转载 | 认知推理:从图表示学习和图神经网络的最新理论看AI的未来
近年来,图表示学习(Graph Embedding)和图神经网络(Graph Neural Network, GNN)成为网络数据分析与应用的热点研究问题,其特点是将深度神经网络技术用于网络结构的建模与计算,诞生了以 DeepWalk、LINE 和 node2vec 为代表的图表示学习技术,以 GCN 为代表的图神经网络,能够利用分布式表示方案实现对网络中的节点、边及其附带的标签、属性和文本等信息的建模,从而更好地利用网络结构进行精细建模和深度推理,相关技术已经被广泛用于数据挖掘、社会网络分析、推荐系统、自然语言处理、知识图谱等领域。
为了推进国内在该领域的发展,由中国中文信息学会社会媒体处理专委会和北京智源人工智能研究院联合主办的“图神经网络在线研讨会 2020”于 3 月 29 日下午召开,邀请了宋国杰、沈华伟、唐杰、石川四位国内著名学者介绍图表示学习和图神经网络的最新理论进展和应用探索。
清华大学计算机系教授、系副主任,中国中文信息学会社会媒体处理专委会常务副主任,智源研究院学术副院长唐杰老师进行了主题为“图表示学习和图神经网络的最新理论进展”的分享,主要介绍了图神经网络及其在认知推理方向的一些进展。
唐杰老师主要研究兴趣包括人工智能、认知图谱、数据挖掘、社交网络和机器学习,主持研发研究者社交网络挖掘系统 AMiner 等。
以下内容是根据唐杰老师的演讲进行的总结。本文分为引言、回顾网络表示学习、现在是GNN时代、GNN+推理会产生什么、GNN的挑战与未来五部分。
一、引言
我们正在经历第三次人工智能浪潮,世界上很多国家都推出了相应的战略和发展规划。但也有人说第三次人工智能浪潮已经接近尾声,马上就要到达“冰点”,第四次浪潮已经在酝酿之中。关于下一次浪潮的具体内容,今天暂时不做过多的讨论,我们先剖析一下这次浪潮的具体情况。
AI 这几年发展很快,其中一个重要原因是产业界的很多研究者、资源加入进来,一起推动 AI 的发展,如谷歌的 AlphaGo 和无人驾驶汽车。国内的相关企业也在蓬勃发展,从我的角度来说,我们做的事和硬件的关联没那么紧密,很多的是偏软件的东西,比如在图片识别过程中,我们更关注怎么将其中的语义信息抽取、识别出来,怎么把文本的语义信息和图片的语义信息混合起来做计算等。比如下图,通过将一张狗的图片减去关键词“dog”,再加上关键词“cat”,从而将猫的图片识别出来。

这就是一个典型的多媒体的数据,在两个方面怎么做处理是我们当下最关心的一些的问题。人工智能在这方面快速发展,总结一下:这个时代是一个感知的时代,AI 到目前为止基本上解决了所有的感知问题。如果回顾过去的话,会发现计算机主要是做一些存储和计算的工作;如果展望未来的话,我们想倡导的应该是在认知方面怎么把计算、推理做到神经网络中。
现在这个感知时代最大的特点是算法。下面这张图汇总了最近几十年 AI 算法的一些进展。
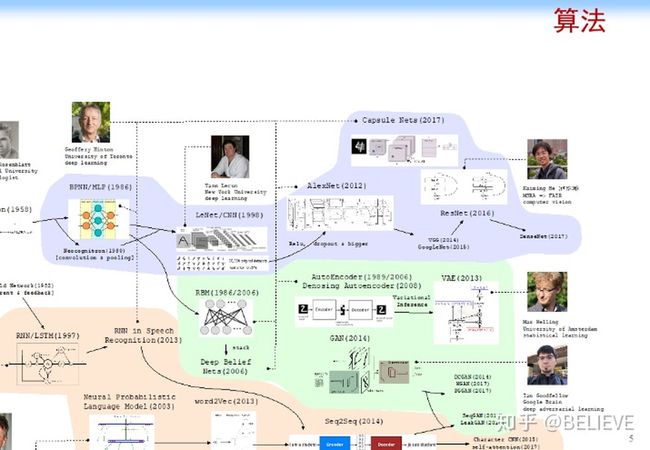
这张图最上面的浅紫色的部分大致梳理了卷积神经网络的发展历史。1953 年,感知机(Perceptron)被提出来。1986 年,多层感知机(Multi-Layer Perception,MLP)开始出现。1998 年,Yann Le Cun 提出手写字体识别模型 LeNet 及卷积神经网络(CNN),但是当时 CNN 并没有大规模被人关注,因为当时大火的支持向量机(SVM)压住了 CNN 的风头。直到 2012 年,Geoffrey Hinton 的学生在 LeNet 的基础上加上了 ReLU、Dropout 等内容,实现了 AlexNet,把 CNN 的效率大规模提高,才推动了这个方向的发展。
第二部分淡绿色部分的内容表示自编码(AutoEncoder),这部分不是今天的重点,不再展开。
第三层浅黄色的部分可以被称为循环神经网络(Recurrent Neural Network, RNN)的发展。放大来看,它的理论和上面的一样优美,它其实就是一个概率统计模型,即把神经网络用图的方式连接起来,虽然最早期的时候大家做的都是序列化的模型,如 RNN,或者是在语言模型(Language Model)上面做一些相关的工作,甚至是Seq2Seq,但是最近更多的工作是在图上,如唐建他们有一篇文章就是把图模型(Graphical Model)加上神经网络,一起连接起来,于是就变成一个基于图模型的神经网络(Graphical Model based Neural Network)。
如果结合最上面浅紫色的内容和浅黄色的内容,即把卷积神经网络加上图模型,这形成我们今天经常说的图神经网络的基本思想。
可以看出来,图神经网络有很长的历史,是一个非常简单的机器学习算法在图上的一个自然地延伸。为什么现在大家觉得图神经网络火得不行?好像所有的人都在研究图神经网络?也有些人说这个东西是简单地把某些东西用在另一个数据集上?其实机器学习所有的发展历史都有这样一个过程,它最早期都是从一个简单的单样本分析开始,然后逐步复杂化,最后再把样本与样本之间的关联关系考虑进来,如图神经网络就是用一个简单的思路把它结合起来。最早的线性条件随机场(Conditional Random field,CRF)、最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)等模型的思路都是在原来的思路上扩展的。GNN就是神经网络在图上的一个自然地延伸。当然,这一波自然延伸的结果是必然有下一波阶跃。如原来在图模型上有了 CRF、MEMM 以后,概率统计模型基本到了一个极致,后续延伸自然就到了下一个阶段。
最下面是一个强化学习(Reinforcement Learning),这里也不再多讲。
回到我们的背景。既然有 CNN、有大量网络化的数据,就可以做很多相关的研究。
首先,这些数据的规模非常大。如阿里巴巴、Facebook、新浪微博等积累了超大规模的社交网络数据,如果泛化来看,我们还有经济方面的网络(Economic networks)、生物医学方面的网络(Biomedical networks)……甚至还有大脑中神经元的网络(Networks of neurons),这里面有很多相关的应用,如果从机器学习的角度归纳一下相关的应用,可以发现以下几个核心的任务。

