SQL语言——基本概念、操作数据库、表、表记录、数据库备份与恢复、外键约束
SQL语言
1.基本概念
1.1 SQL
SQL–Structured Query Language, 结构化查询语言,是关系型数据库通用的操作语言。
是一种非过程性语言。
由美国国家标准局(ANSI)与国际标准化组织(ISO)制定SQL标准。各大数据库厂商都对其做了实现。所以我们只要学会了SQL语言,就可以操作各大关系型数据库了。
为加强SQL的语言能力,各厂商增强了过程性语言的特征,增加了一些非标准的SQL,这样的SQL称为该数据库的“方言”。
SQL是用来存取关系数据库的语言,具有查询、操纵、定义和控制关系型数据库的四方面功能
2.操作数据库
2.1 创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]
IF NOT EXISTS: 在创建前判断是否存在,如果不存在则创建,存在则不创建也不报错
create_specification:
CHARACTER SET charset_name #数据库默认编码集
COLLATE collation_name #数据库默认校对规则
案例
1.创建一个名称为mydb1的数据库。
CREATE DATABASE mydb1;
2.创建一个使用gbk字符集的mydb2数据库。
CREATE DATABASE mydb2 CHARACTER SET gbk;
3.创建一个使用utf8字符集,并带校对规则的mydb3数据库。
CREATE DATABASE mydb3 CHARACTER SET utf8 COLLATE utf8_bin;
2.2 查看数据库
显示所有数据库
show databases;
显示数据库创建语句
show create database db_name;
案例
查看所有数据库
show databases;
查看mydb3创建语句
show create database mydb3;
2.3 修改数据库
ALTER DATABASE [IF NOT EXISTS] db_name [alter_specification [, alter_specification] ...]
IF NOT EXISTS: 在修改前判断是否存在,如果存在则修改,如果不存在则不修改也不报错
create_specification:
CHARACTER SET charset_name #修改数据库字符集编码集
COLLATE collation_name #修改数据库校对规则
案例
把mydb2库的字符集修改为utf8
ALTER DATABASE mydb2 CHARACTER SET utf8;
删除数据库
DROP DATABASE [IF EXISTS] db_name;
IF EXISTS: 在删除前判断是否存在,如果存在则删除,如果不存在则不删除也不报错
案例
删除前面创建的mydb1数据库
DROP DATABASE mydb1;
选择数据库
USE db_name;
3.操作表
3.1 mysql数据类型
i.字符类型
1.varchar
变长的字符串,需要在声明字段时指定能存储的最大字符数,真实占用的空间取决于存入的字符数,存入的越多占用空间越多。
适合保存内容长度不定的字符类型数据。
能包含数据的大小,mysql5.0以前0~255字节,mysql5.0以后0 ~ 65535字节
2.char
定长字符串,需要在声明字段时指定固定字符数。即使存入的字符数少于该长度,该字段也会占用该固定长度。适合存储长度不变的字符类型数据。能包含数据的大小,0~255字节
ii.大数类型
1.Blob
大二进制类型,可以存入二进制类型的数据,通过这个字段,可以将图片、音频、视频等数据以二进制的形式存入数据库。最大为4GB。
2.Text
大文本,被声明为这种类型的字段,可以保存大量的字符数据,最大为4GB。
注意:text属于mysql的方言,在其他数据库中为clob类型
iii.数值类型
1.TINYINT
占用1个字节,相当于java中的byte
2.SMALLINT
占用2个字节,相当于java中的short
3.INT
占用4个字节,相当于java中的int
4.BIGINT
占用8个字节,相当于java中的long
5.FLOAT
占用4个字节,浮点型,相当于java中的float
6.DOUBLE
占用8个字节,浮点型,相当于java中的double
iv.逻辑型
1.BIT
位类型,可以存储指定位的值,可以指定位的个数,如果不指定则默认值为1位,即只能保存0或1,对应到java中可以是boolean型。
v.日期型
1.DATE:日期
例如:2020-09-10
2.TIME:时间
例如:20:30:22
3.DATETIME:日期时间
例如:2020-09-10 20:30:22
4.TIMESTAMP:时间戳
例如:2020-09-10 20:30:22
和DATATIME不同,TIMESTAMP类型底层存储的是毫秒值数据
TIMESTAME类型的数据有自动更新机制,即当数据发生变更时,时间戳会自动更新为最新的时间。
3.2 约束
i.主键约束
通常每张表都会有一个字段或多个字段联合起来唯一标识表记录,这样的字段称为这张表的主键字段。
可以为这样的字段增加相应的主键相关的约束称之为主键约束。
主键约束要求字段必须非空且唯一。
primary key [auto_increment]
ii.唯一约束
如果需要指定某个字段的值不能重复,可以为该字段指定唯一约束。
unique
iii.非空约束
如果需要指定某个字段的值不能为空,可以为该字段指定非空约束。
not null
iv.外键约束
3.3 创建表
CREATE TABLE table_name
(
field1 datatype [cons],
field2 datatype [cons],
field3 datatype [cons]
)[character set 字符集] [collate 校对规则]
field:指定列名
datatype:指定列类型
cons:约束条件
案例
1.创建Employee表
| 字段 | 属性 |
|---|---|
