redis学习
redis的数据结构
redis支持五种数据格式:
- string:字符串
- list:列表
- hash:散列表
- set:无序集合
- zset:有序集合
类型 简介 特性 场景
String(字符串) 二进制安全 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M —
Hash(字典) 键值对集合,即编程语言中的Map类型 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) 存储、读取、修改用户属性
List(列表) 链表(双向链表) 增删快,提供了操作某一段元素的API 1、最新消息排行等功能(比如朋友圈的时间线) 2、消息队列
Set(集合) 哈希表实现,元素不重复 1、添加、删除、查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 实现方式: set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
Sorted Set(有序集合) 将Set中的元素增加一个权重参数score,元素按score有序排列 数据插入集合时,已经进行天然排序 1、排行榜 2、带权重的消息队列 实现方式hashmap+跳跃表 HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
string
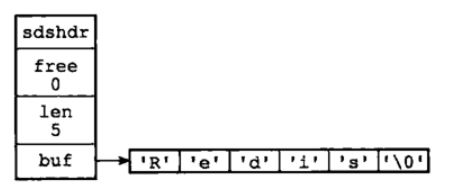
len:保存SDS字符串长度
buf[]:保存字符串每个元素
free:记录了buf数组中未使用字节数量,后续使用
redis 127.0.0.1:6379> SET name "runoob"
"OK"
redis 127.0.0.1:6379> GET name
"runoob"
list
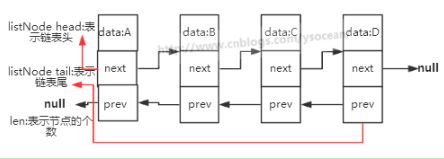
redis的链表特性:
- 双端:链表有前置节点和后置节点作用
- 无环:prev指针和next指针指向NULL,对链表都是以NULL结束
- 计数器:通过len获取时间复杂度
- 多态:使用void指针保存节点值
字典
redis的字典使用hash表作为底层来实现
key用来保存键,val属性用来保存值,值可以是指针,也可以是uint64_t整数,也可以是int64_t整数
解决哈希冲突用的是连地址发,通过next指针指向下一个具有相同索引哈希表节点。
扩容和收缩:哈希表保存的键值太多或者太少,通过rehashd对表进行扩展和收缩,扩展每次扩大一倍,收缩每次缩小一倍
利用哈希算法计算索引,将键值对放到新哈希表位置,所有键值对迁徙完毕后,释放原哈希表内存空间。
渐进式rehash:扩容收缩不是一次性,集中式完成的,而是分多次,渐进式完成的,如保存在redis的键值对几百万个,那么一次性扩容的话会导致其他操作无法进行,删查更新操作可能在two hashTable进行,一个没找到,去第二个找,增加操作一定是在new hashTable进行。

跳跃表
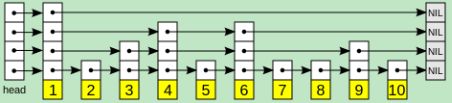
多层每一层都是有序链表,排序由高到底,至少包含head和nil,最底层包含所有元素,下一层一定包含上一层,包含两个指针,一个指向同层下一个链表节点,一个指向下一层同一个链表节点
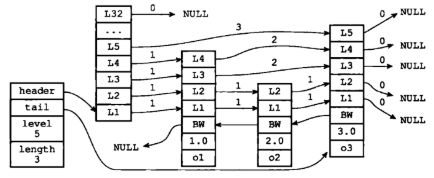
- 搜索:从最高开始,>当前&&<当前层next,往下找,与当前层的下一层下一个节点比较,一直找到底层的最后一个节点,找到就返回,否则返回空。
- 插入:确定插入层数
- 删除:各个层找到包含的节点,节点从链表删除,如果删除后只剩头尾两个节点,就删除这一层。
- 压缩列表:压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。

①、previous_entry_ength:记录压缩列表前一个字节的长度。previous_entry_ength的长度可能是1个字节或者是5个字节,如果上一个节点的长度小于254,则该节点只需要一个字节就可以表示前一个节点的长度了,如果前一个节点的长度大于等于254,则previous length的第一个字节为254,后面用四个字节表示当前节点前一个节点的长度。利用此原理即当前节点位置减去上一个节点的长度即得到上一个节点的起始位置,压缩列表可以从尾部向头部遍历。这么做很有效地减少了内存的浪费。
②、encoding:节点的encoding保存的是节点的content的内容类型以及长度,encoding类型一共有两种,一种字节数组一种是整数,encoding区域长度为1字节、2字节或者5字节长。
③、content:content区域用于保存节点的内容,节点内容类型和长度由encoding决定。
设置过期时间
我们可以在设置键时设置expire time,也可以在运行时给存在的键设置剩余的生存时间,不设置则默认为-1,设置为-1时表示永久存储。
Redis清除过期Key的方式
定期删除+惰性删除
定期删除
Redis设定每隔100ms随机抽取设置了过期时间的key,并对其进行检查,如果已经过期则删除。
为什么是随机抽取? 因为如果存储了大量数据,全部遍历一遍是非常影响性能的!