下面详细展开介绍一下。
(1)点分类,做一个点的表示,然后做预测它的类型是什么。
(2)两个点的链接生成,如两个点之间有没有可能生成一条边,或者再放大来看,看有没有可能找到一个子图,或者找网络相似度。这个方面在过去有很多相关的研究,今天我们会大概涉猎这些东西。这方面最早的研究可以追溯到 Geoffrey Hinton 研究的分布式表示(Distributed representation),但是这个概念在当时被 SVM 压制,一直没有火起来,直到 2013 年 Tomas Mikolov 提出了非常快速的算法 Word2vec,才迅速让深度学习算法在文本分析领域快速落地。到了 2014 年,Bryan Perozzi 很巧妙地将 Word2vec 直接用到了神经网络中,开启了在网络中做表示学习的浪潮,后来唐建、Yann Le Cun、Max Welling 等都做出了大量的工作,最后整个这方面的研究形成了我们今天看到的 GNN,如果放到更高的层面去看,就是网络表示学习这么一个领域。
二、回顾网络表示学习
首先回归一下网络表示学习。网络表示学习在本质上就是给定一个网络,我们要学习里面每一个节点在低维空间上的一个表示。我们希望当网络在低维空间时,如果两个节点之间的距离很近,它们就一定比较相似,如果它们不是同一个类型的节点,距离就应该比较远。
这个问题为什么比较难呢?这是因为:(1)如果我们用 CNN 或者相关的算法在图片上做学习,由于图片是典型的二维的、有上下之分,每个点上、下、前、后、左、右是什么很清楚,但是在网络中,它是一个复杂的拓扑结构,甚至没办法用上、下描述,只能用拓扑结构来说明,或者说两个节点的距离有多远,而没有一个严格的空间的概念。(2)节点之间没有文本那样的先后关系;(3) 整个网络是非常动态的,并且可能有一些相关的信息、相关的属性。比如做一个人的行为分析的话,某个节点可能有很多的属性信息,还有很多网络结构的属性和信息,我们可以把网络结构的表示学出来,还可以把网络属性的表示学出来,这就有两种不同的表示。有时候人们可能还发出一些图片、语音等其他媒体的信息,怎么把这些表示都学出来非常困难。
最早在网络上做表示学习是把整个研究规约到一个很简单的 Word2vec 问题上,就是我说的 DeepWalk 的思路,即用 word2vec 的思路来做网络的表示学习。这个思路非常简单,即 word2vec 就是上下位,如果上下位相同的单词,他的意思就比较相似,于是学出来的表示也比较相似,如下图所示。

在网络表示学习中,DeepWalk 的思路是:既然节点没有先后关系,就做一个先后关系。从任意一个节点开始,在上面跑一个随机游走(Random Walk),跑完了以后可以形成了一个序列,形成一个和 DeepWalk 处理文本一样的上下位信息,于是 v1 这个节点就由 v3、v4、v5、v6 作为它的上下位,剩下给一个随机的低维表示,然后在上面进行 SkipGram with Hierarchical softmax 的一个学习,最后就可以得到一个希望的表示结果,如下图所示。
这里做 SkipGram with Hierarchical softmax 是为了提高计算速度,不再详细说明。最后的参数学习可以用一个基于梯度的学习很快做到。
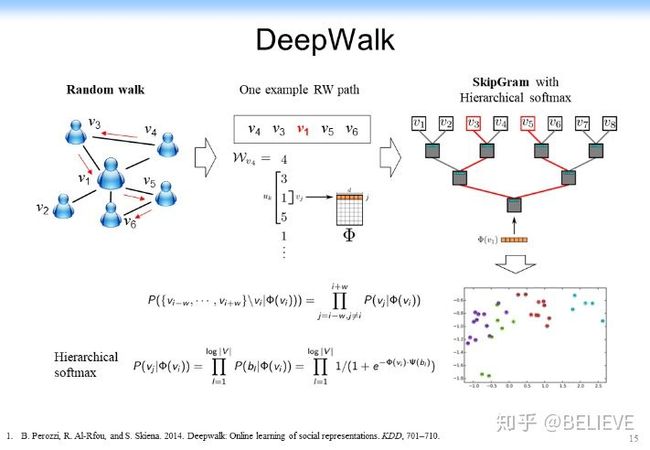
这篇文章最初在当时并没有引起大规模的关注,但是它开启了一个在网络中做表示学习的新纪元。最初大家觉得在网络中做表示学习是一件很麻烦的事,后来发现神经网络可以用在网络中,可以学习每个节点的表示,并且学到的表示可能可以用于不同的网络,如 Blog Catalog,使得它的效果还不错。后来又试了其他的网络,如 Youtube 中的网络,发现效果也不错。后来就引起了大规模的相关的研究,讨论怎么来提高在网络上做表学习的效果。于是大家就分析 DeepWalk 的一些缺点。
首先它的上下文是固定的,而它的随机游走并没有考虑到网络的特性,于是后面一大堆的研究,如 LINE 等。下图中 5 和 6 这两个节点根据我们人的行为来看是很相似的。5 和 6 有四个相近节点(1、2、3、4),但是 6 和 7 是直连的。如果用刚才的 DeepWalk,即 RandomWalk 在上面随机游走,6 和 7 可能距离反而更近,它的相似度反而更高。
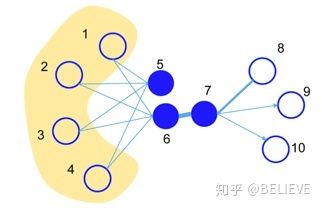
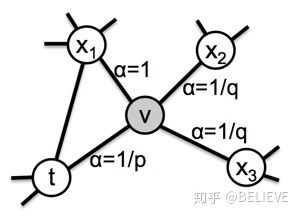
但是根据人的直觉,5 和 6 显然更相似,于是 LINE 就加上了一个二阶的相似度,有一阶有二阶。后来研究者又把它扩展到一个异构网络(PTE)上,即这个网络不是单纯的一个网络,而是一个异构网络。后来有人又给它加上了社交的属性(Social Information)。在 RandomWalk 中,左边三角形 x1vt 是一个闭合三角形,而右边是一个开合的三角形,开合的三角形和闭合的三角形的相似度或者 RandomWalk 的度应该不一样,于是就加上了这么一个 biased RandomWalk。把 Performance 在社交的数据又进一步提高。
刚才给大家讲了这么多 Natural in Bedding 的一些很基本的算法都是感知的,它们本质上到底是什么呢?沈华伟(中国科学院计算技术研究所研究员)老师讲的图神经网络给出了一个很好的解释,其实它们在本质上都是在做信通的处理。
通过数学分析我们发现最简单的网络表示学习在本质上都是在做一个矩阵分解,在做一个奇异值分解(SingularValueDecomposition,SVD),只是分解的形式不一样,如下图所示。DeepWalk 分解的是第 1 个式子,LINE 分解的是第 2 个式子,PTE 分解了一个异构的网络,node2vec 分解了一个更复杂的网络,因为它里面考虑到了三个节点形成的矩阵。

