Channel Attention 通道注意力
通道注意力总结
- SE-Net:Squeeze-and-Excitation Networks
- CBAM: Convolutional Block Attention Module
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
- EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network
- FcaNet: Frequency Channel Attention Networks
- GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
- Coordinate Attention for Efficient Mobile Network Design
SE-Net:Squeeze-and-Excitation Networks

Squeeze操作
由于卷积只是在一个局部空间内进行操作, U很难获得足够的信息来提取channel之间的关系,对于网络中前面的层这更严重,因为感受野比较小。为了,SENet提出Squeeze操作,将一个channel上整个空间特征编码为一个全局特征,采用global average pooling来实现。
Excitation操作

Scale操作

SE模块的灵活性在于它可以直接应用现有的网络结构中。这里以ResNet为例。对于ResNet,SE模块嵌入到残差结构中的残差学习分支中。
CBAM: Convolutional Block Attention Module

Convolutional Block Attention Module (CBAM) 表示卷积模块的注意力机制模块,是一种结合了空间(spatial)和通道(channel)的注意力机制模块。相比于senet只关注通道(channel)的注意力机制可以取得更好的效果。
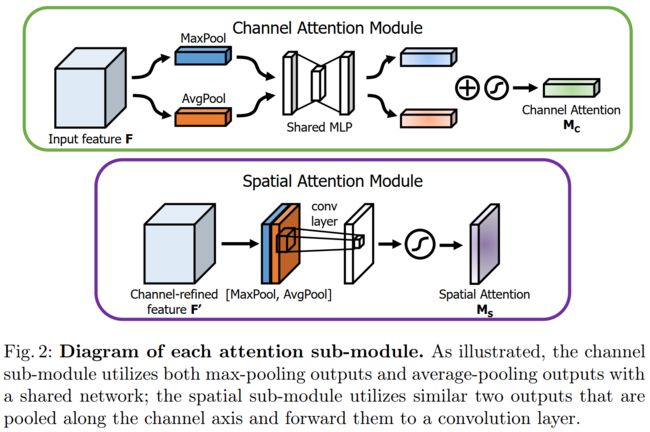

ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
ECANet主要对SENet模块进行了一些改进,提出了一种不降维的局部跨信道交互策略(ECA模块)和自适应选择一维卷积核大小的方法,从而实现了性能上的提优。作者的实验研究表明,降维对通道注意预测带来了副作用,捕获所有通道之间的依赖是低效的,也是不必要的。

K的计算方式:
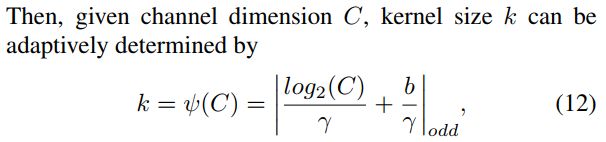
ECA模块伪代码:

EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network
PSA模块可以处理多尺度的输入特征图的空间信息并且能够有效地建立多尺度通道注意力间的长期依赖关系。然后,我们将PSA 模块替换掉ResNet网络Bottleneck中的3x3x卷积,其余保持不变,最后得到了新的EPSA(efficient pyramid split attention) block.基于EPSA block我们构建了一个新的骨干网络称作:EPSANet。它既可以提供强有力的多尺度特征表示能力。
code学习:基于Paddle复现ESPANet,多尺度思想应用到attention,精度超越ResNet


实现细节:
- SPC模块是4个不同Kernel的Conv2D(C,C’),不是Conv2D(C’,C’)
- SEWeightModule是在每个C’块中单独进行的,与SENet中的模块一致

- Softmax操作是在S这个维度做的,可以看代码就明白了
self.softmax = nn.Softmax(axis=1)
x_se = torch.concat((x1_se, x2_se, x3_se, x4_se), axis=1)
attention_vectors = x_se.reshape([batch_size, 4, self.split_channel, 1, 1])
attention_vectors = self.softmax(attention_vectors)
效果展示:

FcaNet: Frequency Channel Attention Networks
所提出的方法简单但有效。我们只在计算中更改一行代码,以在现有通道注意力方法中实施我们的方法。