| id | 整型 |
| name | 字符型 |
| gender | 字符型 |
| birthday | 日期型 |
| entry_date | 日期型 |
| job | 字符型 |
| salary | 小数型 |
| resume | 大文本型 |
create table employee(
id int,
name varchar(20),
gender char(1),
birthday date,
entry_date date,
job varchar(20),
salary double,
resume text
);
2.创建Employee2表,加入指定约束

create table employee2(
id int primary key auto_increment,
name varchar(20) unique,
gender char(1) not null,
birthday date,
entry_date date,
job varchar(20),
salary double,
resume text
);
3.4 查看表
列出数据库中所有表
SHOW TABLES;
查看指定表结构
DESC tab_name;
查看指定表的建表语句
SHOW CREATE TABLE tab_name;
案例:
列出mydb2数据库中所有的表
use mydb2;
show tables;
查看employee表的表结构
desc employee;
查看employee表的建表语句
show create table employee;
3.5 修改表
增加列:
ALTER TABLE tab_name ADD (column datatype [DEFAULT expr][, column datatype]...);
修改列:
ALTER TABLE tab_name MODIFY (column datatype [DEFAULT expr][, column datatype]...);
删除列:
ALTER TABLE tab_name DROP (column);
修改表名:
ALTER TABLE old_tab_name RENAME TO new_tab_name;
或
RENAME TABLE old_tab_name TO new_tab_name;
修改列名称:
ALTER TABLE tab_name CHANGE [column] old_col_name new_col_name datatype;
修改列的顺序:
ALTER TABLE tab_name MODIFY col_name1 datatype AFTER col_name2;
ALTER TABLE tab_name MODIFY col_name1 datatype FIRST;
修改表的字符集:
ALTER TABLE tab_name CHARACTER SET character_name;
案例
在上面员工表的基础上增加一个image列。
alter table employee add (image blob);
修改job列,使其长度为60。
alter table employee modify job varchar(60);
删除gender列。
alter table employee drop gender;
表名改为user。
alter table employee rename to user;
或
rename table employee to user;
列名name修改为username
alter table user change name username varchar(20);
将image插入到username列的后面
alter table user modify image blob after username;
修改表的字符集为utf8
alter table user character set utf8;
3.6 删除表
DROP TABLE tab_name;
案例:
删除user表
drop table user;
4.操作表记录
4.1 新增
INSERT INTO tab_name [(column [, column...])] VALUES (value [, value...]);
插入的数据应与字段的数据类型相同
数据的大小应在列的规定范围内
在values后声明的值必须和values前声明的列相匹配
字符串和日期格式的数据要用单引号引起来
可以省略列的声明,值接按照表的列顺序指给定。
准备
create table employee(
id int primary key auto_increment,
name varchar(20) unique,
gender char(1) not null,
birthday date,
entry_date date,
job varchar(20),
salary double,
resume text
);
案例
向员工表中插入三条数据
insert into employee (id,name,gender,birthday,entry_date,job,salary,resume)
values (null,'刘备','m','1999-02-15','1999-03-01','ceo',9998.0,'这是老板~');
insert into employee (id,gender,name,birthday)
values (null,'m','关羽','2000-02-03');
insert into employee
values (null,'张飞','f','2000-09-09','2000-10-01','杀猪',998.0,'一天不杀猪浑身难受');
4.2 MySql乱码问题
客户端和服务器通信时可以通过set names xxx命令告知服务器和当前客户端交互时应该采用的编码。
如果不指定 则默认取值为服务器操作系统编码。
