.3 OS相关概念
- 3.进程
-
- 3.1 基本概念
- 3.2 查看进程
- 4.描述进程:PCB(相当于struct结构体)
-
- 4.1 基本概念
- 4.2 内容分类
- 4.3 进程状态
- 4.4 进程创建
-
- 4.4.1 ``getpid()``函数
- 4.4.2 ``getppid()``函数
- 4.4.3 ``fork()``函数
- 5. 僵尸状态、僵尸进程、孤儿进程
-
- 5.1 僵尸状态和僵尸进程
- 5.2 孤儿进程
1.冯诺依曼体系结构
我们日常生活中常见的计算机(笔记本)和不常见的计算机(服务器),大多都遵循冯诺依曼体系结构。

特点
- 计算机处理的数据和指令一律用二进制数表示
- 顺序执行程序
- 计算机硬件由运算器、控制器、存储器、输入设备和输出设备五大部分组成。
下面我再根据自己的理解,再来解释一下冯诺伊曼体系结构中的重要部分
就拿古代皇帝上早朝来举例,主要说功能最重要的三种类别
- CPU扮演的是皇帝,CPU是计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元,它就像皇帝一样,治理着计算机的“天下”
- 存储器扮演的是大臣,它是计算机系统中的记忆设备,它当中存储了程序和各种数据信息的记忆部件,它会将早朝上需要处理的信息,通过"太监"(寄存器)传给"皇上"(CPU)
- 寄存器扮演的是太监,它是CPU(”皇上“)内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果,它负责将存储器或缓存中需要处理的信息传递给CPU(“皇上”)

2.操作系统(Operator System)
2.1 基本概念
任何计算机系统都包含一个基本的程序集合,称为操作系统(OS)。从多个层次来理解的话,OS就是一个软件,软件又是由程序组成的,所以它是一个程序,程序在运行时,又会产生进程,所以,它也可以是一个进程。笼统的理解,操作系统包括:
- 内核(进程管理,内存管理,文件管理,驱动管理)
- 其他程序(例如函数库,shell程序等等)
2.2 作用
作用
- OS负责与硬件进行交互,并管理着所有的软硬件资源
- 为应用程序(用户程序)提供一个良好的执行环境
最主要的作用就是管理。
那么,它是如何进行管理的呢?
- 从程序内部角度来看:
管理 = 描述 + 组织
用C语言的思想来解释的话
- 描述:就是自定义的数据类型,如 struct 结构体
- 组织:通过双向链表的形式来进行相应的存放
2.3 OS相关概念
- 并发:多个进程,在同一时刻只能有一个进程拥有一个CPU进行运算
- 并行:多个进程,在同一时刻拥有不同的CPU进行运算
- 4 核 8 C:总共拥有12个CPU,即4个物理CPU(4核),8个逻辑CPU(8C)。
- 从整个计算机层面来看:
如图所示

系统调用函数和库函数的区别
系统调用函数:OS中专门为程序员提供的函数,程序员可以调用这些函数更好的调用OS管理的计算机资源。(对应Linux中man手册的序号2)
库函数:有心的程序员对部分系统调用函数进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。(对应Linux中man手册的序号3)
3.进程
3.1 基本概念
进程是程序的一个执行实例,正在执行的程序等。但是从内核的角度来看的话,进程就是OS分配系统资源(CPU时间,内存)的实体。因此,可以在内核源代码里找到它。所有运行在系统里的进程都以task_struct链表的形式存在内核里。
程序的概念是经过源代码编译出来的文件,且程序是静态的。而进程是程序在运行状态时产生的一个实例,则进程是动态的。
3.2 查看进程
首先,进程的信息可以通过/proc的系统文件夹查看、
使用
ls /proc/即可查看
若要查看某个进程信息,可以直接 cd 到该文件夹下
并且可以直接 cd 到该文件夹的 fd 文件夹去查看它对应的I/O流
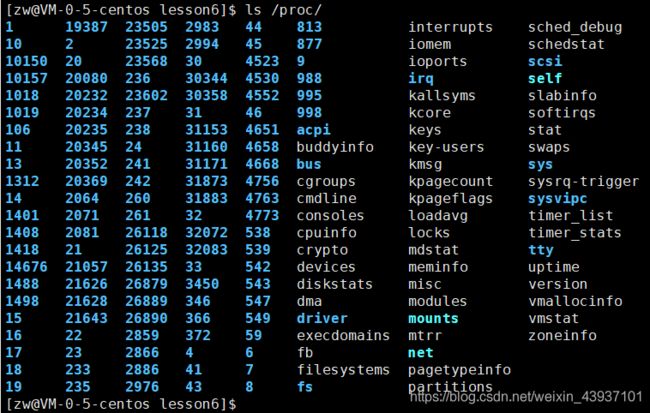

