【代码开发】RLCard平台Leduc Holdem环境
最近科研需要一个合适的牌类环境,经过调研RLCard最适合自己上手,更容易进行环境接口的改动。写一篇自己最近对RLCard平台开发过程中的一些“经验”吧,方便后来的小白们让环境成功地跑起来。
文章目录
-
- 平台介绍
- 安装
- 代码结构
- 模型训练代码及解读
-
- main
- train
- 运行代码
- 总结
平台介绍
RLCard: A Toolkit for Reinforcement Learning in Card Games

RLCard is a toolkit for Reinforcement Learning (RL) in card games. It supports multiple card environments with easy-to-use interfaces for implementing various reinforcement learning and searching algorithms. The goal of RLCard is to bridge reinforcement learning and imperfect information games. RLCard is developed by DATA Lab at Texas A&M University and community contributors.
Github:https://github.com/datamllab/rlcard
Official Website: https://www.rlcard.org
Tutorial in Jupyter Notebook: https://github.com/datamllab/rlcard-tutorial
Paper: https://arxiv.org/abs/1910.04376
网络上也有很多关于RLCard的pr稿,感兴趣可以搜来看看,能够增进对RLCard的理解。
安装
官方Official Website教程上都有,不是本文的重点。摘录几个重要的指令,让大家对安装过程有个概念:
(看不懂这些指令含义的小白不要依次执行这些指令!这些指令功能在官方文档有写!具体安装流程请看Official Website!)
pip3 install rlcard
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install rlcard[torch]
git clone https://github.com/datamllab/rlcard.git
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
之后就可以在项目根目录,创建python文件运行一下代码:
import rlcard
from rlcard.agents import RandomAgent
print(env.num_actions) # 2
print(env.num_players) # 1
print(env.state_shape) # [[2]]
print(env.action_shape) # [None]
env = rlcard.make('blackjack') # choose blackjack env
env.set_agents([RandomAgent(num_actions=env.num_actions)])
trajectories, payoffs = env.run()
代码结构
来到rlcard根目录。
最重要的是rlcard那个文件夹下的内容。其他部分内容感兴趣可以在官方教程上看到详细介绍。快速上手的一个不错的方式就是研究examples文件夹下的代码。
先来看rlcard文件夹:
agent文件夹放一些简单的agent结构。自带有cfr/dqn/nfsp等,自己如果想魔改agent结构、功能就可以放在这个文件下目录下。
envs放置一些rlcard支持的游戏环境。这些环境各自对应一个类,都继承自env.py这个文件。我们主要讨论leducholdem环境的话只用关心leducholdem.py就可以了。
games文件夹下是每个游戏环境具体类的实现,以Leducholdem为例,有judger、dealer等,不同的类负责不同模块。
models文件夹主要是存放不同游戏的规则、合法动作判断等和规则有关的模块,如果不修改规则的话这个文件夹也可以不用理睬。
utils文件夹就是一些杂七杂八的工具,比如logger(打印保存数据)、seeding(随机种子)等。
模型训练代码及解读
以examples文件夹下的run_rl.py文件为例子,详细说说训练模型的基本步骤。
''' An example of training a reinforcement learning agent on the environments in RLCard
'''
import os
import argparse
import torch
import rlcard
from rlcard.agents import RandomAgent
from rlcard.utils import get_device, set_seed, tournament, reorganize, Logger, plot_curve
def train(args):
# Check whether gpu is available
device = get_device()
# Seed numpy, torch, random
set_seed(args.seed)
# Make the environment with seed
env = rlcard.make(args.env, config={'seed': args.seed})
# Initialize the agent and use random agents as opponents
if args.algorithm == 'dqn':
from rlcard.agents import DQNAgent
agent = DQNAgent(num_actions=env.num_actions,
state_shape=env.state_shape[0],
mlp_layers=[64,64],
device=device)
elif args.algorithm == 'nfsp':
from rlcard.agents import NFSPAgent
agent = NFSPAgent(num_actions=env.num_actions,
state_shape=env.state_shape[0],
hidden_layers_sizes=[64,64],
q_mlp_layers=[64,64],
device=device)
agents = [agent]
for _ in range(1, env.num_players):
agents.append(RandomAgent(num_actions=env.num_actions))
env.set_agents(agents)
# Start training
with Logger(args.log_dir) as logger:
for episode in range(args.num_episodes):
if args.algorithm == 'nfsp':
agents[0].sample_episode_policy()
# Generate data from the environment
trajectories, payoffs = env.run(is_training=True)
# Reorganaize the data to be state, action, reward, next_state, done
trajectories = reorganize(trajectories, payoffs)
# Feed transitions into agent memory, and train the agent
# Here, we assume that DQN always plays the first position
# and the other players play randomly (if any)
for ts in trajectories[0]:
agent.feed(ts)