当客户端访问数据库表中数据时,数据库服务器将使用表的编码读取表底层二进制转换为字符,再用服务器认为的客户端编码转换为二进制发送给客户端,客户端收到数据后用客户端编码解析,从而得到正确的字符。
如果客户端和服务器通信时,客户端编码和服务器认为的客户端编码不一致,会产生乱码。
此时应手动设置set names xxx来解决乱码。

4.3 修改表记录
UPDATE tab_name SET col_name1=expr1 [, col_name2=expr2 ...] [WHERE where_definition]
UPDATE语法可以实现对表记录的修改
SET子句指定要修改哪些列,要给予哪些值。
WHERE子句指定修改符合什么条件的表记录中。
如没有WHERE子句,则修改所有的行。
案例
~将所有员工薪水修改为5000元。
update employee set salary=5000;
~将姓名为‘张飞’的员工薪水修改为3000元。
update employee set salary=3000 where name = '张飞';
~将姓名为‘关羽’的员工薪水修改为4000元,job改为“耍大刀”。
update employee set salary=4000,job='耍大刀' where name='关羽';
~将刘备的薪水在原有基础上增加1000元。
update employee set salary=salary+1000 where name = '刘备';
4.4 删除表记录
DELETE FROM tab_name [WHERE where_definition]
where用来指定要删除符合那些条件的表记录
如果不使用where子句,将删除表中所有数据
delete语句不能删除某一列的值(可使用update)
delete语句仅删除记录,不删除表本身。如要删除表,使用drop table语句。
TRUNCATE TABLE tab_name
语句也可以删除表中数据,它和delete有所不同。
delete是一条条删除记录,truncate是摧毁整表再重建相同结构的表,truncate效率更高。
案例
删除表中名称为’张飞’的记录。
delete from employee where name = '张飞';
删除表中所有记录。
delete from employee;
使用truncate删除表中记录。
truncate table employee;
4.5 查询表记录
i.准备
create table exam(
id int primary key auto_increment,
name varchar(20) not null,
chinese double,
math double,
english double
);
insert into exam values(null,'关羽',85,76,70);
insert into exam values(null,'张飞',70,75,70);
insert into exam values(null,'赵云',90,65,95);
insert into exam values(null,'张三丰',82,79,null);
ii.基本查询
SELECT [DISTINCT] *|{column1, column2. column3..} FROM tab_name;
select 指定查询哪些列的数据。
column指定列名。
*号代表查询所有列。
from指定查询哪张表。
DISTINCT可选,指显示结果时,是否剔除重复数据
案例
查询表中所有学生的信息。
select id,name,chinese,math,english from exam;
select * from exam;
查询表中所有学生的姓名和对应的英语成绩。
select name,english from exam;
查询所有英语成绩并过滤重复数据。
select distinct english from exam;
在所有学生分数上加10分特长分显示。
select id,name,chinese+10,math+10,english+10 from exam;
统计每个学生的总分。
select name,ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0) from exam;
使用别名表示学生总分。
select name,ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0) as zf from exam;
select name,ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0) zf from exam;
iii.条件查询
SELECT [DISTINCT] *|列名 FROM tab_name [WHERE where_definition]
其中where中可以使用如下运算符声明过滤条件:
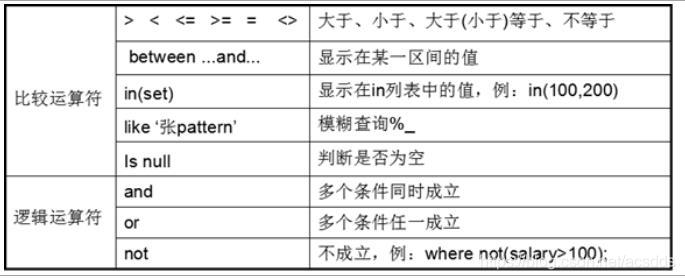
*Like语句中,% 代表零个或多个任意字符,_ 代表一个字符,例first_name like ‘_a%’;
案例
查询姓名为关羽的学生成绩
select * from exam where name='关羽';
查询英语成绩大于90分的同学
select * from exam where english > 90;
查询总分大于230分的所有同学
select name,ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0) as zf from exam
where ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)> 230;
查询语文分数在 80-100之间的同学。
select name,chinese from exam where chinese between 80 and 100;
查询数学分数为75,76,77的同学。再查询分数不在这个范围内的同学
select name,math from exam where math in (75,76,77);
