C语言(数据结构与算法)
目录
一、时间复杂度与空间复杂度
1.时间复杂度
2.空间复杂度
二、顺序表和链表(线性表)
1.顺序表-顺序表功能实现
2.链表-链表功能实现
3.双向链表-双向链表功能实现
三、栈和队列
1.栈-栈功能实现
2.队列-队列功能实现
四、二叉树
1.二叉树-初阶二叉树功能实现
二叉树数组的顺序存储特点:
五、查找算法\排序算法---java版
https://blog.csdn.net/qq_39888626/article/details/120452952
(不懂的知识点或者有bug可私聊,请指教)
数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的 集合。
算法(Algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为输出。简单 来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果。
一、时间复杂度与空间复杂度
1.时间复杂度
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一 个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知 道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个 分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法 的时间复杂度。
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N ; ++ i)
{
for (int j = 0; j < N ; ++ j)
{
++count;
}
}
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}以上代码Func1的执行次数为第一个for循环嵌套for循环就是N*N就是N^2再加for循环2*N次再加10次
:F(N)=N^2+2*N+10。
如果N=10 F(N)=130 如果N=100 F(N)=10210 如果N=1000 F(N)=1002010
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这 里我们使用大O的渐进表示法
推导大O阶的方法:
1.用常数1代取运行时间中的所有加法常数
2.再修改后的运行次数函数中,只保留次数最多的阶项(次数最多的一项)
3.如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶
使用大O的渐进表示法以后,Func1的时间复杂度为:O(N^2)
因N^2是此项目里执行次数最多的一项
2.空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度 (临时变量的个数)。空间复杂度不是程序占用了多少 bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。空间复杂度计算规则基本跟实践 复杂度类似,也使用大O渐进表示法。
实例1
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
实例2
long long* Fibonacci(size_t n)
{
if(n==0)
return NULL;
long long * fibArray = (long long *)malloc((n+1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;for (int i = 2; i <= n ; ++i)
{
fibArray[i ] = fibArray[ i - 1] + fibArray [i - 2];
}
return fibArray ;
}1. 实例1使用了常数个额外空间,所以空间复杂度为 O(1)
2. 实例2动态开辟了N个空间,空间复杂度为 O(N)
二、顺序表和链表(线性表)
线性表(linear list)是n个具有相同特性的数据元素的有限序列。
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物 理上存储时,通常以数组和链式结构的形式存储。
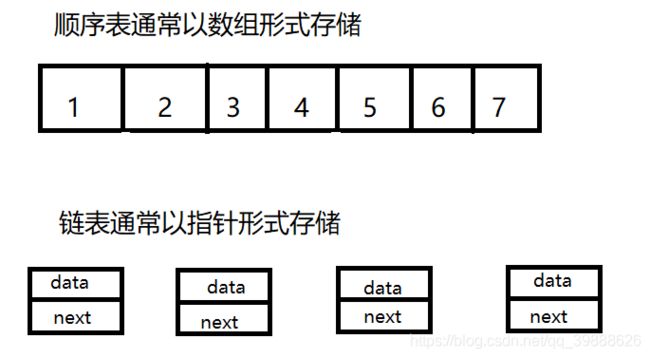
1.顺序表-顺序表功能实现
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组 上完成数据的增删查改。
头文件
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include
#include
#include
#include
#define MAX 100//定义顺序表的容量大小
#define ElemType int//定义顺序表的类型
//顺序表的结构体实现
typedef struct SqList
{
ElemType data[MAX];///顺序表的数组元素
int capacity;//顺序表的有效长度
}SqList;
void SqListInit(SqList* con);//初始化顺序表
void SqListPushBack(SqList* con, ElemType val);//尾插
void SqListPopBack(SqList* con);//尾删
void SqListPushFront(SqList* con,ElemType val);//头插
void SqListPopFront(SqList* con);//头删
void SqListInsert();//指定位置插入
void SqListDelete();//删除元素
void SqListFind();//查找元素
void SqListFind();//修改元素
