深入浅出图解CNN-卷积神经网络
首先,介绍一下卷积的来源:它经常用在信号处理中,用于计算信号的延迟累积。假设一个信号发生器每个时刻t产生一个信号xt ,其信息的衰减率为wk ,即在k−1个时间步长后,信息为原来的wk 倍,假设w1 = 1,w2 = 1/2,w3 = 1/4。时刻t收到的信号yt 为当前时刻产生的信息和以前时刻延迟信息的叠加。
然后,介绍卷积诞生思想:在80年代,Fukushima在感受野概念的基础之上提出了神经认知机的概念,可以看作是卷积神经网络的第一个实现网络,神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。
卷积神经网络(Convolutional Neural Networks, CNN)是多层感知机(MLP)的变种。由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来。视觉皮层的细胞存在一个复杂的构造。这些细胞对视觉输入空间的子区域非常敏感,我们称之为感受野,以这种方式平铺覆盖到整个视野区域。这些细胞可以分为两种基本类型,简单细胞和复杂细胞。简单细胞最大程度响应来自感受野范围内的边缘刺激模式。复杂细胞有更大的接受域,它对来自确切位置的刺激具有局部不变性。
通常神经认知机包含两类神经元,即承担特征提取的采样元和抗变形的卷积元,采样元中涉及两个重要参数,即感受野与阈值参数,前者确定输入连接的数目,后者则控制对特征子模式的反应程度。卷积神经网络可以看作是神经认知机的推广形式,神经认知机是卷积神经网络的一种特例。
CNN由纽约大学的Yann LeCun于1998年提出。CNN本质上是一个多层感知机,其成功的原因关键在于它所采用的【稀疏连接】(局部感受)和【权值共享】的方式,一方面减少了的权值的数量使得网络易于优化,另一方面降低了过拟合的风险。
DNN和CNN的区别如下图:左边是一个3层的神经网络。右边是一个卷积神经网络,图例中网络将它的神经元都排列成3个维度(宽、高和深度)。卷积神经网络的每一层都将3D的输入数据变化为神经元3D的激活数据并输出。在这个例子中,红色的输入层装的是图像,所以它的宽度和高度就是图像的宽度和高度,它的深度是3(代表了红、绿、蓝3种颜色通道)。卷积神经网络是由层组成的。每一层都有一个简单的API:用一些含或者不含参数的可导的函数,将输入的3D数据变换为3D的输出数据。

例如:CIFAR-10图像数据分类的卷积神经网络的结构,它的实现细节如下:
1. 输入[32x32x3]存有图像的原始像素值,本例中图像宽高均为32,有3个颜色通道。
2. 卷积层中,神经元与输入层中的一个局部区域相连,每个神经元都计算自己与输入层相连的小区域与自己权重的内积。卷积层会计算所有神经元的输出。如果我们使用12个滤波器(也叫作核),得到的输出数据体的维度就是[32x32x12]。ReLU层将会逐个元素地进行激活函数操作,比如使用以0为阈值的作为激活函数。该层对数据尺寸没有改变,还是[32x32x12]。
3. 汇聚层在在空间维度(宽度和高度)上进行降采样(downsampling)操作,数据尺寸变为[16x16x12]。
4. 全连接层将会计算分类评分,数据尺寸变为[1x1x10],其中10个数字对应的就是CIFAR-10中10个类别的分类评分值。正如其名,全连接层与常规神经网络一样,其中每个神经元都与前一层中所有神经元相连接。
为什么用三维的卷积神经网络来解决二维的图像特征提取问题?
卷积神经网络(Convolutional Neural Network,CNN)是一种具有局部连接、权重共享等特性的深层前馈神经网络。 卷积神经网络最早是主要用来处理图像信息。如果用传统的全连接前馈网络来处 理图像时,会存在以下两个问题:
(1)参数太多:如果输入图像大小为100 × 100 × 3(即图像高度为100,宽度为100,3个颜色通道:RGB)。在全连接前馈网络中,第一个隐藏层的每个神经元到输入层都有100 × 100 × 3 = 30, 000个相互独立的连接,每个连接都对应一个权重参数。随着隐藏层神经元数量的增多,参数的规模也会急剧增加。这会导致整个神经网络的训练效率会非常低,也很容易出现过拟合。
(2)局部不变性特征:自然图像中的物体都具有局部不变性特征,比如在 尺度缩放、平移、旋转等操作不影响其语义信息。而全连接前馈网络很难提取 这些局部不变特征,一般需要进行数据增强来提高性能。 卷积神经网络是受生物学上感受野的机制而提出。感受野(Receptive Field) 主要是指听觉、视觉等神经系统中一些神经元的特性,即神经元只接受其所支 配的刺激区域内的信号。在视觉神经系统中,视觉皮层中的神经细胞的输出依 赖于视网膜上的光感受器。视网膜上的光感受器受刺激兴奋时,将神经冲动信 号传到视觉皮层,但不是所有视觉皮层中的神经元都会接受这些信号。一个神经元的感受野是指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元。
目前的卷积神经网络一般是由卷积层、汇聚层和全连接层交叉堆叠而成的 前馈神经网络,使用反向传播算法进行训练。卷积神经网络有三个结构上的特 性:局部连接,权重共享以及汇聚。这些特性使得卷积神经网络具有一定程度上 的平移、缩放和旋转不变性。和前馈神经网络相比,卷积神经网络的参数更少。 卷积神经网络主要使用在图像和视频分析的各种任务上,比如图像分类、人 脸识别、物体识别、图像分割等,其准确率一般也远远超出了其它的神经网络 模型。
卷积层的作用?
本来就是把输入中的特征分离出来变成新的 feature map,每一个输出通道就是一个卷积操作提取出来的一种特征。在此过程中ReLU激活起到过滤的作用,把负相关的特征点去掉,把正相关的留下。输出的通道数越多就代表分理出来的特征就越多,但也可能存在重复的特征,毕竟是一个概率问题。整体框架:四层处理,卷积提取特征,池化压缩特征。