惰性删除
每次获取key时会对key进行判断是否还存活,如果已经过期了则删除。
Redis内存淘汰机制
maxmemory,内存的最大使用量,到达限度时会执行内存淘汰机制
volatile-lru 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
volatile-lfu 从已设置过期时间的数据集中挑选最不经常使用的数据淘汰
volatile-ttl 从已设置过期时间的数据集中挑选将要过期的数据淘汰
volatile-random 从已设置过期时间的数据集中挑选任意数据淘汰
allkeys-lru 当内存不足写入新数据时淘汰最近最少使用的Key
allkeys-random 当内存不足写入新数据时随机选择key淘汰
allkeys-lfu 当内存不足写入新数据时移除最不经常使用的Key
no-eviction 当内存不足写入新数据时,写入操作会报错,同时不删除数据
Redis的持久化方式,aod和rdb,具体怎么实现,追加日志和备份文件,底层实现原理的话知道么,不清楚。
Redis的list是怎么实现的,我说用ziplist+quicklist实现的,ziplist压缩空间,quicklist实现链表。
sortedset怎么实现的,使用dict+skiplist实现的,问我skiplist的数据结构,大概说了下是个实现简单的快速查询结构。
持久化机制
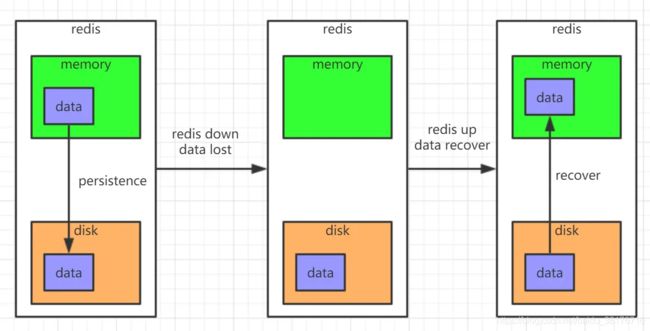
redis是基于内存的数据库,提供了内存数据持久化到文件的两种方式,一种是写RDB文件方式,另一种是写AOF文件,默认执行的是RDB文件持久化方式。
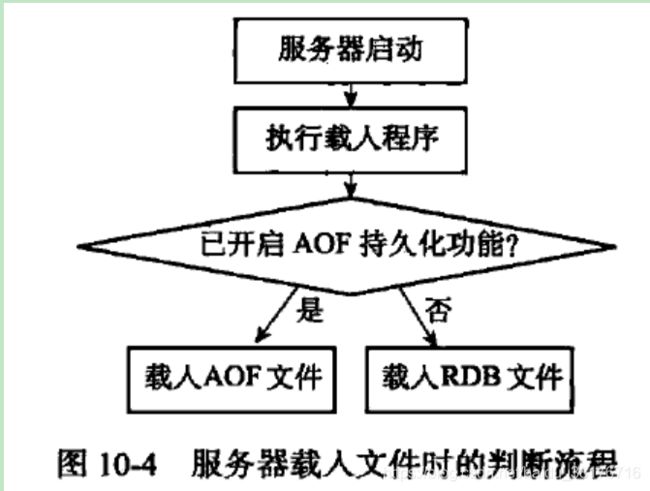
当在redis.config配置文件中开启AOF持久化机制时,redis在启动时,会优先载入AOF文件。其中服务器在载入文件的过程中处于阻塞状态。下图为redis启动时载入持久化文件的流程。
RDB
RDB是一次的全量备份,即周期性的把redis当前内存中的全量数据写入到一个快照文件中。