void SqListShow(SqList* con);//显示所有元素 函数实现
void SqListInit(SqList* con)
{
for (int i = 0; i < MAX; i++)
{
con->data[i] = 0;//将所有元素初始化为0
}
con->capacity = 0;//长度初始化为0
}
void SqListPushBack(SqList* con,ElemType val)
{
if (con->capacity == MAX)//判断顺序表是否为满
{
printf("该顺序表已满\n");
return;
}
con->data[con->capacity++] = val;//将下标为capacity的元素复制为val然后capacity加1
}
void SqListPopBack(SqList* con)
{
if (con->capacity == 0)//判断顺序表是否为空
{
printf("该顺序表为空\n");
return;
}
con->capacity--;//长度个数减1完成逻辑上的删除
}
void SqListPushFront(SqList* con,ElemType val)
{
if (con->capacity == MAX)//判断顺序表是否为满
{
printf("该顺序表已满\n");
return;
}
int num = con->capacity;
while (num)//将所有元素后移
{
con->data[num] = con->data[num-1];
num--;
}
con->data[0] = val;//在第一个元素赋值val
con->capacity++;//长度加1
}
void SqListPopFront(SqList* con)
{
if (con->capacity == 0)//判断顺序表是否为空
{
printf("该顺序表为空\n");
return;
}
for (int i = 0; i < con->capacity - 2; i++)//将所有元素往前移
{
con->data[i] = con->data[i + 1];
}
con->capacity--;
}
void SqListInsert(SqList* con,ElemType val,int pos)
{
if (con->capacity == MAX)//判断顺序表是否为满
{
printf("该顺序表已满\n");
return;
}
if (pos<1 || pos>con->capacity + 1)//判断指定位置是否有效
{
printf("位置无效\n");
return;
}
for (int i = con->capacity; i >= pos; i--)
{
con->data[i] = con->data[i - 1];
}
con->data[pos - 1] = val;
con->capacity++;
}
void SqListDelete(SqList* con,ElemType val)
{
if (con->capacity == 0)//判断顺序表是否为空
{
printf("该顺序表为空\n");
return;
}
int num = -1;
for (int i = 0; i < con->capacity; i++)
{
if (con->data[i] == val)
num = i;
}
if (num != -1)//说明找到元素了
{
for (int i = num; i < con->capacity - i; i++)
{
con->data[i] = con->data[i + 1];
}
con->capacity--;
}
else
{
printf("未找到元素\n");
return;
}
}
void SqListFind(SqList* con,int val)
{
if (val > con->capacity)//判断指定位置有效性
{
printf("未找到元素\n");
return;
}
printf("%d ", con->data[val-1]);
}
void SqListShow(SqList* con)
{
if (con->capacity == 0)//判断顺序表中是否为空
{
printf("该顺序表为空\n");
return;
}
for (int i = 0; i < con->capacity; i++)
{
printf("%d ", con->data[i]);
}
printf("\n");
}2.链表-链表功能实现
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链 接次序实现的 。
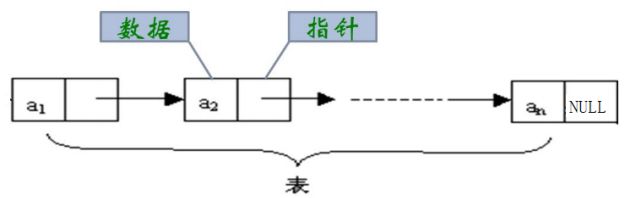
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:1. 单向、双向 2. 带头、不带头 3. 循环、非循环
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
1.无头单向不循环链表
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结 构,如哈希桶、图的邻接表等等。
2.带头双向循环链表
带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向 循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而 简单了。
无头单向不循环链表实现:
函数声明文件:头文件:
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include
#include
#include
#include
typedef int SListDataType;
typedef struct SListNode
{
SListDataType data;//链表结点的元素