这样的话我们就可以把刚才给大家看的 DeepWalk 的过程给定网络,找到这种随机游走的 Context,然后再做 Skip Graphs,直接把这两步组合在一起就变成一个矩阵分解,通过这个矩阵分解可以直接得到最后的结果。这里面我们给出了一个严格的数学分析,最后就发现这个 DeepWalk 在本质上就在分析下图下方的东西。

更有意思的 LINE 也是在分解一个矩阵,而且这个矩阵和 DeepWalk 随机游走的矩阵比起来,两个式子非常相似,但又不一样。仔细看一下会发现,如果把 DeepWalk(其实就是 Windows Size,也就是我们的上下文的长度)设成 1,它在本质上一下子就等于 LINE 了。于是从这个角度上来说,LINE 就变成 DeepWalk 的一个特例。我刚才讲到 PTE 是把 LINE 扩展到了异构网络,从某种角度上来说,你把异构网络变成一个同构网络,变成一个超级大的同构网络。于是 PTE 又可以变成一个 LINE 的特例,从某种角度上来说,PTE 又变成了一个 DeepWalk 的一个特例。

此外,node2vec 是一个 Biased Random Walks。原来我们是说随机游走从u这个节点往任何节点的随机游走都是一样的,如下图所示。但是现在 node2vec 给出了另外一个思路:让宽度优先的随机游走,可能跟深度优先的随机游走的概率不要一样。或者简单说,闭合三角形跟开合三角形的随机游走的概率不一样,于是在本质上就相当于做了两件事:一个是 local 的随机游走,一个是 global 的随机游走。因为开合的它更容易游走到其他的那些子领域,你比如说左边是个子领域,右边是另一个子领域,于是它相当于开合的就游走到两个子领域里面去了,而闭合的就更容易在同样一个子领域里面流走。这就是 node2vec 很巧妙的地方。node2vec 的思路非常简单,优美的地方是我们同样可以通过一个数据分析,把它归约到一个矩阵分解上。

这样就把刚才的矩阵分解统一起来了。我们可以说所有的这种网络表示学习或者说很多表示学习算法都可以归约到一个简单的矩阵分解,或者说 SVD 的一个过程。
但是这样又出现了新的问题:我们现在怎么来做 GNN 或者图神经网络呢?毕竟在图神经网络中要结合网络化的信息,如刚才提到的网络表示学习结合的是一个上下文信息,用上下文信息做这种网络表示学习,怎么真的把这种网络结构化的信息利用上,而且要让他速度特别快呢?
我们首先做了一个很巧妙的事情,我们做了一个被称为 ProNE 的算法,如下图所示。

这个算法是什么呢?首先,构造一个非常稀疏的矩阵;然后,在这个稀疏矩阵里面用刚才的方法做一个矩阵分解,做一个 SVD 分解;最后,在 SVD 分解的基础上做普传播,也就是说我们来做传播,于是每一个节点传播的东西就变成了表示学习学到的结果,而不是传播本身。于是就相当于把表示学习学到的低维表示在图上做传播。
大家可以想象一下,如果我们做一个特别快速的 SVD 分解(如做一个线性的算法,基本做到点和边成线性关系),同时,把刚才学到的低维表示在所有的边上做传播,事实上跟这个边又呈线性关系,于是整个算法可以做成一个跟网络节点和边呈线性关系的一个算法,这样的话整个算法的模型会就可以做得非常快。有人提到说这个可能复杂度很高,对此我要再解释一下,如果我们做一个非常快速的 SVD 分解,我们可以做一个线性算法,比原来传统的 SVD 算法快两个数量级,它基本上是个线性关系。举一个例子。下图是我们跑出来的一个结果。我们是 ProNE 加上普传播得到的一个结果,可以看到结果比原来最快的LINE快一个数量级,比 node2vec 快两个数量级。而且我们最近还发现另外一个算法,它可以比原来 randomize 的 TSVD 分解还要再快一个数量级,甚至加上谱传播都可以比其他两个速度还要快。