大家经常见到卷积神经网络中通道数增加的情况,比如227*227*3的彩色图像,经过一层卷积层输出数据尺寸变为55*55*96,通道数增加。这是因为输入数据被96个尺寸为11*11*3,步长为4不同的卷积核进行卷积运算,输入数据每经过一个尺寸为11*11*3,步长为4卷积核,都会产生一个55*55*1的数据,当经过96次卷积运算后,通道数变成了96,通道数变大。
卷积实际是三维的。我们得把这个思想再抬高一个维度。我们现在数据它就不是一列,不是一个向量,不是一个特征,而是一个就是长方体,它是一个长方体的矩阵,它是一个三维的。所以说接下来我们要处理数据,它都是一个三维的,H乘 W 乘上一个 C 的。
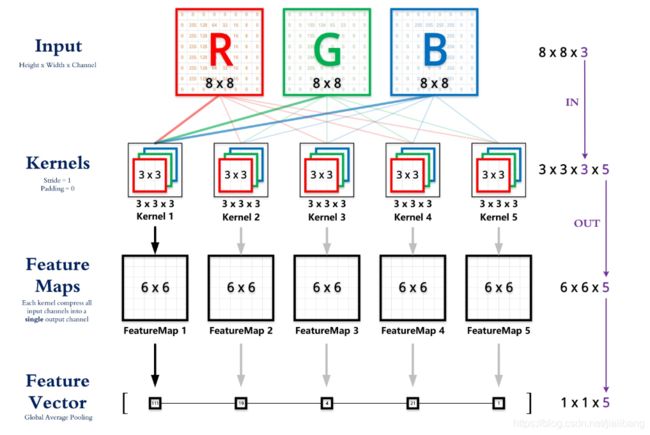
什么叫做一个卷积啊?
卷积是提起特征,池化是压缩特征。CNN的卷积核通道数 = 卷积输入层的通道数;CNN的卷积输出层通道数(深度)= 卷积核的个数
在卷积层的计算中,假设输入是H x W x C, C是输入的深度(即通道数),那么卷积核(滤波器)的通道数需要和输入的通道数相同,所以也为C,假设卷积核的大小为K x K,一个卷积核就为K x K x C,计算时卷积核的对应通道应用于输入的对应通道,这样一个卷积核应用于输入就得到输出的一个通道。假设有P个K x K x C的卷积核,这样每个卷积核应用于输入都会得到一个通道,所以输出有P个通道。
卷积定义用图像讲解:对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。在卷积层中每个神经元连接数据窗的权重是固定的,每个神经元只关注一个特性。神经元就是图像处理中的滤波器,比如边缘检测专用的Sobel滤波器,即卷积层的每个滤波器都会有自己所关注一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集合。
这是最复杂的一个情形,几乎很多实际应用都可以对应到这个问题上, 都是在做这样一件事
1) 输入对应着rgb图片
2)一旦输入的特征图个数是多个,这个时候每一组filter就应该是多个,而这里有两组filter
3)输入是三个特征图,输出为两个特征图,那么我们同样看看每个特征图怎么计算的。
LeNet-5
是一个非常成功的神经网络模型。基于 LeNet-5 的手写数字识别系统在 90 年代被美国很多银行使用,用来识别支票上面的手写数字。LeNet-5 共有 7 层。

输入层:输入图像大小为 32 × 32 = 1024。
C1 层:这一层是卷积层。滤波器的大小是 5×5 = 25,共有 6 个滤波器。得到 6 组大小为 28 × 28 = 784 的特征映射。因此,C1 层的神经元个数为 6 × 784 = 4,704。可训练参数个数为6 × 25 + 6 = 156。连接数为 156 × 784 = 122,304(包括偏置在内,下同)。
S2 层:这一层为子采样层。由 C1 层每组特征映射中的 2 × 2 邻域点次采样为 1 个点,也就是 4 个数的平均。
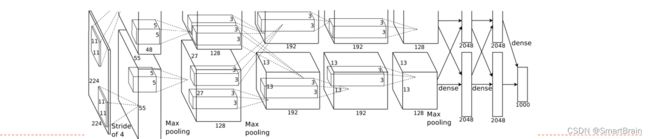
AlexNet
是第一个现代深度卷积网络模型,首次使用了很多现代深度卷积网络的一些技术方法
使用GPU进行并行训练,采用了ReLU作为非线性激活函数,使用Dropout防止过拟合,使用数据增强5个卷积层、3个汇聚层和3个全连接层,具体结果如下:
总结如下:
卷积网络是由卷积层、汇聚层、全连接层交叉堆叠而成。趋向于小卷积、大深度,趋向于全卷积
典型结构如下:

一个卷积块为连续M 个卷积层和b个汇聚层(M通常设置为2 ∼ 5,b为0或1)。一个卷积网络中可以堆叠N 个连续的卷积块,然后在接着K 个全连接层(N 的取值区间比较大,比如1 ∼ 100或者更大;K一般为0 ∼ 2)。