struct SListNode* next;//指向下个结点的指针
}SListNode;
void SListPushBack(SListNode** plist,SListDataType x);//尾插
void SListPopBack(SListNode** plist);//尾删
void SListPushFront(SListNode** plist, SListDataType x);//头插
void SListPopFront(SListNode** plist);//头删
SListNode* SListFind(SListNode* plist,SListDataType x);//查找
void SListPrint(SListNode* plist);//打印
void SListInsertAfter(SListNode* pos, SListDataType x);//任意位置位置插入数据
void SListDelAfter(SListNode* pos);//任意位置删除数据
SListNode* removeElements(SListNode* head, int val);//删除链表中为val的元素 函数实现代码:
SListNode* BuySListNode(SListDataType x)//创建新结点
{
SListNode*newNode = (SListNode*)malloc(sizeof(SListNode));
if (newNode == NULL)
{
printf("Create error");
return 0;
}
newNode->data = x;
newNode->next = NULL;
return newNode;
}
void SListPrint(SListNode* plist)//打印链表所有结点
{
SListNode* cur = plist;//新指针指向链表防止改变链表
while (cur != NULL)//便利链表
{
printf("%d->", cur->data);//打印结点的元素
cur = cur->next;//让链表迭代:访问完此结点指向下个结点
}
printf("NULL\n");//换行
}
void SListPushBack(SListNode** plist,SListDataType x)//尾插
{
SListNode*newNode = BuySListNode(x);//先创建一个新结点用指针newNode来维护
if (*plist == NULL)//判断该链表是否为空
{
*plist = newNode;//如果链表没有元素就指向新结点
}
else//如果链表有元素则先便利元素然后再用最后一个结点的next指向新结点
{
SListNode *cur = *plist;
while (cur->next != NULL)
{
cur = cur->next;
}
cur->next = newNode;
}
}
void SListPopBack(SListNode** plist)//尾删
{
if (*plist == NULL)//判断链表是否为空
{
return;
}
else if ((*plist)->next == NULL)//如果不为空先释放且只有一个结点则释放该结点
{
free(*plist);
*plist = NULL;
}
else//如果有多个结点则保留尾结点的上个结点用prev来维护
{
SListNode* prev = NULL;
SListNode* tail = *plist;
while (tail->next != NULL)
{
prev = tail;//存储该结点的上个结点
tail = tail->next;//是尾结点
}
free(tail);//释放尾结点防止内存泄漏
prev->next = NULL;//将尾结点的上个指针指向空则删除成功
}
}
void SListPushFront(SListNode** plist, SListDataType x)//头插
{
SListNode* Front = BuySListNode(x);//老规矩创建新节点
Front->next = *plist;//新结点的next指向该链表则完成链接
*plist = Front;//然后该链表的头变为新结点
}
void SListPopFront(SListNode** plist)//头删
{
if (*plist == NULL)//判断链表是否为空
{
return;
}
SListNode* Front = *plist;//存储第一个结点
*plist = (*plist)->next;//把链表的新头指向原头的next则完成头删
free(Front);//释放第一个结点
}
SListNode* SListFind(SListNode* plist, SListDataType x)//查找元素
{
SListNode* cur = plist;//老规矩便利链表
while (cur)
{
if (cur->data == x)//如果找到元素则返回该元素的结点
return cur;
cur = cur->next;//执行链表迭代
}
return cur->next;//如果没找到则返回最后元素的next
}
void SListInsertAfter(SListNode* pos, SListDataType x)//任意位置插入元素
{
assert(pos);//判断该结点有效性
SListNode*new = BuySListNode(x);//创建新结点
new->next = pos->next;//新结点的next指向要插入结点的下一个结点
pos->next = new;//要插入结点的next指向新结点则完成插入
}
void SListDelAfter(SListNode* pos)//删除指定结点的下一个结点
{
assert(pos);//判断要删除的结点有效性
if (pos->next)//判断下一个结点是否为空