而且在超大规模的网络中,比如说百万级的网络上,我们基本上几分钟就可以把它全部跑完,把网络表示的结果全部跑完。更有意思的是效果还可以做的非常好。大家可以看一下下面这个效果,我们基本上不用任何的普传播,只用 SMF 时,即只用稀疏矩阵分解的时候,就可以做到跟原来的算法得到的效果差不多。如果用了的话,就比原来的算法明显好得多。这样就很优美。我们可以在拥有上亿的点的图上,用单机花 29 个小时跑出一个结果,比原来的结果的精度还要好、速度还比较快。
以上就是快速回顾了一下网络表示学习的一些东西。这里主要是讲的 NetMF(也就是矩阵分解)及传播的一些东西,如下图所示。下图中间这一部分没有讲,大家有兴趣也可以去看一下。我们主要是把 NetMF 做了稀疏化,做了一个理论分析,给大家可以在理论上做了一个保证。

三、现在是 GNN 的时代
今天想跟大家分享一下更重要的是:现在其实是在一个 GNN 的时代。GNN 从 2017 年 Max Welling 的论文发表出来以后,已经越来越火,越来越多人提出了很多问题,说现在已经进入一个 GNN 的“坑”。那么,GNN 的本质是什么呢?核心、简单来讲,GNN希望把原来的浅层的这种网络变得更加深层。
这个问题现在其实是个悖论。首先,很多人说我们要把原来的 Shallow 的神经网络变成深度的神经网络,这样可能会提高效果,但是这导致了两个严重的问题。
第一个严重的问题是网络到底要多深才算深?比如说在网络中,假如我们真的做了很多深层次的话,如果每一次深层次的都是在做一个邻居节点的传播,这时候深层次、很深的网络会导致这个信息就扩散整个网络了,这个时候就导致一个过平滑(over-smooth)的问题,而不是过拟合 (Overfitting)。另外一个问题就是整个网络的深度学习假如都像刚才都是矩阵分解,如果没有一个非线性的变化,所有的矩阵分解就让它深度下去,它其实本质上还是一个矩阵分解。这个到底是怎么回事呢?我们在这里做一定的分析。在 GNN 中我们其实分解的就是下图这样一个简单的矩阵。这是一个邻接矩阵,H 是上一层的隐变量,W 是权重,激活函数是非线性的。其实之前有研究已经证明了,GCN 如果没有这个激活函数的话,整个 GCN 其实可以退化成一个非常简单的矩阵,而且效果还有可能更好。所以这也是一个悖论,等一下我们也在后面再探讨一下。

在探讨之前,我们先快速说明一下 GCN 的本质。GCN 的本质其实就是在一个网络中把邻居节点的表示信息放到自己当前节点上。比如说对于下图中 v 节点来讲,它有邻居节点 a、b、c、d、e,每一个节点可能都有一个表示(从 ha 到 he)。
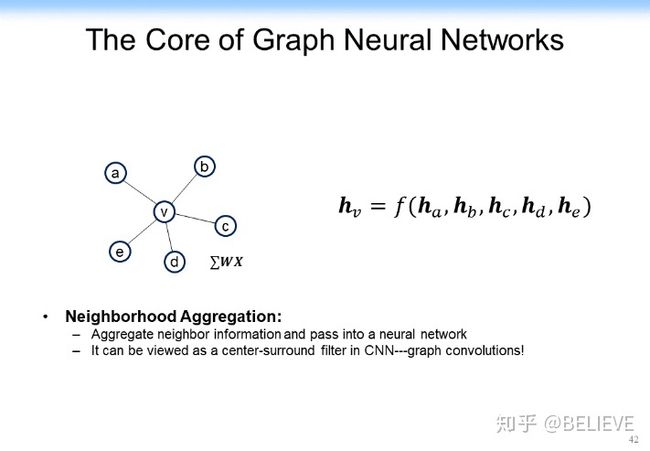
怎么把邻居节点的引表示通过某种方法或某种函数(如 f 函数可能是线性变化,也可能是个非线性变化),把它 Aggregate 到当前节点,得到 hv。当然,从下图所示的内容里表示我们就可以看出一个结果:左边给出了一个在邻居节点身上做的卷积,得到对当前节点进行卷积的结果。

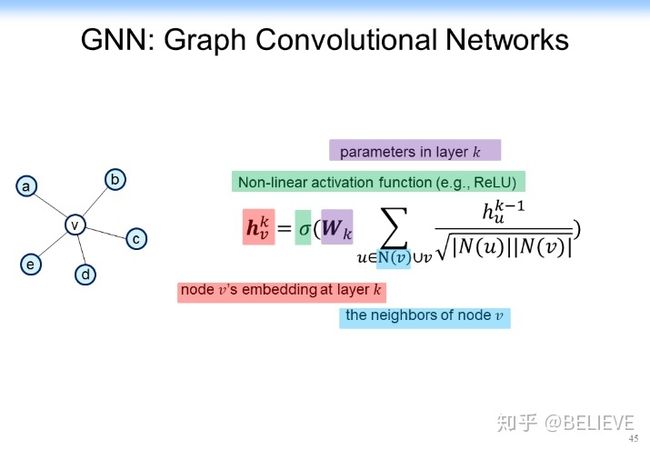
我们可以构造出一个加上了非线性的激活函数的函数,如下图所示。是权重,是邻居节点。是当前节点的表示, v 是当前节点,另外还有一个非线性的激活函数。
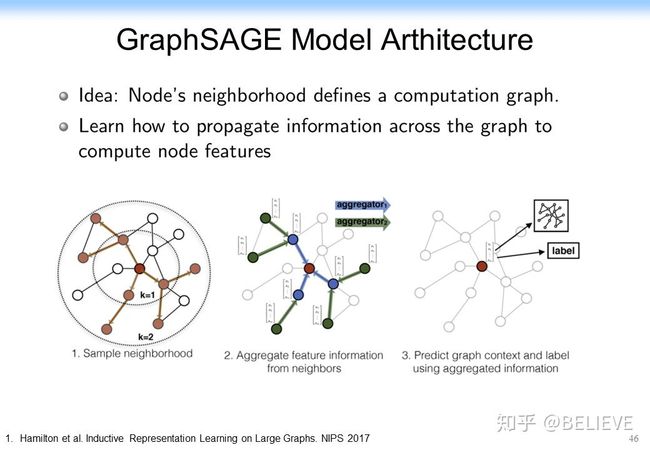
基于这样的思想,后来在最早的 GCN 相关的论文上也有很多的延续,如 GraphSage。GraphSage 的思想非常简单,它把原来单纯的当前节点和其他所有节点的聚合整合到一起了,变成当前节点的表示和其他所有节点的表示连接在一起,如下图所示。这样的话效果反而提高了。
这个思路后来又被 GAT 给打败了,GAT 是什么?我们现在 aggregate 的时候,也就是每个节点信息往中间节点传的时候,它的权重不一样。从 Social network 的角度来说,它的本质就是影响力不一样,就相当于某个节点对其他的不同的节点的影响是不一样的。怎么把这种影响力在网络中度量,是社交网络区别于其他很多网络一个非常重要的方面。当然,从数学上可以把 GCN 看作是下图上方的式子,而 GAT 是下图下方的式子,可以看到唯一的变化就是加上了一个 Attention 参数,这样的话可以看一些初步的结果,加上 Attention 参数的效果确实比原有算法的效果要好。

