Redis五大数据类型和三种特殊类型常用命令
Redis基础知识
1、先开启redis服务器: redis-server /myredis/redis.conf
2、查看线程是否启动:ps -ef|grep redis
3、开启客服端:redis-cli -p 6379
redis默认有16个数据库,
可以进入配置文件查看
回顾linux命令:wq来保存,如果是q!则不保存的。

默认使用的是第0个,
可以使用select进行切换

常用命令:
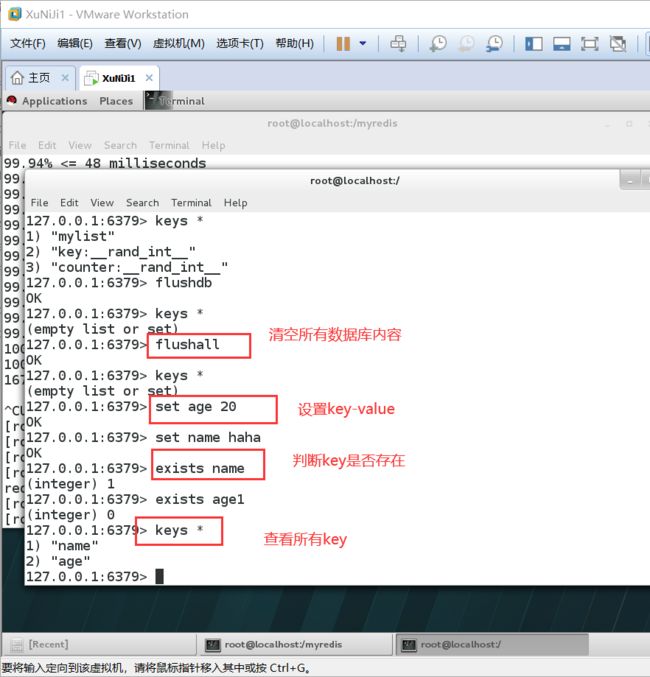
keys * #查看数据库所有的key
flushdb #清空当前数据库内容
FLUSHALL #清空全部数据库内容
注意linux是区分大小写的,但是redis不区分大小写
Linux系统下文件名是区分大小写的,文件名采用大小写是不一样的;linux变量、命令、命令参数都是区分大小写的。
可以追溯到linux系统的开发,linux的内核是使用C语言开发的,C语言区分大小写。所以linux也区分大小写了。
redis为什么采用6379作为默认端口号?
因为是一个女明星的的名字在手机上键盘的数字,粉丝效应
redis是单线程的!
redis是很快的,官方表示,redis是基于内存操作的,cpu不是redis性能瓶颈,redis的瓶颈是根据及机器内存和网络带宽决定的,既然可以使用单线程实现,就用单线程了。
为什么redis单线程还那么快?
多线程的并不一定就比单线程的效率高,首先cpu的速度是最快的,之后是内存再是硬盘(cpu > 内存 > 硬盘),而redis是将所有的数据放在内存中的,所以说使用单线程去操作效率就是最高的,多线程(cpu会上下文切换,会消耗时间),对于内存系统来说,如果没有上下文切换效率就是最高的!多次读写都是在一个cpu上的,在内存情况下,这个就是最佳的方案。
误区1:高性能的服务器一定是多线程的??
误区2:多线程(cpu上下文会切换!)一定比单线程效率高?
五大数据类型

全段翻译:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis-Key
移动一个key到其他数据库

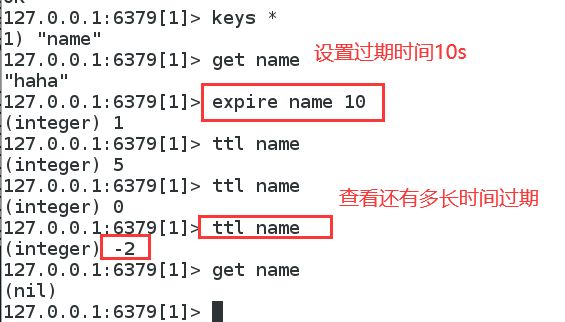
设置key过期时间
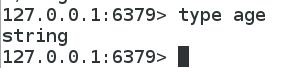
查看key是什么类型
String(字符串)

注意:追加字符串时,如果当前key不存在,就相当于set key
微信浏览量怎么++的,字符串的增减?