{
SListNode* cur = pos->next;//将要删除结点的下一个结点用cur来维护
//SListNode* after = cur->next;
pos->next = cur->next;//cur->next是pos的下下个结点//删除的结点指向下下个结点
free(cur);//释放要删除结点的下一个则完成删除
}
}
SListNode* removeElements(SListNode* head, int val)//删除链表为val元素的结点
{
if (head == NULL)//判断头结点是否为空
return NULL;
SListNode* cur = head;//用来存放头结点
SListNode* prev = NULL;//存放结点的上个结点
SListNode* next = NULL;//存放结点的下个结点
while (cur->next)//便利链表
{
prev = cur;
next = cur;
if (prev->next->data == val)//如果找到目标了
{
prev->next = cur->next->next;//将目标上个结点的next指向下下个结点则完成删除
}
else
cur = cur->next;//迭代
}
if (head->data == val)//如果头结点的元素==val表示只有一个元素删除后则返回空
return NULL;
return head;//返回头结点
}3.双向链表-双向链表功能实现
双向链表的实现:写起来比较难,逻辑非常非常简单:
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include
#include
#include
#include
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;//结点中的元素
struct ListNode* next;//指向下个结点的指针
struct ListNode* prev;//指向上个结点的指针
}ListNode;
ListNode* Create();//创建头结点
ListNode* BuyListNode(LTDataType x);//创建结点
void ListNodePushBack(ListNode* head,LTDataType x);//尾插
void ListNodePopBack(ListNode* head);//尾删
void ListNodePushFront(ListNode* head, LTDataType x);//头插
void ListNodePopFront(ListNode* head);//头删
ListNode* ListNodeFind(ListNode*head, LTDataType x);//查找
void ListNodeInsert(ListNode*pos, LTDataType x);//指定位置插入
void ListNodeErase(ListNode*pos);//指定位置删除
void ListNodePrint(ListNode* head);//打印
void ListNodeClear(ListNode*head);//清理数据
void ListNodeDestory(ListNode*head);//销毁链表 函数实现:
ListNode* BuyListNode(LTDataType x)//创建新结点的函数同单链表相似
{
ListNode* head = (ListNode*)malloc(sizeof(ListNode));
if (head == NULL)
{
printf("%s ", strerror(errno));
return NULL;
}
head->data = x;
head->next = NULL;
head->prev = NULL;
return head;
}
ListNode* Create()//创建头结点
{
ListNode*head = BuyListNode(0);//创建新结点
head->next = head;//头结点的下一个指向头实现循环
head->prev = head;//头结点的上一个指向头实现循环
return head;
}
void ListNodePrint(ListNode* head)//打印链表
{
assert(head);//判断链表有效性
ListNode*cur = head->next;
while (cur != head)//老规矩便利注意只从头结点的下一个第一个结点开始便利到最后一个因为最后一个结点的next是指向头结点的所以是cur!=head
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
void ListNodePushBack(ListNode* head, LTDataType x)//尾插
{
assert(head);//判断链表有效性
ListNodeInsert(head, x);//用任意位置插入函数来实现尾插 第一次学习双向链表的小伙伴可以忽略这行代码
//ListNode*tail = head->prev;//将头结点的上个用tail来维护tail是尾的意思头结点的上一个结点就是尾结点
//ListNode* newnode = BuyListNode(x);//创建新结点
//tail->next = newnode;//用尾结点的next指向新结点
//newnode->prev = tail;//新尾结点的上个结点指针指向原尾结点
//newnode->next = head;//新尾结点的下一个指向头
//head->prev = newnode;头的上一个指向新结点
}
void ListNodePopBack(ListNode* head)//尾删
{
assert(head);//判断链表的有效性
assert(head->next != head);//判断链表除头结点外有无元素 头结点无法删除!