# Evaluate the performance. Play with random agents.
if episode % args.evaluate_every == 0:
logger.log_performance(env.timestep, tournament(env, args.num_eval_games)[0])
# Get the paths
csv_path, fig_path = logger.csv_path, logger.fig_path
# Plot the learning curve
plot_curve(csv_path, fig_path, args.algorithm)
# Save model
save_path = os.path.join(args.log_dir, 'model.pth')
torch.save(agent, save_path)
print('Model saved in', save_path)
if __name__ == '__main__':
parser = argparse.ArgumentParser("DQN/NFSP example in RLCard")
parser.add_argument('--env', type=str, default='leduc-holdem',
choices=['blackjack', 'leduc-holdem', 'limit-holdem', 'doudizhu', 'mahjong', 'no-limit-holdem', 'uno', 'gin-rummy', 'bridge'])
parser.add_argument('--algorithm', type=str, default='dqn', choices=['dqn', 'nfsp'])
parser.add_argument('--cuda', type=str, default='')
parser.add_argument('--seed', type=int, default=42)
parser.add_argument('--num_episodes', type=int, default=5000)
parser.add_argument('--num_eval_games', type=int, default=2000)
parser.add_argument('--evaluate_every', type=int, default=100)
parser.add_argument('--log_dir', type=str, default='experiments/leduc_holdem_dqn_result/')
args = parser.parse_args()
os.environ["CUDA_VISIBLE_DEVICES"] = args.cuda
train(args)
main
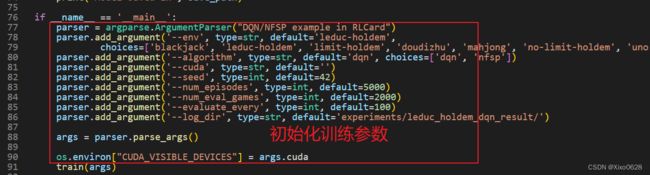
咱们从76行,main函数开始看。
parser是一些训练用的参数,比如 env选择了Leduc-holdem,algorithm选择了dqn,以及后面的cuda、seed等参数,相信从名字就能看明白是什么含义。读取了训练的基本参数后,就可以开始训练了。
train
接下来看train这个函数。第一部分是配置环境,没什么可说的。第二部分就是根据选择的算法,选择不同类型的agent。这个初始化的agent就是我们要“训练”的agent,现在它还是一个只会做随即动作的小白。
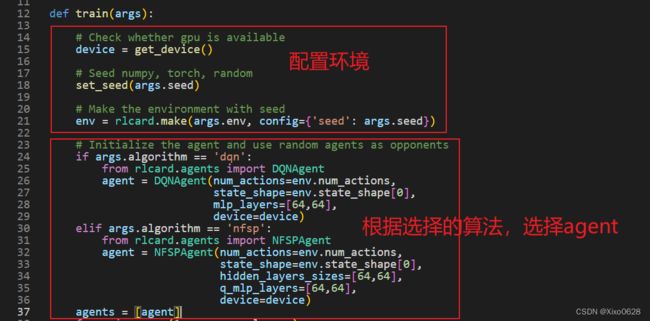
根据设定的游戏人数增加对手,选择对手也是随机决策的agent,对手在训练过程中不发生变化(他们既不会变强也不会变弱)。Leduc Holdem 只支持2个玩家参与(env.num_players=2)。

最核心的就是训练部分的代码了。分为四个部分。
- 先利用环境里的agent对打,生成一系列牌局信息。
- 然后将reward数据进行加工,插入到牌局信息中去。
- 然后利用这些生成的数据来训练agent。值得一提的是,rlcard默认的方式是将数据加工成(s,a,r,s’,done)的方式。
- 每训练一定的episode就进行测试。
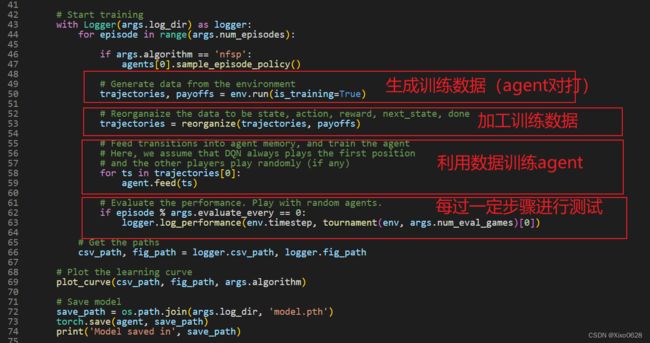
最后一部分就是把训练的模型保存下来。
运行代码
默认运行时会有如下输出:
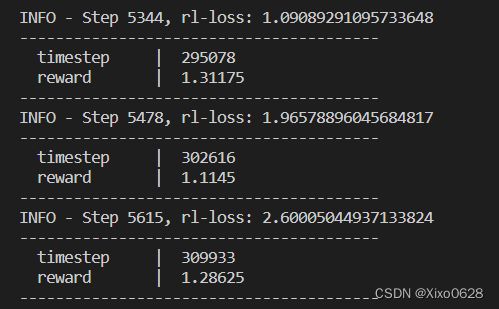
经过一段时间的等待(大约0.5min左右),就可以在log_dir对应的文件夹目录中,看到最终的训练结果:
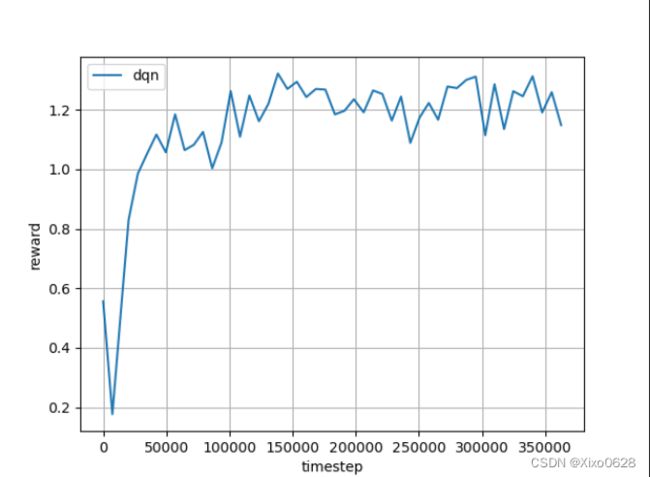
可以看出模型训练确实会带来reward的提升。顺便说一下,横轴就是模型对打的步数,纵轴就是每次测试2000局,平均每局能赢的大盲(BB)数量。这里因为对手是random决策的,所以非常菜,最终我们的dqn agent平均下来每局能赢1.2BB左右。
总结
至此,基本流程算是跑通了,接下来就是阅读源码、魔改调优了。加油!