字符串的范围

替换从指定位置开始的字符串

setex(set with expire) 设置过期时间
setnx(set if not exist) 不存在再设置,存在的话就失败

批量的设置多个值和获取

msetnx是一个原子操作
设置对象及其属性
这里key是一个巧妙的设计: user:{id}:{filed}

getset :先get然后set

String类型的使用场景:value除了是我们的字符串还可以是我们的数字
- 计时器(自增incr)
- 统计多单位的数量
- 粉丝数(根据用户id存储数自增/减)
- 对象缓存存储
List(列表)
redis不区分大小写,在redis里面,我们可以把list完成栈,队列,阻塞队列
所有的list命令都是用l开头的
基本的数据类型
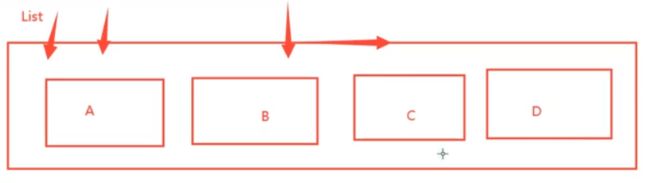
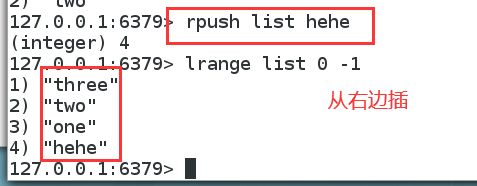
list添加值

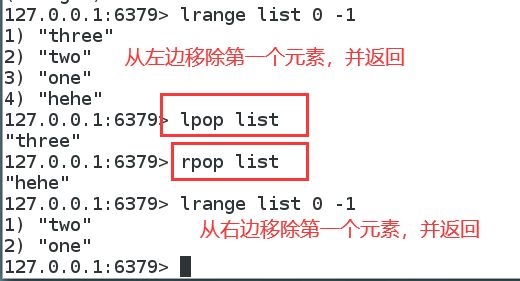
移除值
索引

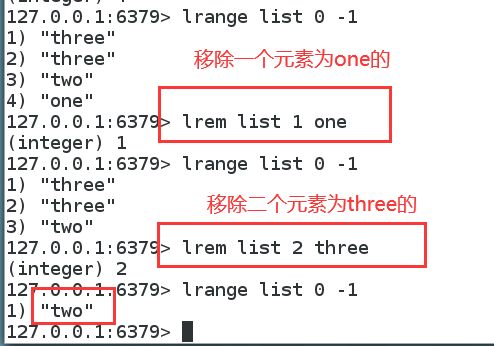
移除指定的值
trim 修剪 list 截断

移除元素到新的列表

lset:将列表中指定下标的值替换成另外一个,更新操作

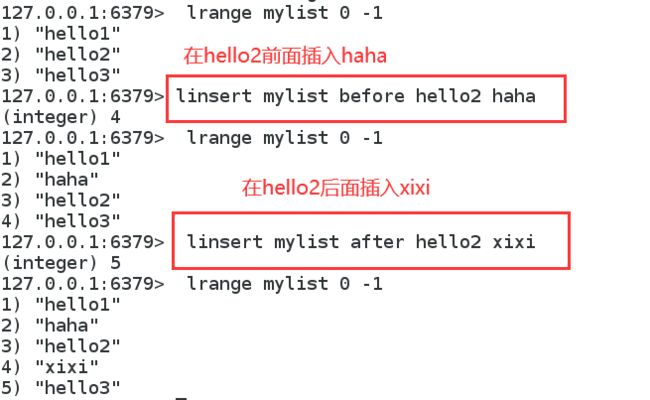
插入insert:将某个具体的value插入到某个元素的前面或者后面
小结:
- list实际上是一个链表, before Node after ,left,right 都可以插入值
- 如果key不存在,创建新的链表
- 如果key存在,新增内容
- 如果移除了所有值,空链表,也代表不存在!
- 在两边插入或者改动值,效率最高!中间元素,相对来说效率会低一点
消息排队,消息队列(Lpush Rpop),栈(Lpush Lpop)
Set(集合)
里面的值不能重复,无序不重复集合
命令都是s开头
添加元素并查看


rem移除元素

set集合是无序的,随机抽取一个元素

删除指定的key和随机删除

将一个指定的值,移动到另外一个set集合

微博,B站的共同关注(交集)
数字集合类
- 差集
- 交集
- 并集
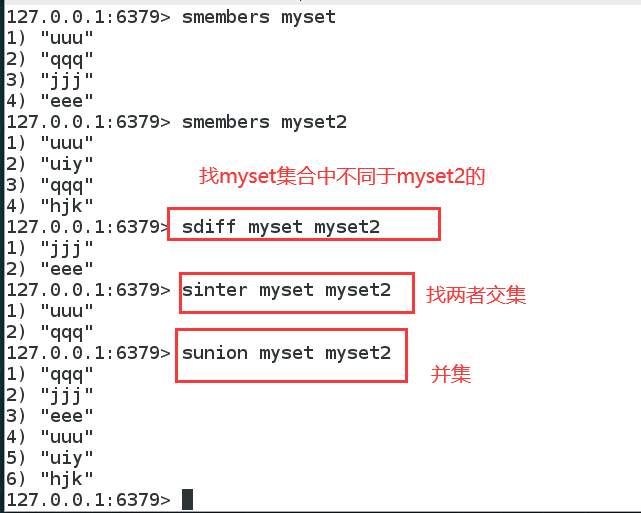
微博,A用户将所有关注的人放在一个set集合中,将它的所有粉丝也放在一个set集合中,那么利用求交集就可以找到共同关注。
共同关注,共同爱好,推荐好友
Hash(哈希)
Map集合,key-map的时候这个值是一个map集合,即key-
所有命令以h开头,本质和set集合没什么区别,还是一个集合
添加并查看值