//ListNode* tail = head->prev;//将尾结点存起来
//ListNode* tailprev = tail->prev;//尾结点的上个结点存起来
//head->prev = tailprev;//头结点的下一个指向尾结点的上个结点
//tailprev->next = head;尾结点的上个结点的next指向头
//free(tail);//释放尾结点则完成删除
ListNodeErase(head->prev);//用任意位置删除元素函数来尾删 第一次学习的小伙伴可忽略这行代码
}
void ListNodePushFront(ListNode* head, LTDataType x)//头插
{
assert(head);//判断链表有效性
ListNodeInsert(head->next,x);//用任意位置插入元素函数来头插 第一次学习的小伙伴可忽略这行代码
//ListNode* newnode = BuyListNode(x);//创建新结点
//ListNode*cur = head->next;//存放第一个结点
//head->next = newnode;//第一个结点变为新结点
//newnode->prev = head;//新结点的上个结点指向头
//newnode->next = cur;//新结点的下个结点指向原第一个结点
//cur->prev = newnode;//原第一个结点的上一个指向新第一个结点
}
void ListNodePopFront(ListNode* head)//头删
{
assert(head);//判断链表有效性
assert(head->next != head);//判断链表是否只有头结点 头结点无法删除!
//ListNode*cur = head->next;//将第一个结点存起来
//ListNode*curnext = cur->next;//将第二个结点存起来
//head->next = curnext;//新第一个结点指向原第二个结点
//curnext->prev = head;//原第二个的上一个指向头变为新第一个结点
//free(cur);//释放原第一个结点
ListNodeErase(head->next);//用任意位置删除元素函数来头删 第一次学习的小伙伴可忽略这行代码
}
ListNode* ListNodeFind(ListNode*head, LTDataType x)//查找元素
{
assert(head);//判断链表有效性
ListNode*cur = head->next;
while (cur != head)//便利链表
{
if (cur->data == x)//如果找到了返回该结点
return cur;
cur = cur->next;
}
printf("未找到结点");
return NULL;
}
void ListNodeInsert(ListNode*pos, LTDataType x)//任意位置插入
{
assert(pos);//判断链表有效性
ListNode*curprev = pos->prev;//存贮指定结点的上一个
ListNode*newnode = BuyListNode(x);//创建新结点
curprev->next = newnode;//指定结点的上一个的next指向新结点
newnode->prev = curprev;//新结点的上一个指向指定结点的上一个
newnode->next = pos;//新结点的下一个指向指定结点
pos->prev = newnode;//指定结点的上一个指向新结点 则插入成功
}
void ListNodeErase(ListNode*pos)//指定位置删除
{
assert(pos);//判断链表有效性
ListNode*curprev = pos->prev;//用curprev来维护指定结点的上一个结点
ListNode*curnext = pos->next;//用curnext来维护指定节点的下一个结点
curprev->next = curnext;//指定结点的next指向指定节点的下一个结点
curnext->prev = curprev;//指定结点的prev指向指定结点的上一个结点
free(pos);//释放指定结点则删除完成
}
void ListNodeClear(ListNode*head)//清空链表
{
assert(head);//判断链表有效性
if (head->next == head)//判断是否只有头结点
exit(0);
ListNode*cur = head->next;
while (cur != head)//便利链表进行释放空间
{
ListNode*next = cur->next;
free(cur);
cur = next;
}
head->next = head;//将头的下一个结点指向头实现循环
head->prev = head;//将头的上一个指向头实现循环
}
void ListNodeDestory(ListNode*head)//销毁链表
{
assert(head);//判断链表有效性
ListNodeClear(head);//清空链表
free(head);//释放头结点
}三、栈和队列
1.栈-栈功能实现
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈,出数据在栈顶。


的静态栈的结构,实际中一般不实用,所以我们主要实现下面的支持动态增长的栈
函数声明:
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include
#include
#include
#include
#define MaxSize 4//初始化大小
typedef int STDataType;
typedef struct Stack
{
STDataType *data;//动态数组
STDataType *top;//指针指向栈顶
int StackSize;//栈的长度