快照持久化完全交给子进程来处理,父进程继续处理客户端的读写请求。子进程刚刚产生时,和父进程共享内存里面的代码段和数据段,内存中的全量数据由一个个的"数据段页面"组成,每个数据段页面的大小为4K,客户端要修改的数据在哪个页面中,就会复制一份这个页面到内存中,这个复制的过程称为"页面分离"
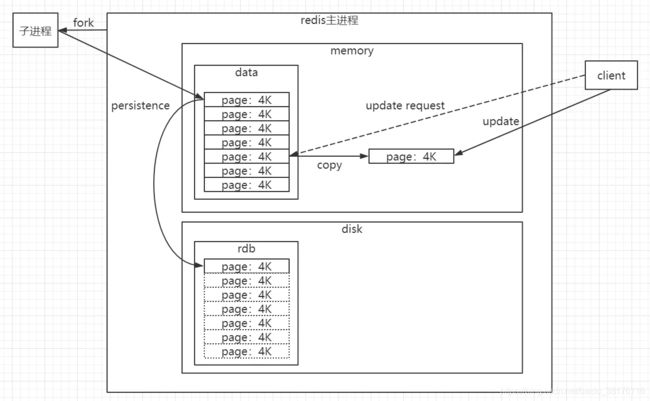
内存快照,在redis中可以设置
save 900 1 (900s内1次redis操作 会做一次持久化)
save 300 10 (300s内10次redis操作 会做一次持久化)
save 60 10000 (60s内10000次redis操作 会做一次持久化)
好处 :性能上要比aof好很多
坏处:可能会存在数据丢失。例如:11:05分 持久化一次,如果redis在11:04死掉,那么这四分钟的
数据,就会丢失
AOF
AOF日志存储的是redis服务器的顺序指令序列,即对内存中数据进行修改的指令记录。当redis收到客户端修改指令后,先进行参数校验,如果校验通过,先把该指令存储到AOF日志文件中,也就是先存到磁盘,然后再执行该修改指令。
当redis宕机后重启后,可以读取该AOF文件中的指令,进行数据恢复,恢复的过程就是把记录的指令再顺序执行一次,这样就可以恢复到宕机之前的状态。
把redis所有的改变(增,删,改)操作,追加到日志文件中。
好处 : 比较安全,即使redis宕机,也可以迅速恢复原来的数据
坏处 : 会影响redis的性能

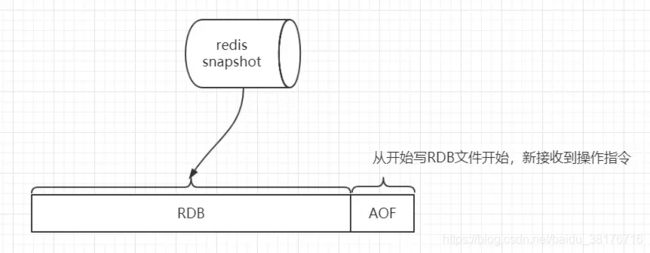
混合持久化
重启redis时,我们很少使用RDB来恢复内存状态,因为会丢失大量数据。我们通常使用AOF日志重放,但是重放AOF日志性能相对RDB来说要慢很多,这样在redis实例很大的情况下,启动需要花费很长的时间。redis-4.0为了解决这个问题,带来了一个新的持久化选项——混合持久化。将RDB文件的内容和增量的AOF日志文件存在一起。这里的AOF日志不再是全量