基于DCT频域分析,作者提出:GAP(Global Average Pooling)是频域特征分解的一种特例
Channel Attention:
通道注意力机制已被广泛应用到CNN网络架构中,它采用一个可学习的网络预测每个通道的重要。其定义如下:

Discrete Cosine Transform:
DCT的定义如下:

其中 f ∈ R L f \in R^L f∈RL 表示DCT的频谱。2D-DCT的定义如下:

其中, f h , w 2 d f^{2d}_{h,w} fh,w2d表示2D-DCT频谱。对应的2D-IDCT的定义如下(去除常数项):

基于上述通道注意力与DCT的定义,我们可以总结得到以下两点关键属性:
(1) 现有的通道注意力方案采用GAP作为预处理;
(2) DCT可以视作输入与其cosine部分的加权。GAP可以视作输入的最低频信息,而在通道注意力中仅仅采用GAP是不够充分的。基于此,作者引入了本文的多谱通道注意力方案。
Multi-Spectral Channel Attention
在正式引出多谱通道注意力之前,作者首先给出了一个定理,如下所示。其中 f 0 , 0 2 d f^{2d}_{0,0} f0,02d表示D2-DCT的最低频成分。

上述定理意味着:**通道注意力机制中可以引入其他频域成分。**与此同时,作者也解释了为什么有必要引入其他频率成分。
为简单起见,我们采用B表示2D-DCT的基函数:

那么,2D-DCT可以重写成如下形式:
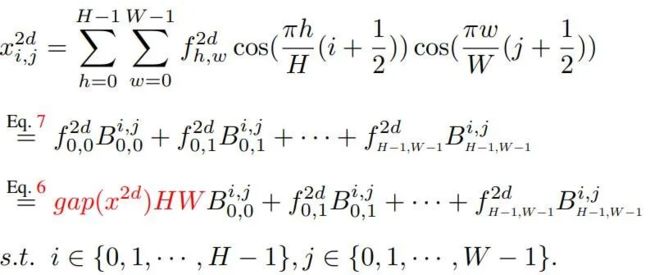
自然地,我们可以看到:图像/特征可以表示为不同频率成分的线性组合。再来看通道注意力的公式: a t t = s i g m o i d ( f c ( g a p ( X ) ) ) att = sigmoid(fc(gap(X))) att=sigmoid(fc(gap(X))),即通道注意力仅仅依赖于GAP结果。而X的信息却不仅仅由GAP构成:
![]()
从上述公式可以看到:仅有一小部分信息在通道注意力中得以应用,而其他频域成分则被忽略了。
Multi-Spectral Attention Module
基于上述分析,作者很自然的将GAP扩展为2D-DCT的更多频率成分的组合,即引入更多的信息解决通道注意力中的信息不充分问题。
首先,输入X沿通道维划分为多个部分 [ X 0 , X 1 , . . . , X n − 1 ] [X^0,X^1,...,X^{n-1}] [X0,X1,...,Xn−1];对于每个部分,计算其2D-DCT频率成分并作为通道注意力的预处理结果。此时有:

将上述频域成分通过concat进行组合,
![]()
这个多谱通道注意力机制与描述如下:
![]()

Criterion for choosing frequence components
从前述定义可以看到:2D-DCT有多个频率成分,那么如何选择合适的频率成分呢?
文中指出一共有三种方式: FcaNet-LF (Low Frequency),
FcaNet-TS (Two-Step selection), and FcaNet-NAS (Neural
Architecture Search)

作者选择了这种“two-step”准则选择多谱注意力中的频率成分。
选择的主旨在于:首先确定每个频率成分的重要性,然后确定不同数量频率成分的影响性。首先,独立的确认每个通道的同频率成分的结果,然后选择Top-k高性能频率成分。
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
本文首先是从Non-local Network的角度出发,发现对于不同位置点的attention map是几乎一致的,说明non-local中每个点计算attention map存在很大的计算浪费,从而提出了简化的NL,也就是SNL。关于这点,似乎有较大的争议,从论文本身来看,实验现象到论证过程都是完善的,但是有人在github项目中指出 OCNet和DANet两篇论文中的结论是attention map在不同位置是不一样的,似乎完全相关,作者目前也没有回复。