}Stack;
void StackInit(Stack* con);//栈初始化
bool StackEmpty(Stack* con);//判断栈是否为空
int StackLength(Stack* con);//计算栈的大小
void StackPush(Stack* con, STDataType x);//入栈
STDataType StackPop(Stack* con);//出栈
void StackClear(Stack* con);//清空栈
void StackDel(Stack* con);//销毁栈 函数实现:
void StackInit(Stack* con)//初始化栈
{
con->data = (STDataType*)malloc(sizeof(STDataType)*MaxSize);//创建初始化大小的数组
if (con->data == NULL)//判断创建是否成功
{
printf("%s ", strerror(errno));
exit(0);
}
con->top = con->data;//栈顶指向栈底表示还没有元素
con->StackSize = MaxSize;//长度初始化
}
bool StackEmpty(Stack* con)//判断栈是否为空
{
if (con->data == con->top)//如果栈顶指向栈底说明没有元素
return true;//返回真
else
return false;
}
int StackLength(Stack* con)//栈的长度
{
return con->top - con->data;//用指针来相减 栈顶指针减去栈底指针结果就是中间有多少个元素
}
void StackPush(Stack* con, STDataType x)//入栈\压栈
{
if (con->top - con->data == con->StackSize)//判断栈顶到栈底的元素如果等于长度说明栈满 则执行扩容操作
{
STDataType* ptr = (STDataType*)realloc(con->data, sizeof(STDataType)*(con->StackSize + 2));//重新指定一个原有数组的长度+2个数组
if (ptr == NULL)
{
printf("%s ", strerror(errno));
return;
}
con->data = ptr;//复制数据
con->StackSize += 2;//长度+2
}
*con->top++ = x;//解引用栈顶找到栈顶的空间放入元素栈顶++则完成入栈
}
STDataType StackPop(Stack* con)//出栈 返回值用元素类型来接受弹出的元素
{
assert(con);//判断栈有效性
con->top--;//栈顶向下移动
return *(con->top);//返回下移后的元素 返回后该位置变为栈顶则弹出成功
}
void StackClear(Stack* con)//清空栈
{
assert(con);//判断有效性
con->top = con->data;//将栈顶指向栈底完成逻辑上的删除则完成清空
}
void StackDel(Stack* con)//销毁栈
{
assert(con);//判断栈有效性
free(con->data);//释放栈的数组空间
con->StackSize = 0;//将长度设为0
con->top = con->data = NULL;//将栈的栈顶指针和数组置空
}2.队列-队列功能实现
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出 FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾 出队列:进行删除操作的一端称为队头
队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列在数 组头上出数据,效率会比较低。
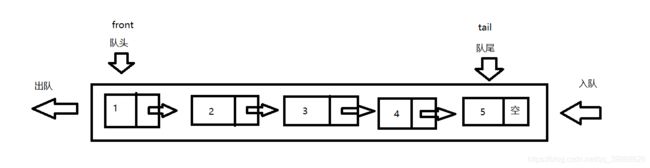
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include
#include
#include
#include
typedef int ElemType;
typedef struct Queue//创建单个队列结点
{
ElemType data;//结点的元素
struct Queue* next;//指向下个结点的指针
}Queue;
typedef struct LinkQueue//队列的头尾指针
{
Queue* front;//队头指针
Queue* tail;//队尾指针
}LinkQueue;
void QueueInit(LinkQueue* obj);//初始化队列
bool QueueEmpty(LinkQueue* obj);//判断队列是否为空
void QueuePush(LinkQueue* obj,ElemType x);//入队列
ElemType QueuePop(LinkQueue* obj);//出队列
ElemType QueueFront(LinkQueue* obj);//获取队头元素
void QueuePrint(LinkQueue* obj);//打印队列
void QueueFree(LinkQueue* obj);//销毁队列 void QueueInit(LinkQueue* obj)//初始化队列
{
obj->front = (Queue*)malloc(sizeof(Queue));//创建单个结点用队头维护
obj->tail = obj->front;//初始化没有元素所以队尾=队头
obj->front->next = NULL;//队头结点的next指向空
}
bool QueueEmpty(LinkQueue* obj)//判断队列是否为空
{
return (obj->front == obj->tail);