select name,math from exam where math not in (75,76,77);
查询所有姓张的学生成绩。
select * from exam where name like '张%';
select * from exam where name like '张_';
select * from exam where name like '张__';
查询数学分>70,语文分>80 且英语成绩为null的同学。
select * from exam where math>70 and chinese > 80 and english is null;
select * from exam where math>70 and chinese > 80 and english is not null;
iv.排序查询
SELECT [DISTINCT] *|列名 FROM tab_name ORDER BY column_name ASC|DESC;
ORDER BY 指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的别名。
ASC 升序、DESC 降序
ORDER BY 子句应位于SELECT语句的结尾
案例
对英语成绩排序后输出。
select * from exam order by english;
对总分排序按从高到低的顺序输出
select name,ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0) as zf from exam
order by zf desc;
对姓张的学生成绩排序输出
select name,ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0) as zf from exam
where name like '张%' order by zf;
v.聚合函数
| COUNT() | 返回选取结果集中行的数目 |
|---|---|
| SUM() | 返回选取结果集中所有值的总和 |
| AVG() | 返回选取结果集中所有值的平均值 |
| MAX() | 返回选取结果集中所有值的最大值 |
| MIN() | 返回选取结果集中所有值的最小值 |
案例
统计一个班级共有多少学生?
select count(*) from exam;
select count(id) from exam;
select count(1) from exam;
统计数学成绩大于75的学生有多少个?
select count(1) from exam where math>75;
统计总分大于230的人数有多少?
select count(1) from exam where ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)>230;
统计一个班级数学总成绩?
select sum(math) from exam;
统计一个班级语文、英语、数学各科的总成绩
select sum(chinese),sum(math),sum(english) from exam;
统计一个班级语文、英语、数学的成绩总和
select sum(chinese)+sum(math)+sum(english) from exam;
统计一个班级语文成绩平均分?
select avg(chinese) from exam;
求一个班级数学平均分?
select avg(math) from exam;
求一个班级总分平均分?
select avg(ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)) from exam;
求班级最高分和最低分
select max(ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)) from exam;
select min(ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)) from exam;
vi.分组查询
SELECT [DISTINCT] *|列名 FROM tab_name GROUP BY column[,comumn..] [HAVING ...]
分组操作可以按照指定的一个或多个列的值将数据进行分组操作
同一个组内的多条数据会"摞"在一起,只显示一条,其他的数据没有消失只是"压"在这条数据之下看不到
如果没有分组操作,聚合函数作用于整个查询结果
如果有分组操作,聚合函数作用于每个组队内部
where和having都可以用来过滤数据
where是分组之前过滤,不能出现聚合函数
having是分组之后过滤,可以使用聚合函数
准备
create table orders(
id int,
product varchar(20),
price float
);
insert into orders(id,product,price) values(1,'电视',900);
insert into orders(id,product,price) values(2,'洗衣机',100);
insert into orders(id,product,price) values(3,'洗衣粉',90);
insert into orders(id,product,price) values(4,'桔子',9);
insert into orders(id,product,price) values(5,'洗衣粉',90);
案例
对订单表中商品归类后,显示每一类商品的总价
select product,sum(price) from orders group by product;
查询总价大于100的商品的名称和总价
select product,sum(price) from orders group by product having sum(price)>100;
查询单价小于100而总价大于100的商品的名称.
