C/C++ 正则表达式(详细版)
文章目录
- 前言
- 一、总体观摩
-
- 1.纵观所有类
- 2.纵观所有函数
- 二、使用详解
-
- 1.使用前需要了解的东西
- 2.测试字符串
- 3.搜索子字符串
- 4.使用迭代器
- 5.替换字符串
- 6.分割字符串
- 7.异常处理
- 三、封装成类
前言
从C++11开始,C++开始支持正则表达式的使用,用于匹配字符串时非常方便!(比如从爬取的网页源码中提取指定的字符串、匹配用户输入邮箱是否为正确格式、替换一篇文章中指定的所有字符串)
但正如大家所看到的,C++一如既往的使用模板实现,以至于我们使用的时候,如果出错了,很难看明白到底哪里出错了
所以本文对C++正则表达式库进行详细解析,便于大家的使用!
一、总体观摩
正则表达式库为regex,使用C++11及以上即可正常使用
#include<regex>
1.纵观所有类
regex文件里总共有7个模板类以及若干实例化的类
| 模板类 | 实例化类 | 用途 |
|---|---|---|
| basic_regex | regex:实际为basic_regex |
作为正则表达式对象,用于匹配文本 |
| match_results | cmatch,wcmatch,smatch,wsmatch | 用于获得匹配到的结果,实际可以看作sub_match的数组 |
| sub_match | csub_match,wcsub_match ,ssub_match ,wssub_match | 保存捕获组,一般直接用match_result数组访问的方式直接调用,所以一般看不到它 |
| regex_iterator | cregex_iterator,wcregex_iterator,sregex_iterator,wsregex_iterator | 用于遍历结果或子匹配的迭代器 |
| regex_token_iterator | cregex_token_iterator,wcregex_token_iterator,sregex_token_iterator,wsregex_token_iterator | 用于遍历未匹配部分的迭代器 |
| regex_error | 无 | 报告正则表达式库生成的错误 |
| regex_traits | 无 | 描述用于匹配的元素的特征。一般用不上,有需求的可参考官方文档 |
虽然看着挺多,但其实平时真正用到的只有少数几个
特别需要注意的是,上面的类都是分类别配对使用的,比如:
regex ,cmatch,csub_match,cregex_iterator
就是一组
或者
regex ,smatch,ssub_match,sregex_iterator
也是一组
可以总结出的规律有:
- 前缀没有w字母的为操作多字节字符,添加了w的则为操作宽字节字符
- 前缀有c的,代表是操作char*类型字符串
- 前缀有s的,代表是操作string类型字符串
注意,char*类型字符串与string类型实现类之间不能混用,否则会出错!
2.纵观所有函数
| 函数 | 用途 |
|---|---|
| regex_match | 匹配指定字符串整体是否符合 |
| regex_search | 匹配字符串中符合的子字符串 |
| regex_replace | 替换字符串中指定的字符串 |
二、使用详解
如何写正则表达式就不做细说,网上有很多教程,只对函数如何使用作出详细介绍
1.使用前需要了解的东西
下图为regex库默认使用的ECMAScript文法的表达式
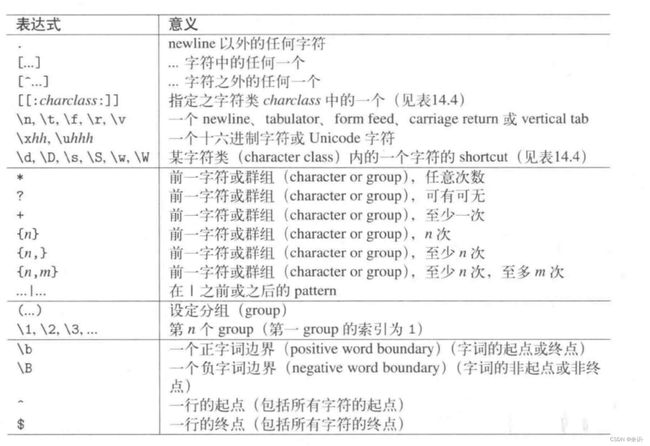