的日志,而是自持久化开始到持久化结束的这段时间发生的增量AOF日志,通常这部分AOF日志很小。
持久化机制的配置
######################### 通用 #########################
# 持久化文件(包括RDB文件和AOF文件)的存储目录,默认.
dir dir /home/hadoop/data/redis/6379
######################### RDB #########################
# RDB文件的文件名称,默认dump.rdb
dbfilename dump.rdb
# 生成RDB文件的策略,默认为以下3种,意思是:
# 每隔60s(1min),如果有超过10000个key发生了变化,就写一份新的RDB文件
# 每隔300s(5min),如果有超过10个key发生了变化,就写一份新的RDB文件
# 每隔900s(15min),如果有超过1个key发生了变化,就写一份新的RDB文件
# 配置多种策略可以同时生效,无论满足哪一种条件都会写一份新的RDB文件
save 900 1
save 300 10
save 60 10000
# 是否开启RDB文件压缩,该功能可以节约磁盘空间,默认为yes
rdbcompression yes
# 在写入文件和读取文件时是否开启rdb文件检查,检查是否有无损坏
# 如果在启动时检查发现文件损坏,则停止启动,默认yes
rdbchecksum yes
######################### AOF #########################
# 是否开启AOF机制,默认为no
appendonly yes
# AOF文件的名称,默认为appendonly.aof
appendfilename "appendonly.aof"
# fsync的策略,默认为everysec
# everysec:每秒fsync一次
# no:redis不主动fsync,完全交由操作系统决定
# always:1条指令fsync一次
appendfsync everysec
# AOF文件rewrite策略
# 当上一次重写后的AOF文件的增长比例达到100%
# 比如上一次重写AOF文件后,新文件大小为128M
# 当新文件再次增长了100%,达到了256M
# 并且增长了100%后的文件的大小大于64M,那么开始重写AOF文件
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 是否加载破损的AOF文件,默认为yes,如果设置为no
# 那么redis启动时如果发现AOF文件破损,就会报错并且拒绝启动redis服务。
aof-load-truncated yes
######################### 混合持久化 #########################
# 是否开启混合持久化机制,默认为no
aof-use-rdb-preamble no
事务
分布式锁
什么是分布式锁?
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。
实现分布式锁有很多实现方式和工具,如Zookeeper、Redis等。基本原理是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
解决死锁
如果一个持有锁的客户端失败或崩溃了不能释放锁,该怎么解决?
答:给锁设置一个过期时间,可以通过两种方法实现:通过命令 “setnx 键名 过期时间 “;或者通过设置锁的expire时间,让Redis去删除锁。
事务
并发竞争Key问题
- 第一种方案:分布式锁+时间戳
1.整体技术方案
这种情况,主要是准备一个分布式锁,大家去抢锁,抢到锁就做set操作。
加锁的目的实际上就是把并行读写改成串行读写的方式,从而来避免资源竞争。
2.Redis分布式锁的实现
主要用到的redis函数是setnx()
用SETNX实现分布式锁
利用SETNX非常简单地实现分布式锁。例如:某客户端要获得一个名字youzhi的锁,客户端使用下面的命令进行获取:
SETNX lock.youzhi
如返回1,则该客户端获得锁,把lock.youzhi的键值设置为时间值表示该键已被锁定,该客户端最后可以通过DEL lock.foo来释放该锁。
如返回0,表明该锁已被其他客户端取得,这时我们可以先返回或进行重试等对方完成或等待锁超时。
由于上面举的例子,要求key的操作需要顺序执行,所以需要保存一个时间戳判断set顺序。
系统A key 1 {ValueA 7:00}
系统B key 1 { ValueB 7:05}
- 消息队列
redis常见问题
redis集群模式