select * from orders where price<100 group by prodcut;
vii.分页查询
SELECT [DISTINCT] *|列名 FROM tab_name LIMIT n,m;
在查询结果中筛选出从第n条记录开始(不包含第n条记录)获取之后的m条数据准备
create table user (id int,name varchar(20),age int);
insert into user values (1,'aaa',19);
insert into user values (2,'bbb',23);
insert into user values (3,'ccc',32);
insert into user values (4,'ddd',18);
insert into user values (5,'eee',22);
insert into user values (6,'fff',27);
insert into user values (7,'ggg',39);
案例
从user表中查询年龄最小的3个用户
select * from user order by age limit 0,3;
select * from user order by age limit 3,3;
4.6 查询sql编写技巧
查询sql的关键字书写顺序
select…from…where…group by…having…order by…limit
查询sql的关键字执行顺序
from…where…group by…having…select…order by…limit
编写技巧 :
根据需求挑选关键字,按照书写顺序依次排列关键字
按照关键字的执行顺序填空
5.数据库的备份和恢复
5.1 备份数据库
在cmd窗口中使用mysqldump 备份数据库
mysqldump -h 主机名 -P 端口号 -u 用户名 -p db_name > c:/xxx.sql
-h 默认取值localhost
-P 默认取值3306
5.2 恢复数据库
方式一:
cmd窗口中使用mysql命令 恢复数据库
注意,只能恢复数据库中的数据,不能恢复数据库本身!所以要提前建好数据库.
mysql -h 主机名 -P 端口号 -u 用户名 -p db_name < c:/xxx.sql
-h 默认取值localhost
-P 默认取值3306
方式二:
在mysql命令下,source xxx.sql,这个命令的作用就是,在当前位置执行sql文件中的所有的sql.
首先新建出数据库,进入数据库,在source执行备份的sql文件即可。
source c:/xxx.sql
6.外键约束
关系型数据库可以保存数据和数据之间的关系。
数据以表记录的形式保存。
数据之间的关系以表和表之间的关系的形式保存。
表和表之间的关系通过外键字段来维系,通过外键约束来约束。
一旦任何操作违背的外键约束,数据库会报错,阻止该操作的执行,防止出现数据无法对应的情况。

6.1 增加外键
i.建表时指定外键关系
[CONSTRAINT <外键名>] FOREIGN KEY (字段名 [,字段名2,…]) REFERENCES <主表名> (主键列1 [,主键列2,…])[on delete restrict] [on update restrict];
*RESTRICT : 只要本表格里面有指向主表的数据, 在主表里面就无法删除相关记录。
*CASCADE : 如果在foreign key 所指向的那个表里面删除一条记录,那么在此表里面的跟那个key一样的所有记录都会一同删掉。
案例
create table dept(
id varchar(10) primary key,
name varchar(20)
);
insert into dept values ('001','人事部');
insert into dept values ('002','财务部');
insert into dept values ('003','销售部');
insert into dept values ('004','科技部');
create table emp(
id varchar(10) primary key,
name varchar(20),
did varchar(10),
foreign key(did) references dept(id)
);
insert into emp values ('999','孙悟空','001');
insert into emp values ('888','哈利波特','001');
insert into emp values ('777','萨达姆','002');
insert into emp values ('666','特朗普','003');
insert into emp values ('555','朴乾','004');
insert into emp values ('444','赵四','005');
update emp set did='005' where name='哈利波特';
delete from dept where id = '001';
ii.通过修改表增加外键关系
ALTER TABLE tab_name ADD [CONSTRAINT fk_name] FOREIGN KEY(字段名) REFERENCES 表名(字段名) [on delete restrict] [on update restrict];
*RESTRICT : 只要本表格里面有指向主表的数据, 在主表里面就无法删除相关记录。
*CASCADE : 如果在foreign key 所指向的那个表里面删除一条记录,那么在此表里面的跟
那个key一样的所有记录都会一同删掉。
案例
create table dept2(
id varchar(10) primary key,
name varchar(20)
);
insert into dept2 values ('001','人事部');
insert into dept2 values ('002','财务部');
insert into dept2 values ('003','销售部');
insert into dept2 values ('004','科技部');
create table emp2(
id varchar(10) primary key,
name varchar(20),
did varchar(10)
);
insert into emp2 values ('999','孙悟空','001');
insert into emp2 values ('888','哈利波特','001');
insert into emp2 values ('777','萨达姆','002');
insert into emp2 values ('666','特朗普','003');
insert into emp2 values ('555','朴乾','004');
alter table emp2 add foreign key (did) references dept2(id);
insert into emp2 values ('444','赵四','005');
update emp2 set did='005' where name='哈利波特';
delete from dept2 where id = '001';
6.2 删除外键
ALTER TABLE tab_name DROP FOREIGN KEY fk_name
案例
show create table emp;#查询外键名
alter table emp drop foreign key emp_ibfk_1;#删除外键