删除key

获取hash表的字段数量

获取key或value

增量/存在

hash变更的数据user name age,尤其是用户信息之类的,经常变动的信息!hash更适合与对象的存储

Zset(有序集合)
在set的基础上,增加了一个值(表示优先级,值越小,优先级越大) set k1 v1
zset k1 score v1
添加元素

排序
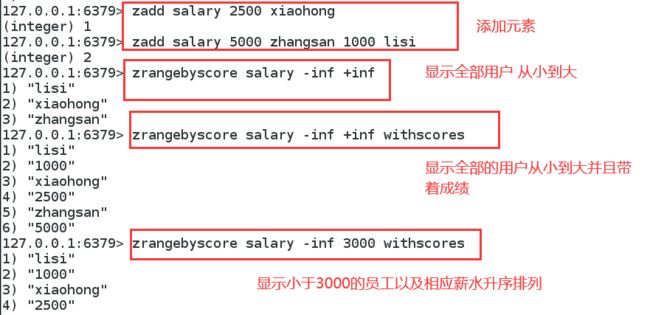

移除元素

zcard salary :获得集合中的个数
获得指定区间成员个数
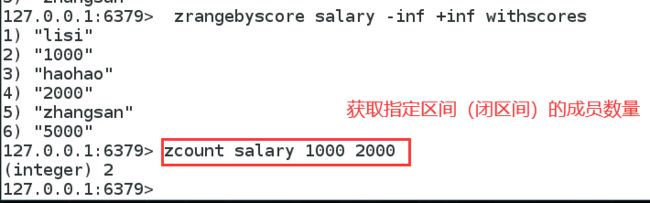
案例思路:set 排序 存储班级成绩表,工资表排序,排行榜
带权重进行判断: 普通消息1 ,重要消息为2
三种特殊数据类型
geospatial 地理位置
朋友的定位,附近的人,打车举例计算?
redis的Geo可以推算地理位置的信息,两地的距离,方圆几公里的人
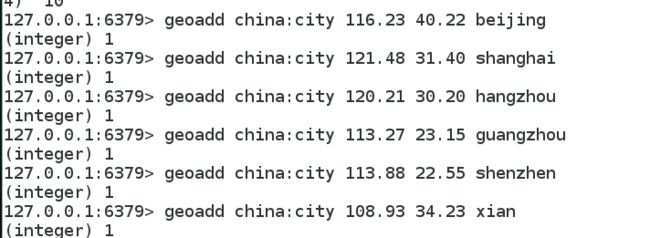
1、geoadd
添加地理位置,规则:两级无法直接添加,可以通过java程序一次性导入
参数:纬度、经度、名称
有效的经度从-180度到180度。
有效的纬度从-85. 05112878度到85.05112878度。
2、getpos
获得当前定位:一定是一个坐标值

3、geodist
两人之间的距离
单位:
● m表示单位为米。
●km表示单位为千米。
●mi表示单位为英里。
●ft表示单位为英尺。

4、georadius
以给定的经纬度为中心,找出某一半径内的元素
我附近的人?(获得所有附近的人的地址,定位),通过半径来查询
获得指定数量的附近的人

5、georadiusbymember
找出位于指定元素周围的其他元素

6、geohash
但会一个或多个未知元素的Geohash表示
该命令将返回11个字符串,将二维的经纬度转换为一个字符串,如果两个字符串越接近,那么则距离约近。

总结:
Geo底层原理其实是Zset ,可以使用Zset命令来操作geo

Hyperloglog
Redis Hyperloglog 技术统计的算法
优点: 占的内存是固定的,2^64不同的元素的技术,只需要费12kb
应用: 页面的访问量(一个人访问一个网站多次,但是还是算作一个人)
什么是基数? 不重复的元素的个数,可以接受误差
例如 B{1,2,3,4},不重复的元素有4个,所以基数为4
所有命令以p开头
如果允许容错,那么就一定使用Hyperloglog
如果不允许容错,就是用set活着自己的数据类型即可

Bitmaps
位存储
应用:
-
统计疫情感染人数: 0 1 0 1
-
统计用户信息(活跃/不活跃)
-
登录,未登录
-
打卡
只有两种状态的都可以使用Bitmaps
Bitmaps位图,数据结构,都是操作二进制位来进行记录,就只有0和1两种状态

使用bitmaps来记录周一到周日的打卡

查看某一天是否打卡

统计打卡的天数