更进一步地,作者还研究了和SENet的关联,基于SENet和SNL,提出了统一的框架,并结合两者优点提出了GCNet,计算量相对较小,又能很好地融合全局信息。

并且说明了SNL和SE都是其一种特殊形式,并结合两者优点,提出了d,GC block,并有以下优点:
1)相比于SNL,SNL中的transform的1x1卷积在res5中是2048x1x1x2048,其计算量较大,所以借鉴SE的方法,加入压缩因子,为了更好的优化,还加入了layernorm。
2)相比于SE,一方面是提取的全局信息更加充分(其实在后续的实验中说服力不是很强,单独avg pooling+add,只掉了0.3个点,但是更加简洁),另一方面则是加号和乘号的区别,而且在实验结果上,加号比乘号有显著的优势。
Coordinate Attention for Efficient Mobile Network Design
通道注意力会给模型带来比较显著的性能提升,但是通道注意力通常会忽略对生成空间选择性注意力图非常重要的位置信息。本文提出了一种为轻量级网络设计的新的注意力机制,该机制将位置信息嵌入到了通道注意力中,称为coordinate attention(简称CoordAttention,下文也称CA)。不同于通道注意力将输入通过2D全局池化转化为单个特征向量,CoordAttention将通道注意力分解为两个沿着不同方向聚合特征的1D特征编码过程。这样的好处是可以沿着一个空间方向捕获长程依赖,沿着另一个空间方向保留精确的位置信息。然后,将生成的特征图分别编码,形成一对方向感知和位置敏感的特征图,它们可以互补地应用到输入特征图来增强感兴趣的目标的表示。
SE模块只考虑了通道间信息的编码而忽视了位置信息的重要性,而位置信息其实对于很多需要捕获目标结构的视觉任务至关重要。因此,后来CBAM等方法通过减少通道数继而使用大尺寸卷积来利用位置信息,如下图所示。然而,卷积仅仅能够捕获局部相关性,建模对视觉任务非常重要的长程依赖则显得有些有心无力。
因此,这篇论文的作者提出了一种新的高效注意力机制,通过将位置信息嵌入到通道注意力中,使得轻量级网络能够在更大的区域上进行注意力,同时避免了产生大量的计算开销。为了缓解2D全局池化造成的位置信息丢失,论文作者将通道注意力分解为两个并行的1D特征编码过程,有效地将空间坐标信息整合到生成的注意图中。更具体来说,作者利用两个一维全局池化操作分别将垂直和水平方向的输入特征聚合为两个独立的方向感知特征图。然后,这两个嵌入特定方向信息的特征图分别被编码为两个注意力图,每个注意力图都捕获了输入特征图沿着一个空间方向的长程依赖。因此,位置信息就被保存在生成的注意力图里了,两个注意力图接着被乘到输入特征图上来增强特征图的表示能力。由于这种注意力操作能够区分空间方向(即坐标)并且生成坐标感知的特征图,因此将提出的方法称为坐标注意力(coordinate attention)。

Contribution:
- 首先,它不仅仅能捕获跨通道的信息,还能捕获方向感知和位置感知的信息,这能帮助模型更加精准地定位和识别感兴趣的目标;
- 其次,coordinate attention灵活且轻量,可以被容易地插入经典模块,如MobileNetV2提出的inverted residual block和MobileNeXt提出的 sandglass block,来通过强化信息表示的方法增强特征;
- 最后,作为一个预训练模型,coordinate attention可以在轻量级网络的基础上给下游任务带来巨大的增益,特别是那些存在密集预测的任务(如语义分割)。

Reference:
通道注意力新突破!从频域角度出发,浙大提出FcaNet:仅需修改一行代码,简洁又高效
基于Paddle复现ESPANet,多尺度思想应用到attention,精度超越ResNet
解读Squeeze-and-Excitation Networks(SENet)
EPSANet:金字塔拆分注意力模块
通道注意力超强改进,轻量模块ECANet来了!即插即用,显著提高CNN性能|已开源
CBAM:卷积注意力机制模块
2019 GCNet(attention机制,目标检测backbone性能提升)论文阅读笔记
CoordAttention