}
void QueuePush(LinkQueue* obj, ElemType x)//入队列
{
assert(obj);//判断队列有效性
Queue* con = (Queue*)malloc(sizeof(Queue));//创建一个新结点
con->data = x;//新结点的元素赋值x
con->next = NULL;
obj->tail->next = con;//队尾的next指向新结点
obj->tail = con;//新结点变成新的队尾
}
ElemType QueuePop(LinkQueue* obj)//出队列
{
if (QueueEmpty(obj))
{
printf("队列为空\n");
return -1;
}
Queue* cur = obj->front->next;//存第一个结点
ElemType x = cur->data;//存储队头结点的元素准备返回
obj->front->next = cur->next;//队头指向第二个结点
if (cur->next == NULL)//判断队列是否只有一个结点 特殊处理
{
obj->tail = obj->front;
}
free(cur);
return x;
}
ElemType QueueFront(LinkQueue* obj)//获取队头元素
{
QueuePop(obj);
}
void QueuePrint(LinkQueue* obj)//打印队列
{
if (QueueEmpty(obj))//判断队列是否为空
{
printf("队列为空\n");
return;
}
Queue* cur = obj->front->next;//存队列的第一个结点
while (cur)
{
printf("%d ", cur->data);
cur = cur->next;
}
}
void QueueFree(LinkQueue* obj)//销毁队列
{
while (obj->front)//遍历队列
{
obj->tail = obj->front->next;//队尾指向下个结点
free(obj->front);
obj->front = obj->tail;//队头迭代
}
}另外扩展了解一下,实际中我们有时还会使用一种队列叫循环队列。
环形队列可以使用数组实现,也可以使用循环链表实现。
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include
#include
#include
#include
#include
#include
#define MAX 10
typedef int ElemType;
typedef struct Queue
{
ElemType* data;//队列的元素数组
int front;//队头
int tail;//队尾
int capacity;//队列的
int size;//队列的元素个数
}Queue;
Queue* QueueInit(int size)//初始化队列返回队列的指针
{
Queue* obj = (Queue *)malloc(sizeof(Queue));//创建一个队列结构体用指针obj来维护
if (obj == NULL)
{
printf("%s", strerror(errno));//判断创建是否成功
return NULL;
}
obj->data = (ElemType*)malloc(sizeof(ElemType)*size);//创建指定大小的数组
if (obj->data == NULL)
{
printf("%s", strerror(errno));//判断创建是否成功
return NULL;
}
obj->front = 0;//队头下标设为0
obj->tail = 0;//队尾下标设为0
obj->size = 0;//元素个数设为0
obj->capacity = size;//容量设为指定大小
return obj;
}
bool QueueEmpty(Queue* obj)//判断队列是否为空
{
return (obj->size == 0);//判断长度是否为0 为0标识无元素为空
}
bool QueueFull(Queue* obj)//判断队列是否为满
{
return (obj->size == obj->capacity);//判断队列的元素个数等于容量 满了就是相等的
}
void QueuePush(Queue* obj, ElemType x)//入队列
{
if (QueueFull(obj))//判断队列是否已满
{
return;
}
obj->front %= obj->capacity;//队头模容量 假设有4个容量队头为0 0%4为0 入队列在0号下标 如果头为1 1%4得1入队列在1号下标 如果头为4 4%4为0 入队列回到0下标 实现循环队列
obj->data[obj->front] = x;//下标为头的元素赋值x
obj->front++;//队头迭代
obj->size++;//元素个数增加
}
void QueuePop(Queue* obj)//出队列
{
if (QueueEmpty(obj))
{
return;//判断队列是否为空
}
obj->tail = (++obj->tail) % (obj->capacity);//队尾模容量同队头模容量同理
obj->size--;//队列元素个数减1
}
ElemType QueueFront(Queue* obj)//获取队头元素
{
if (QueueEmpty(obj))
{
return -1;//判断队列是否为空
}
return obj->data[obj->front];
}
ElemType QueueTail(Queue* obj)//获取队尾元素
{
if (QueueEmpty(obj))
{
return -1;//判断队列是否为空
}
return obj->data[(obj->tail) - 1];
}
void QueueFree(Queue* obj)