我们现在再次问自己一个问题:所有的这些卷积网络的本质是什么?刚才说了,网络表示学习的本质是一个矩阵分解,那卷积网络的本质是什么?而且卷积网络面临着很多问题,除了我们经常说的机器学习普遍存在的过拟合问题,这里还存在更重要的问题——过平滑及不健壮的问题。因为在网络中可能存在链接,甚至很多噪声链接,这些链接可能会大幅影响效果,这个时候该怎么办?
我们先来看一看下图的分析。GCN 每一层的传播在本质上都是一个矩阵分解,从前面的分析可以看到,对矩阵分解其实可以进一步做一定的分析,把矩阵分解变成一个信通问题。而借助信通的思路其实还有一个很有意思的扩展,我们可以把网络中的邻接矩阵 A 做一定的变换,我们可以在前面做一定的信通的变换,在后面也可以做信通的变换。这样的话整个网络其实可以变成一个 Signal Rescaling 的一个思路。
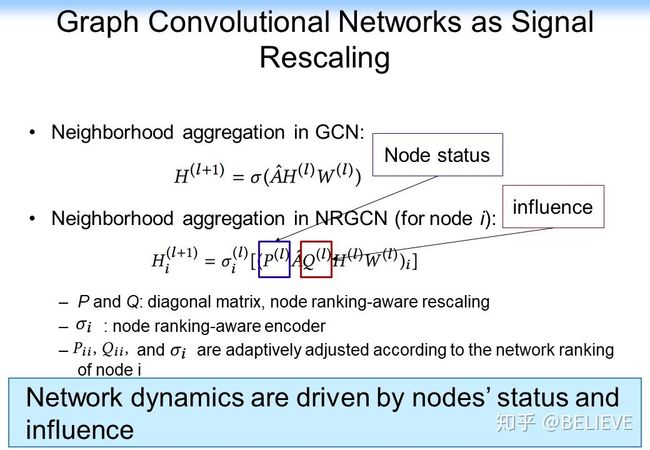
这样的好处是可以把原来的每一层都做一个矩阵分解直接变换成相关的一些变化,我们可以把网络中的节点的 status,或者网络中的影响力全部嵌入卷积神经网络。这样的话对每一层的卷积层都可以做一定的变换,它可以是多层的,甚至是可以做 Multi-head Propagation mechanism,还可以做 Multi-hop variants。如果我们去掉每一层的非线性函数,事实上 Multi-hop variants 就和单纯的 GCN 等价了。这样一个分析的思路就把前面所有的注意力机制,如 Node attention、Edge attention、K-hop edge attention 或 Path attention 全部归一化了起来。更优美的是基于这样的思想,其实我们在以后就可以不用研究刻意去研究 GCN 的这种结构、架构,而是去研究在 GCN 里的不同的操作。我们可以基于刚才的函数对里面的 P、Q 做变换,或者对 L 值直接做变换。这样的话我们就可以对整个 GCN 做三种操作:Rescale,Re-normalize、Propagate,如下图所示。

前面是前者,我们可以做加在 pre 上,也就是说我们在做拉普拉斯分解之前,可以先做一个 Rescale 把 P 升上去,也可以在做完拉普拉斯分解以后做 Re-normalize,还可以进一步再做一个 Post Propagation。于是我们自然就把 P、L、Q 给分解了。分解完了最大的好处是GCN就是一个简单的拉普拉斯矩阵的分解,而 GAT 既包括分解,也包括 normalization,还包括 Rescaling。而 ASGCN 同样可以被归约成一个 normalization,加上一个 propagation。大家可以看到这三个操作在不同的方法中,事实上都相当于这三个原子操作的一个组合。
我们还可以进一步看,GraphSAGE 就相当于构造了一个 L,它没有做 Rescaling,而是先做了一个 normalization,再做了一个 propagation。而 FastGCN 先做了 normalization,再做了一个 propagation,如下图所示。

甚至我们可以把所有的这些卷积网络的方法全部用 signal Rescaling 的方法把它统一起来,而统一的思想就是以上的三个操作,就用三个 operation 把所有的操作都给归一化起来,如下图所示。从这个角度上大家可以看到,在网络表示学习方面,我们把它归一化到矩阵分解,用矩阵分解把网络表示学习都给归一化起来了。而在卷积网络中或者是叫图神经网络(当然更多的是卷积网络)中,我们就用三个操作+矩阵分解,用矩阵分解把形式化统一,然后用三个操作把不同的方法全部给统一起来。于是这个时候我们有了一个统一的框架,基本上都是矩阵分解加不同的一个操作(这里更多的是 signal Rescaling)这么一个思路,再把它统一起来。