其次,还可以通过使用 top和ps这些用户级工具来获取
首先,先让下面的代码跑起来
再调用ps aux | grep ./test命令,即可查看正在运行的该程序所产生的进程信息


那为什么会产生两行 ./test 的进程信息呢?
- 第一行是正在运行的程序所产生的进程的信息
- 第二行是执行
ps aux | grep ./test操作时,grep查找到后所产生的进程信息,由于在找到的一瞬间就将结果返回了,因此自己查询所产生的进行信息也会被保存下来。(grep在查询完之后就会结束,它会在结束前将结果返回)
4.描述进程:PCB(相当于struct结构体)
4.1 基本概念
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。课本上称之为PCB(process control block),Linux操作系统下的PCB是task_struct。
task_struct是Linux内核的一种数据结构,它是Linux中用来描述进程的结构体,它会被装载到RAM(内存)里并且包含着进程的信息。
4.2 内容分类
- 进程标识符(PID):在OS中唯一标识一个进程,用来区别其他进程。
- 进程状态:用来表示进程的任务状态,退出代码,退出信号等
- 程序计数器: 程序中即将被执行的下一条指令的地址。(相当于记录了程序当前语句所对应的汇编语句的下一条语句)
- 上下文数据: 进程执行时处理器的寄存器中的数据。
- 内存指针: 指向了对应的进程地址空间(堆、栈、代码段等等-)
- I/O状态信息: 保存着当前进程打开文件的信息。
- 记账信息: 记录了使用CPU的时长和占用内存的大小。
- 优先级: 相对于其他进程的优先级。
- 其他信息
4.3 进程状态
从大的方面来说:进程有三个状态:就绪、运行和阻塞状态
从小的方面来讲,共有7种状态
- R状态:运行状态,等待CPU分配资源或者已经获取CPU资源
- S状态:可中断睡眠状态,例如使用Ctrl + c 即可中断该进程
- D状态:不可中断睡眠状态
- T状态:暂停状态,例如使用Ctrl + z即可使进程进入暂停状态,但进程是存在的,不像Ctrl + c 一样,进程直接终止。
- t状态:跟踪状态,是在gdb调试过程中,会产生该状态
- X状态:死亡状态
- Z状态:僵尸状态(本节会在后面将其和僵尸进程,孤儿进程一起讲解)
问题:若在程序运行时按下Ctrl + z 时该如何恢复呢?
解决:首先,我们可以使用jobs命令来查看当前被挂起进程的PID号;然后可以通过使用fg [被挂起进程的PID]来恢复到前台执行、使用bg [被挂起进程的PID]来恢复到后台执行
4.4 进程创建
首先我们要了解3个系统调用函数
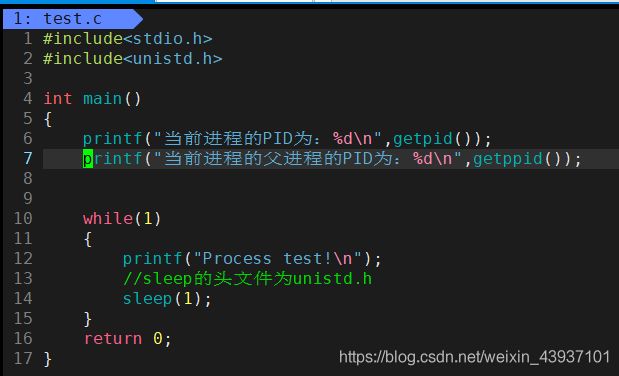
4.4.1 getpid()函数
getpid() 函数:用来获取当前进程的PID,哪个进程调用就获取哪个进程的PID号
4.4.2 getppid()函数
getppid() 函数:获取当前进程的父进程的PID,哪个进程调用就获取该进程的父进程的PID号
首先,我们用代码来测一下这两个函数
代码如下图:
运行如下图:
因为是死循环,所以后面一直运行着
然后再来看看当前可执行程序的进程信息
然后对应得父进程的PID为28132,该PID为BASH(命令行解释器)的进程号