如果想要更改为其它文法,只需要在regex构造函数中最后一位填入对应文法即可,例如:
regex r("<.*?>(.*)<.*?>", regex_constants::grep);
当然除了选择文法,还可以选择其它标志,只需要将他们用符号 | 连接起来即可
如忽略大小写匹配可以写为
regex r("<.*?>(.*)<.*?>", regex_constants::grep|regex_constants::icase);
可以看到,其实这些可选项都在regex_constants中,还有其它可选项如下:
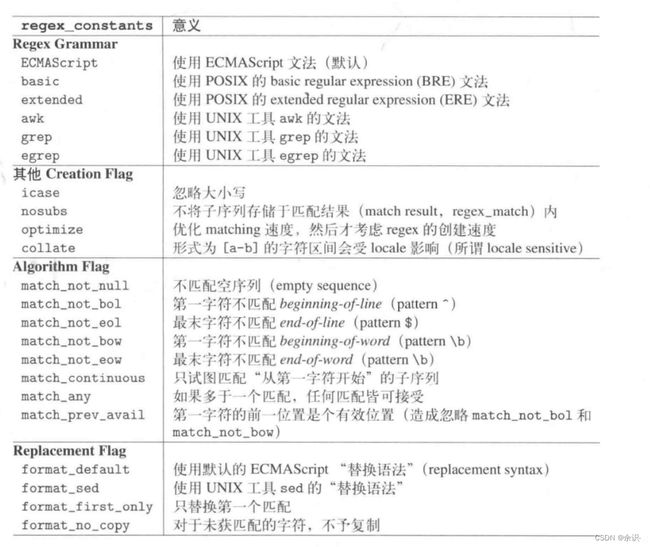
不同文法之间的差异
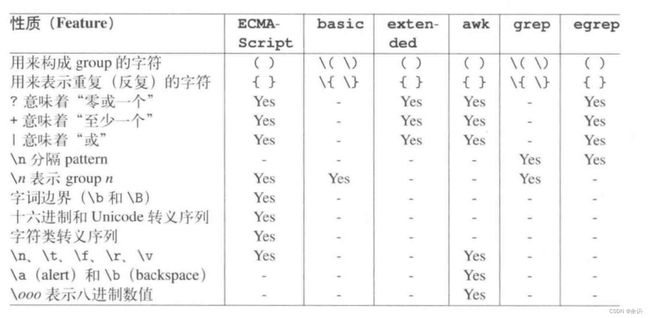
还需要注意的是,C++中许多字符需要添加\ 符号进行转义才能使用,过于麻烦,所以C++11之后,出现了如下写法:
R"dem(内容)dem"
使用该写法就可以不再转义即可使用,其中dem为任意字符,但要求前后一致即可,其它为固定写法
2.测试字符串
该功能用到regex_match 函数
一般来说,最常用的就是下面这种写法:
比如测试用户输入字符串是否包含@符号:
regex r(".*@.*");
string str;
cin >> str;
if (regex_match(str, r)) {
cout << "匹配成功";
}
else {
cout << "匹配失败";
}
3.搜索子字符串
该功能用到regex_search函数
一般用法肯定是找出一段文本中所需要的子字符串,用法如下
string sStr; //要进行匹配的字符串
std::string::const_iterator begin = sStr.begin(); //开始迭代器
std::string::const_iterator end = sStr.end(); //结束迭代器
std::smatch m; //匹配的结果
regex r; //正则表达式
while (std::regex_search(begin, end, m, r)) {
begin = m[0].second; //更新开始迭代器的位置
m[n].str(); //获得第n个捕获组,其中0表示匹配到的全部子字符串
}
该代码段就是不断从sStr中匹配符合r的子字符串,匹配成功则返回true,并将匹配到的结果放在m中,可通过m[n].str()方式返回指定捕获组的子字符串
同时m[0].second记录了当前匹配到的位置,所以通过它更新begin ,就可以遍历所有子字符串,直到无法匹配,返回false,结束
4.使用迭代器
如果你认为regex_search用起来比较麻烦,则可以使用迭代器,用法如下:
regex r("-(.*?)-");
string s = "yushi-csdn--yushi-csdn";
sregex_iterator beg(s.begin(),s.end(),r);
sregex_iterator end;
for (; beg != end; beg++) {
cout << beg->str(1) << endl;
}
由于sregex_iterator 默认构造函数为指向最后一个元素之后,所以对end没有进行任何处理,只是作为一个结束标志
成员函数str可以返回指定捕获组的字符串,不传入数字则代表全部匹配内容
5.替换字符串
该功能用到regex_replace函数
string sStr; //要进行匹配的源字符串
regex r; //正则表达式
string toReplace; //进行替换的字符串
string ret=regex_replace(sStr, r, toReplace)
该函数就是将sStr中匹配符合r的子字符串,将其全部替换为toReplace,并将结果返回到ret中
小技巧:可以在toReplace添加$n,n代表着第几个捕获组,可用于格式化字符串,总结如下:

6.分割字符串
这里主要使用到了sregex_token_iterator
regex r("-"); //以-为分隔符
string s = "yushi-csdn-yushi-csdn";
sregex_token_iterator beg(s.begin(), s.end(), r,-1); //传入-1,代表对匹配到的分隔符之间的内容感兴趣
sregex_token_iterator end; //结束标志
for (; beg != end; beg++) {
cout << beg->str() << endl;
}
用法基本于上述迭代器用法一样
唯一需要注意的是最后传入的那个-1,代表着我想要的是匹配项之间的内容

7.异常处理
regex库里已经实现了异常类regex_error ,直接使用即可,what函数将返回错误信息
try
{
regex r("\{\}");
}
catch (const std::regex_error & e)
{
cout << e.what()<<endl;
}
上述正则表达式使用grep语法,将{}进行转义,将输出以下错误:
regex_error(error_badrepeat): One of *?+{ was not preceded by a valid regular expression.
三、封装成类
可以看出来,原库函数使用起来很不方便,所以我花了点时间将上述几种常用功能封装成类,方便使用
#include
#include因为我测试数据不多,可能存在bug,欢迎在评论区指出,我会及时更正,