我们还做了一些实验。我们发现结果也比以前确实要好,如下图所示。

我们加上不同的操作以后,前面有 rescaling,post 叫 propagation,还有 normalization,我们用不同的操作加在上面可以组合成不同的方法。而这些不同的方法可以用一个 AutoML 的方法来做 Tune,这样就比原来归一化表示的其他方法的效果都要好。从效果上我们可以得到更好的一个结果。这样就可能解决“在数学上的分析很漂亮,我们都说是一个 signal Rescaling 的问题,但是我们怎么让结果真的比原来好很多,这个时候就有很大的一个麻烦”这个问题。关于这一部分的很多细节沈华伟老师讲了很多,所以我在这里跳过一些,有兴趣的可以查看相关的视频。
接下来我们来看一下最近的一些思路。最近大家都知道自然语言处理及很多其他领域中,预训练已经变成一个标配了,BERT 从 2018 年底出现到现在已经打败了很多相关的一些方法,甚至已经出现了关于 BERT 的一系列相关的方法(BERTology),如 XLNet, Roberta, ALBert, TinyBERT 等。在计算机视觉(CV)方向也有很多相关的研究,最近一个很重要的进展就是 Contrastive Learning,即利用无监督学习(Unsupervised Learning)的方法或者是一个非常简单的 Contrastive Learning 的思路来做的效果更好。MoCo 在 2019 年年底出来,基本上一下子就做到无监督学习的结果基本上就可以跟监督学习(Supervised learning)的结果差不了太多。后来 Geoffrey Hinton 团队的 SimCLR 又打败了 MoCo,最近 MoCo2 又把效果进一步提高,打败了 SimCLR。它们的核心思想都 Contrastive Learning,本质上都是在用 self learning 来做表示学习,类似于做一个预训练。
我认为这方面是一个可能的方向,未来在这方面可能会有一些发展。但是怎么跟网络化的数据、跟图挂钩,就是把图跟预训练挂钩,这方面其实还是一个很大的挑战。所以总体来讲,在 GNN 时代,如果光从算法的来考虑,我觉得值得考虑的其实有两大核心的挑战:(1)怎么把预训练思路,包括刚才的 Contrastive Learning 和图结合起来。其实现在还没有一个特别里程碑式的进展。(2)我们在这里面怎么解决它过平滑、过拟合、不健壮的问题。这几个问题怎么解决是很难的问题。
四、GNN+推理会产生什么
我们现在再来看一看 GNN 怎么和推理结合起来。说到推理,可能有些人说这个问题太大了,所以我们先从一个非常简单的问题(Multi-hop Question Answering,QA)来说。
这个问题是个自然语言处理的问题。假如我们要解决一个问题“找到一个 2003 年在洛杉矶的 Quality 咖啡馆拍过电影的导演(Who is the director of the 2003 film which has scenes in it filmed at The Quality Cafe in Los Angeles)”。如果是人来解决这个问题的话,可能是先追溯相关的文档,如 Quality 咖啡馆的介绍文档,洛杉矶的维基百科页面等,我们可能会从中找到相关的电影,如 Old School,在这个电影的介绍文档里面,我们可能会进一步找到该电影的导演 Todd Phillips,经过比对电影的拍摄时间 2003 年,最终确定答案是 Todd Phillips,具体流程如下图所示。
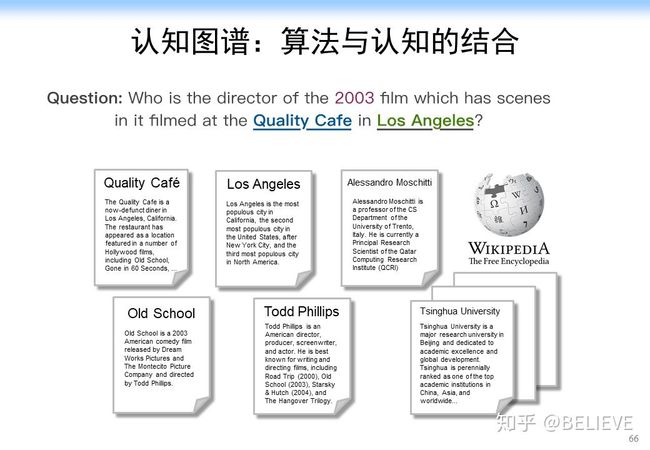
但是计算机会怎么做?计算机不像人,计算机没有这么聪明。如果我们用一个简单的方法,也就是说我们用卷积神经网络的方法来做的话,应该怎么做?我们可以用 BERT 或 XLNet,BERT 可以做到 512 的 Context 了,我们现在甚至可以做到 1024、2048 的 Context,当然训练要求就更高了,甚至没有足够的机器来完成。但是这里面核心的一个问题不是说它能不能解的问题(当然第 1 个方面是它能不能解),而是像人那样解决这个问题,即需要人的推理过程,但 BERT 可能根本就解决不了。
第 2 个更难的是缺乏知识层面上的一个推理能力,尤其是缺乏可解释性。我们到最后得到的一个可能的结果:BERT 给出了一个和真实结果比较相似的结果,说这就是答案,然后就结束了。要想完美解决这个问题,需要有一个推理路径或者一个子图,我们怎么在这方面来做这样的事情?这很难。怎么办呢?我们来看一看人的推理过程。人的推理过程是:人在拿到这个问题以后,首先可能找到 Quality 咖啡馆相关的文档,这是最好的一个文档(因为洛杉矶市的相关文档不是一个好的初始文档)。找到 Quality 咖啡馆相关的文档以后,我们可以从里面找到 old school 的相关文档,然后从 old school 的文档中可以找到 Todd Phillips。整个过程有好几个步骤,如下图所示。
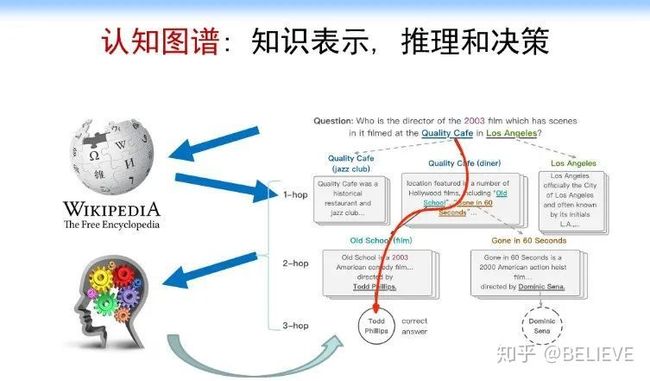
我们怎么把步骤形式化成一个计算机或者说机器学习能做的事情就是我们下一步要探讨的。
我们把这个问题跟认知科学中的一个很重要的理论——双通道理论(Dual Process Theory)结合起来。为什么和双通道理论结合起来呢?人在做推理的时候,我们发现有两个系统:System 1 和 System 2。System 1 被叫作直觉系统,直觉系统是说给定某个关系以后,只要算出相似度,就立马把相似度给出来。比如当大家听到 3 月 29 号下午有一个图神经网络的研讨会时,大家觉得有兴趣,决定要听一下。System 2 会做进一步的推理、逻辑思考、决策。它可能会想下午还要带小孩出去玩,或者下午还有另外一门课,这个课不能翘,于是你最后说算了,下午不去了,最后你就不参加了。所以 System 2 它是带有逻辑思考的。
以上就是人思考问题的过程。AI 怎么跟人来结合?我们在去年探讨这个问题的时候,正好 Yoshua Bengio 他们也在聊这个问题,他在去年的 NIPS 上更直接地讲了:“深度学习应该直接从 System 1 做到 System 2。现在 System 1 主要是在做直觉式(Intuitive)的思考。而 System 2 应该做一些逻辑加上一些推理,再加上一些 planning 的思考”如下图所示。