4.4.3 fork()函数
fork() 函数:可以让程序员在代码中创建一个子进程
pid_t fork(void )
- 没有参数
- pid_t:本质是整型
- 返回值含义:若是创建子进程失败,则返回-1,若是创建成功,对于父进程而言,返回 >0 的数,对于子进程而言,返回 == 0 的数
- 原理:fork创建的子进程的PCB于父进程的PCB,是一个独立的PCB(是将父进程的大部分PCB信息拷贝过来,不共用同一地址空间,相当于按值传递)
接着,我们继续看一下 fork 函数的使用
代码如下图:
运行如下图:
然后输入ps -ef | grep ./test,来查看父子进程的PID号
其中,第一列为当前进程的PID号,第二列为对应父进程的PID号。



相信到这里,仔细看代码的大家,肯定都会有疑问:
问题:创建出来的子进程是从frok函数返回值之后的代码开始运行还是从fork函数返回值之前的代码开始运行
解答:首先我们将两种情况都分析一下
- 在fork函数返回值之前运行:若是在fork函数返回值之前运行的话,就意味着程序会一直创建子进程,一直递归的创建子进程,而我们上面的代码测试中发现只产生了一个子进程,因此,推翻这种情况
- 在fork函数返回值之后运行:在之后运行的话,就能说的通了,程序首先创建一个子进程,若创建成功,则父进程获取到的是一个大于0的数,子进程获取到的是一个等于0的数,然后分别走一遍这两个进程对应的代码,根据测试结果显示,显然,这种情况是成立的。
我们已经知道了该问题的答案是在从frok函数返回值之后的代码开始运行,但是具体是为什么呢?我们在细细的向下分解:
- 当程序执行到fork函数的那一行时,遇到fork函数,系统需要创建一个子进程,于是挂起当前进程,去创建该进程的子进程;
- 这时候,PCB中重要的程序计数器就发挥了作用,由于程序计数器中保存的是当前汇编指令的下一条指令;
- 因此,拷贝给子进程的PCB中的程序计数器也保存的是下一条指令,因此,这就避免了子进程一直递归的创建子进程;
- 然后,再继续往下走时,fork函数发现子进程已经创建完毕,则给父进程返回一个大于0的数,给子进程返回一个等于0的数,然后两个进程按照OS内核的调动来交替轮转的执行。
5. 僵尸状态、僵尸进程、孤儿进程
5.1 僵尸状态和僵尸进程
根据上面的内容,我们可知道僵尸状态是用Z来表示的,那么其到底是怎么产生的呢?
僵尸进程的产生:
首先,有个很重要的前提是子进程先于父进程退出,即子进程在退出时,父进程未来得及回收子进程的资源,导致子进程的PCB没有及时地被释放,则该进程就是僵尸进程,该进程对应地状态就是僵尸状态。
但是子进程在退出时,会告知父进程它退出了(这里的告知其实是发送了一个信号),但是发送的该信号,是在所有进程中忽略掉的,不做任何处理的,因此父进程未回收资源,导致僵尸进程的产生
危害:
由于子进程地PCB没有办法得到释放,就会造成内存泄漏
解决:
到这里或许有的人可能认为直接使用以下命令的其中一条即可解决:
kill + PID:来杀死进程kill - q + PID:强制杀死进程
事实上,我们日常大部分情况用以上两种命令即可解决绝大多数情况,但是,僵尸进程是不能用这两句命令来解决的。
真正的解决方法有3种:
- 重启操作系统,这种方法的代价太大,——不推荐
- 杀掉对应的父进程,父进程好好的运行,为什么要突然杀掉呢?这种方式代价也大,——不推荐
- 进程等待,它属于进程控制,我会在后面的文章种讲到它,本文先不做过多的赘述,——推荐
5.2 孤儿进程
孤儿进程的产生:
同僵尸进程一样,它也有对应的前提条件:父进程先于子进程退出,即进程运行种,父进程先于子进程退出,这时候子进程会被1号进程所领养,并且在子进程退出时,就会由1号进程回收子进程的退出资源
1号进程:
OS(操作系统)启动的第一个进程(非常重要的进程),1号进程会产生多个子进程来帮助OS管理计算机资源
重要事项:
- 进程状态中,是没有孤儿状态的,只存在孤儿进程
问题:到底是父进程先运行还是子进程先运行?
解答:不确定,取决于OS内核的调度(即取决于谁先拿到CPU分配的资源)
- 若只有一个CPU时,可能父进程先运行,也可能子进程先运行
- 若有两个CPU时,在上面的情况下,父子进程可能还会同时运行