{
free(obj->data);//先销毁队列的数组元素
free(obj);//销毁队列
} 四、二叉树
1.二叉树-初阶二叉树功能实现
树是一种非线性的数据结构,它是由n(n不小于0)个有限结点组成一个具有层次关系的集合
把它叫做树是因 为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的
有一个特殊的结点,称为根结点,根节点没有前驱结点 除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继 因此,树是递归定义的。

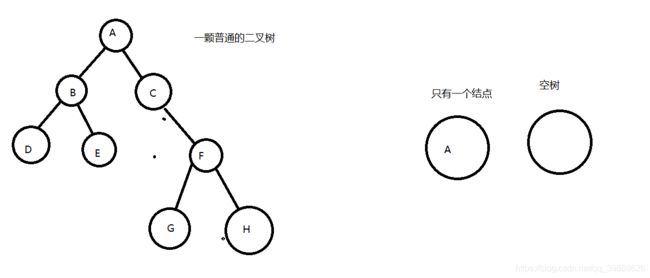
节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的为6
叶节点或终端节点:度为0的节点称为叶节点; 如上图:B、C、H、I...等节点为叶节点
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林;
没有父结点的结点成为根结点下图的A结点就是此树的根节点

每个结点又可以看作一个树就是树的子树下图BDE就是一颗子树
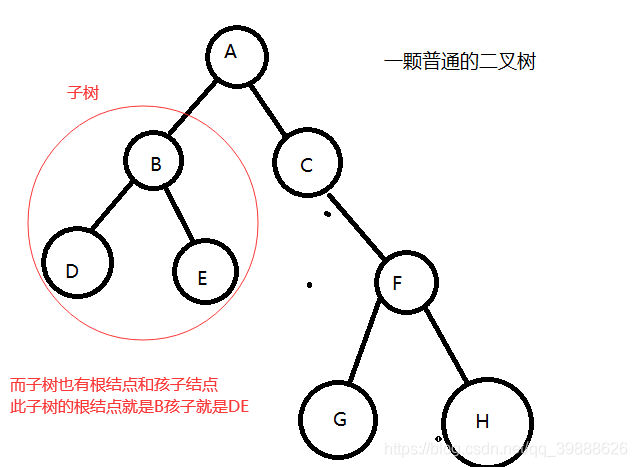
注意:子树是不相交的,除了跟结点外,每个结点有且仅有一个父结点否则不叫二叉树
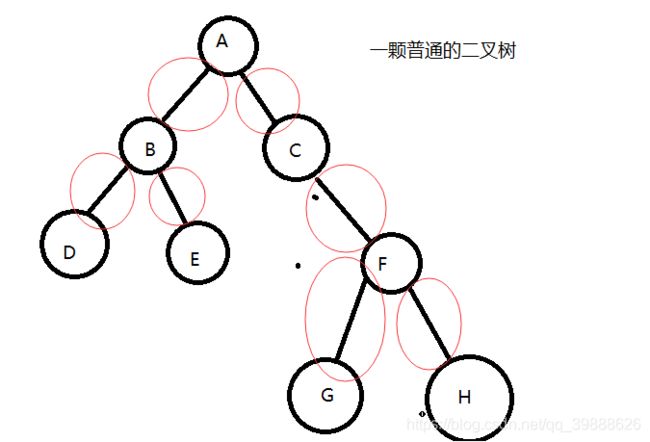
一棵N个结点的树有N-1条边下图红圈内就是树的边。
一棵二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根节点加上两棵别称为左子树和右子树 的二叉树组成。
二叉树的特点:
1. 每个结点最多有两棵子树,即二叉树不存在度大于2的结点。
2. 二叉树的子树有左右之分,其子树的次序不能颠倒。

1. 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是 说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。

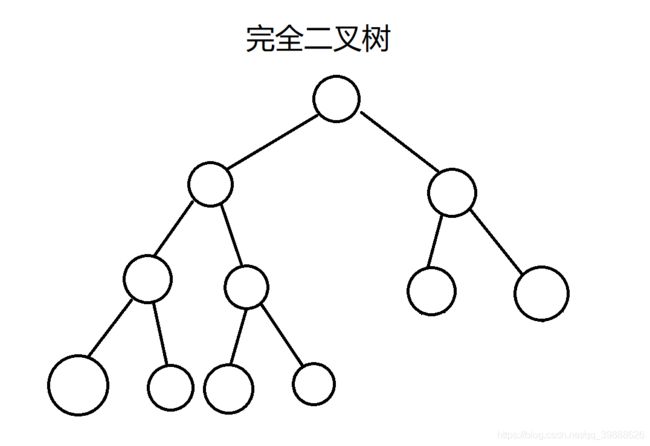
2. 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对 应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树
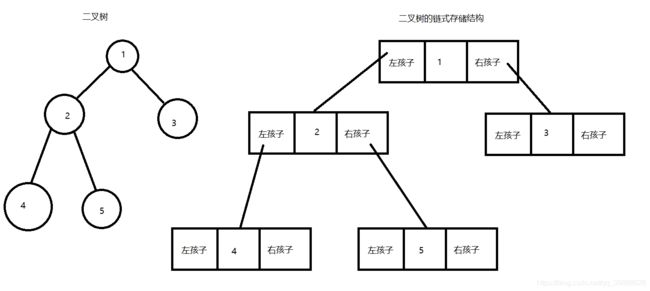
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
二叉树的性质:
1. 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1) 个结点.
2. 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是2^h- 1.
二叉树有三种遍历方式: 前序遍历 中序遍历 后序遍历
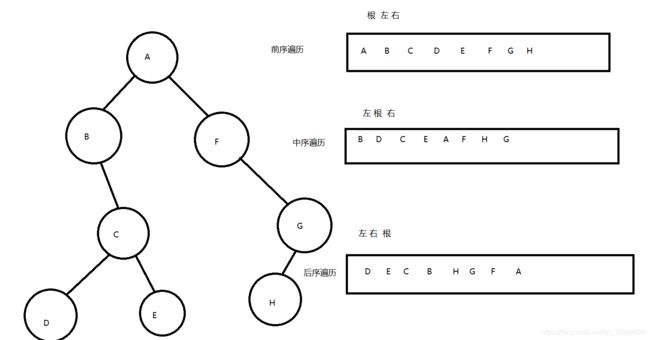
二叉树数组的顺序存储特点:

二叉树用链表表示:
// 二叉链
typedef struct BTree
{
char data;//数据域
struct BTree* lc;//左孩子结点指针
struct BTree* rc;//右孩子结点指针
}BTree;二叉树的建立:
BTree* CreateBTree(char* str,int* val)//str是传入的数组要存放的元素 val是数组的索引值[下标]
{
if(str[*val]!='#')//#表示结束标志比如二叉树的叶子结点没有左右孩子就用##表示
{
BTree* newnode=(BTree*)malloc(sizeof(BTree));//创建一个树的结构体
newnode->data=str[*val];//数据域存放第一个元素
++(*val);//迭代数组到第二个元素
newnode->lc=CreateBTree(str,val);//递归(下面画图讲解)
++(*val);
newnode->rc=CreateBTree(str,val);
return newnode;//返回结点
}
else
return NULL;//如果数组元素是#返回空
}
二叉树的遍历:
void Show(BTree* T)//前序遍历
{
if(T)//判断结点是否为空
{
printf("%c ",T->data);//先打印树的根结点元素
Show(T->lc);//递归成为子树后
Show(T->rc);//右子树递归
}
}
void Show(BTree* T)//中序遍历
{
if(T)//判断结点是否为空
{
Show(T->lc);
printf("%c ",T->data);
Show(T->rc);
}
}
void Show(BTree* T)//后序遍历
{
if(T)//判断结点是否为空
{
Show(T->lc);
Show(T->rc);
printf("%c ",T->data);
}
}二叉树统计叶子结点:
void BTreeLeafNum(BTree* T, int* num)
{
if (T == NULL)//结点为空结束结点
return;
if (T->lc == NULL && T->rc == NULL)//如果结点的左右孩子都是空那这个结点就是叶子结点
++(*num);//加加计数器
BTreeLeafNum(T->lc, num);//左递归
BTreeLeafNum(T->rc, num);//右递归
}二叉树的最大深度:
int maxDepth(BTree* root)
{
if(root==NULL)
return NULL;
return fmax(maxDepth(root->left),maxDepth(root->right))+1;
}二叉树代码写起来很简单,但思考逻辑却很难 。