他直接说的是说要做System 2的深度学习。我们当时其实还没有直接提 System 2 的深度学习。我们讲的是“机器学习跟人的逻辑思考,甚至加上常识知识图谱,两者结合起来”。在这个基础上,我们在去年其实跟 Yoshua Bengio 他们同时发了两篇文章。
我们当时做了什么?我们就用 System 1 来做知识扩展,来做直觉的知识扩展;用 System 2 来做决策,我们就把它叫作认知图谱(Cognitive Graph)。这个思想用刚才那个例子来说大概是下面这样。
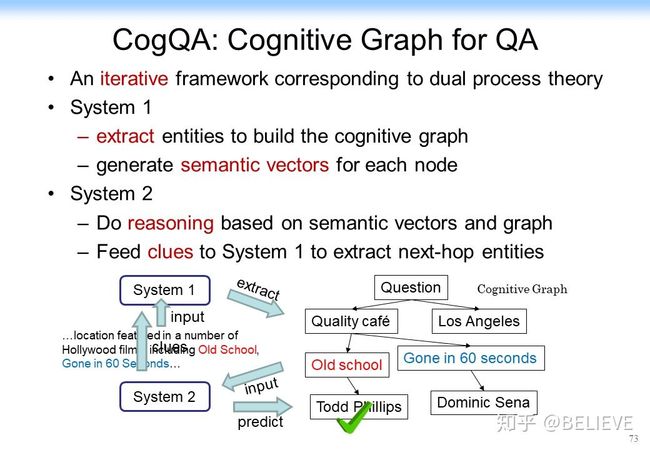
首先,回到刚才那个问题,我们可以很快找到这个问题中的实体,这个很简单,可以用实体识别或者用自然语言处理做到。System 1 可以利用知识图谱或 BERT、通过 Quality 咖啡馆自动做扩展,如说我们可以找到old school和Gone in 60 seconds这两部电影。然后 System 2 在这上面来做决策。old school是我们要的答案吗?Gone in 60 seconds是我们要的答案吗?如果不是,System 2 就考虑要不要把信息回放到 System 1 中,给 System 1 做扩展。System 1 可能继续做扩展,比如old school是 Todd Phillips 导演的,System 2 对此进一步做决策说 Todd Phillips 就是要找的,于是分析就停止了。这就是一个基本的认知图谱的思想。
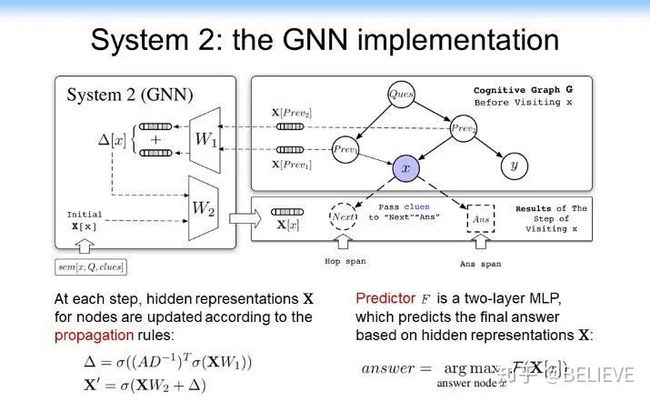
最后怎么实现呢?对于 System 1,我们刚才说做扩展,如果我们回到深度学习,这就跟 Yoshua Bengio 的思路基本上结合起来了。System 1 还可以用表示学习的各种方法,如可以用 BERT、ProNE、NetFM 甚至 DeepWalk 等方法。我们可以做一个简单的相似度的扩展,于是我们就有了 System 1。System 1 是做知识的扩展,System 2 是做决策和推理的。对 System 2 该怎处理呢?我们把 System 2 做成下图所示的样子。System 2 里面核心的东西有一个推理和决策功能,于是我们就用卷积神经网络或者图神经网络来实现。这里面相当于汇聚了所有的信息,它把 System 1 中的拿出来的各种信息汇聚过来,判断这个是不是我需要的答案,最后做决策。于是我们就把两个神经网络系统给整合到一起了,我们把它叫做认知图谱(Cognitive Graph)。

在具体实现方面,System 1 可以用 BERT 做几个 top-k 的 negative threshold 的相似度的查找,如下图所示。
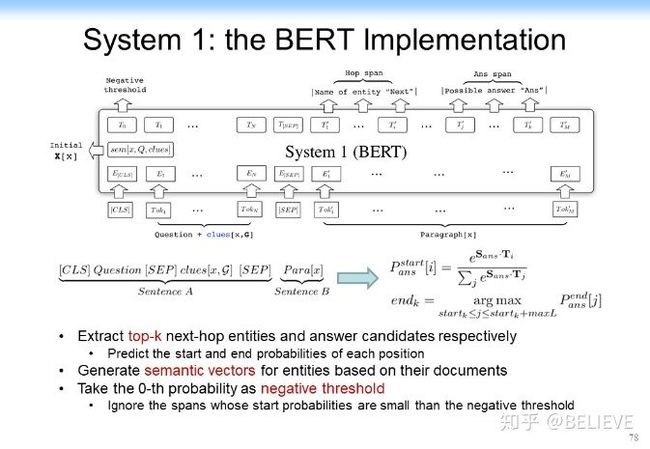
找到以后,我们把它作为 Cognitive Graph 拿给 System 2 来做决策。System 2 就相当于做直接做一个 prediction,相当于学一个 prediction 的模型。用 GNN 直接来做预测。如果是答案就结束,如果不是答案,但是有用,就把它交给 System 1 来接着做。具体结构如下图所示。
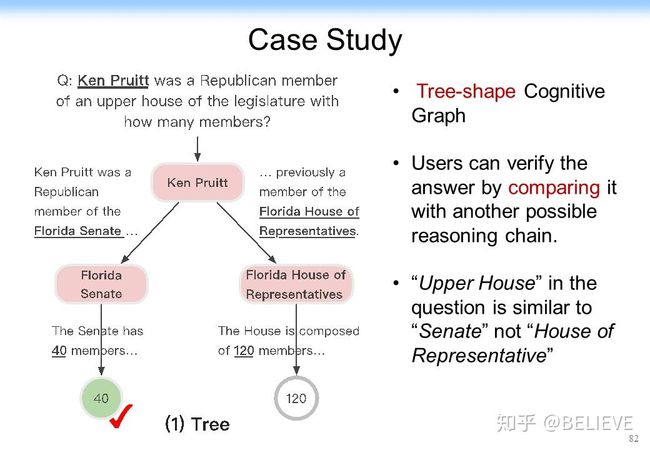
以上就是一个基本的思后来我们在去年的时候去参加了 SQuAD 的 HotpotQA 的一个多跳的竞赛。就在这个竞赛中,当时我们一下子拿到了第 1 名,而且在第 1 名的位置上保持了三个月。大家可以看一下下图这个结果可以发现更有意思的事:CogQA(CogGraph)的结果比当时的 BERT 好 50%。CogQA 可以做到 49%,而当时的 BERT 在F1 值上最好的结果是 31%。更优美的是它给出了一个很强的可解释性,我前面介绍了可解释性非常重要,尤其是在多跳的情况下。首先,对多跳的效果的提升是很明显的,如 hop 跳得如果越高的话,即跳出越多的话,CogQA 的结果就明显的比原来的方法要好得多。其次,它的可解释性非常强。比如我给你一个答案,这个答案是 40,如下图左下角所示。这个事实大家可以看到,而我可以告诉你为什么能拿到 40。我是先找到这 Ken Pruitt,然后再找到 Florida Senate,最后找到 40。这里有一个可解释、可追溯的这么一个结果,一下就把可解释性大幅提高。它甚至可以从本质上帮助机器学习。
机器学习原来是依靠某个信息做预测,这个时候可能没有扩展的信息,而依靠认知图谱,可以用 system 1 扩展出来新的信息,如果拓展的信息精度不够高,还可以通过做一层推理给出更多的信息,这个时候机器学习系统可以结合更多的信息再来做预测,这可能又进一步提高了效果。当机器学习系统做了一个错误的预测以后,认知图谱还可以回溯错误是怎么产生的。这个方面有很多相关的应用。
有人可能会说,这个是不是只能做问答?不是的,它既可以做问答,也可以做知识图谱的补齐,下图左边是一个知识图谱,右边是基于刚才的模型来做知识图谱的一个补齐,这是一个基本的一个思路。

这就是认知图谱怎么和推理结合在一起。
五、GNN 的挑战与未来
未来我们有很多挑战,但是也有很多机遇。张钹院士在 2015 年提出人工智能基本上在做两件事。
第一件事:做知识的表示和知识的推理。其实知识表示和知识推理在 20 世纪 50 年代第一个人工智能时代就已经有了。当时的推理就已经很先进了。但是一直没有发展起来,一个原因就是规模小,另一个原因是固定、死板,不能自学习。这跟当时的计算机计算能力差、缺乏大规模的数据有关系。
第二件事:第二波人工智能浪潮的兴起是机器学习驱动的,第三波人工智能浪潮(也就是这一次人工智能浪潮)是依靠深度学习把整个基于学习的人工智能推向了一个顶峰,所以我说这是一个感知时代的顶峰。现在人工智能最大的问题缺乏可解释性,而且缺乏健壮性。我刚才讲了,存在一个噪声可能就会导致整个网络的表示学习的结果就不行了,甚至缺乏这种可信的结果和可扩展的结果。这些方面都需要我们做进一步的研究,所以当时张院士就提出要做第三代人工智能。DARPA 在 2017 年也做了 XAI 项目,提出一定要做可解释性的机器学习。
2018 年,清华大学正式提出第三代人工智能的理论框架体系:(1)建立可解释、健壮性的人工智能理论和方法。(2)发展安全、可靠、可信及可扩展的人工智能技术。(3)推动人工智能创新应用。
结合刚才讲到的内容,我认为:(1)数据和知识的融合是非常关键的,我们要考虑怎么把知识融合到数据里面。(2)我们怎么跟脑科学、脑启发、脑认知的方法结合起来。所以刚才我抛砖引玉给了一个思想,即我们用认知图谱这种思想,可能可以把人的常识知识和一些推理逻辑结合到深度学习中,甚至可以把一些知识的表示也结合到里面。这样的话“认知+推理”就是未来。这里面还有一个核心的基石:要建造万亿级的常识知识图谱,这是我们必须要做的。这里面路还非常远,我也非常欢迎大家一起加入来做这方面的研究和探讨。
这里面再次抛砖引玉,提一下几个相关的研究。(1)在推理方面有几个相关的工作,如 DeepMind 的 graph_net 就把关系融合到网络表示中,在网络表示学习中发挥一定的作用。(2)最近的一篇文章把知识图谱融合到了 BERT 中,这样的话知识图谱中就有了与 BERT 相关的一些东西,可以用这种知识图谱来帮助 BERT 的预训练。当然,我不是说它是最好的,但它们都提出了一个思路,讲到了怎么把表示学习和 GNN 结合起来,这是很重要的一些事情。
下图列出了一些相关的论文,还有一两篇是我们没有发表的文章,包括刚才说的 Signal Rescaling,其实我们在那篇文章里面做了很多数学分析。

总的来讲,未来的GNN一定是面向推理、面向认知的。我们在感知时代、网络时代里面做了很多网络表示,如 GCN、GNN 等,还有一些把知识结合了起来,但是下一步我们怎么做推理(reasoning)、规划(planning)、逻辑(logical)的这种表示,甚至人的这种表示?这是一个很大的问题。人工智能终极目的就是让计算机能够像人一样互相的表示,所以这也是未来非常重要的研究方向。