系列课程 ElasticSearch 之第 9 篇 —— ELK (ElasticSearch、Logstash、Kibana)分布式日志收集和查看(完结)

传统日志搜索有什么问题?
如果你在软件公司里上班,有客户反馈系统出bug,要你排查日志,你们一般怎么排查?传统的排查日志的办法,就是登录到每台部署微服务的机器上,然后一般使用下面的命令行:
根据关键字查询200行:
tail -200 service.log | grep '查询的关键字'
或者:
grep -C 10 -i "查询的关键字" service.log 或者实时查询最新的100行
tail -100f service.log 如果部署的微服务在多台机器,A台机器无法搜索到,又跑去B台机器上进行搜索。这样排查日志的效率是非常低的。如果部署有十几台机器,那不累垮了?
所以,我们需要一个集中化的日志管理工具,同时还需要对日志进行检索和统计。
ELK 分布式日志收集的介绍
ElasticSearch 是一个基于 Lucene 的开源分布式搜索服务器,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。它支持全文搜索,能够达到实时搜索。ElasticSearch 具有稳定,可靠,快速,安装使用方便等特点。
Logstash (读作 log [stæʃ] )是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。一般工作方式为 c/s 架构,client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作,然后一起发往 ElasticSearch 上去。Logstash 事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
Kibana 是一个基于浏览器页面的 ElasticSearch 前端展示工具,也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
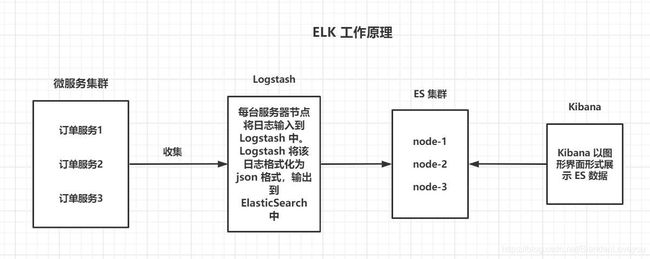
ELK 分布式日志收集原理
1、集群中的每台微服务的节点都安装 Logstash 日志收集系统插件。
2、每台服务器节点将日志输入到 Logstash 中。
3、Logstash 将该日志格式化为 json 格式,根据每天创建不同的索引,输出到 ElasticSearch 中。
4、浏览器使用安装 Kibana 查询日志信息。
ELK 环境搭建(Windows环境)
前面的博客已经讲解了 Windows 环境如何安装 ElasticSearch 和 Kibana,还安装了 Logstash。博客地址:https://blog.csdn.net/BiandanLoveyou/article/details/115742897
既然 Logstash 要收集日志,首先就要知道日志的路径。我们以当前 SpringBoot 的项目的日志为基础,让 Logstash 收集。因此,我们需要改造一下当前项目:
先下载之前的代码。代码地址:https://pan.baidu.com/s/13QyQvO3mixrBL3Ubxh2RLA 提取码:fwfw
修改 boostrap.yml 配置如下:需要说明的是,日志文件路径的配置,可以根据自己的实际情况进行配置。
spring:
application:
name: ElasticSearchTest
data:
elasticsearch:
# 集群名称,默认是 elasticsearch,如果需要改名字,需修改配置 ES 的配置文件 elasticsearch.yml
cluster-name: elasticsearch
# ElasticSearch 节点地址,注意端口号是 9300,而9200是http协议端口
cluster-nodes: 127.0.0.1:9300
server:
port: 8080
# 将SpringBoot项目作为单实例部署调试时,不需要注册到注册中心
eureka:
client:
fetch-registry: false
register-with-eureka: false
# 日志文件路径配置
log:
file:
path: D:/work/Java/IDEA/workspace/logspom.xml 增加 log4j 的日志依赖:
4.0.0
com.study
ElasticSearchTest
1.0-SNAPSHOT
org.springframework.boot
spring-boot-starter-parent
2.2.0.RELEASE
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-starter-data-elasticsearch
com.google.collections
google-collections
1.0
org.slf4j
slf4j-api
${slf4j.version}
org.slf4j
slf4j-log4j12
${slf4j.version}
org.slf4j
jcl-over-slf4j
${slf4j.version}
org.slf4j
jul-to-slf4j
${slf4j.version}
org.springframework.cloud
spring-cloud-dependencies
Greenwich.SR2
pom
import
然后增加一个 logback.xml 文件,放在 source 目录下,如图:
logback.xml 具体内容如下:
%date [%thread] %-5level %logger{50}:%L - %msg%n
${logPath}/${appName}.log
${logPath}/history/server.%d{yyyy-MM-dd}.log.gz
30
%date [%thread] %-5level %logger{50}:%L - %msg%n
注意,我们使用默认的文件名 logback.xml 即可,因为 log4j 启动的时候会去寻找这些默认的文件名的:

这时候,我们启动项目,就会在日志文件目录下,生成日志文件,比如我的是 D:\work\Java\IDEA\workspace\logs

OK,有了日志文件,我们现在来整合 Logstash。
我们的思路是:启动 Logstash 服务,同时指定它读取哪个日志文件,即 input;然后 Logstash 经过处理成标准的 json 格式,再输出到 ElasticSearch 节点上。
我们打开 Logstash 的 config 目录,看到一个文件:

用记事本打开,内容如下:

这就是最简单的 Logstash 配置文件,它这里没有展示 filter 过滤的内容。我们仿造它创建一个我们自己的配置文件(可以复制它的,然后重命名):my-logstash.conf,内容如下:
# 读取的源数据:需要指定文件的路径,已经格式,type等信息
input {
# 从文件读取日志信息 输送到控制台
file {
# 文件路径
path => "D:/work/Java/IDEA/workspace/logs/ElasticSearchTest.log"
# 以 json 格式读取文件
codec => "json" ## 以JSON格式读取日志
# 指定类型为 elasticsearch
type => "elasticsearch"
# 读取的位置:从开始的位置读取
start_position => "beginning"
}
}
# 过滤器,目前暂时没用到
# filter {
#
# }
# 输出
output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
# ES 的地址(9200是http协议端口)以及索引的名字(每天一个日志)
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "es-%{+YYYY.MM.dd}"
}
}然后,我们来测试一下。
正确的启动方式是:先启动 ElasticSearch 服务器,再启动 Logstash,最后启动微服务。这样 Logstash 就不会因为找不到 ES 服务而报错。
启动 ElasticSearch 服务器就很容易了,现在说一下如何在 windows 环境下启动 Logstash。
windows 下启动 Logstash 服务需要 CMD 命令行。步骤如下:
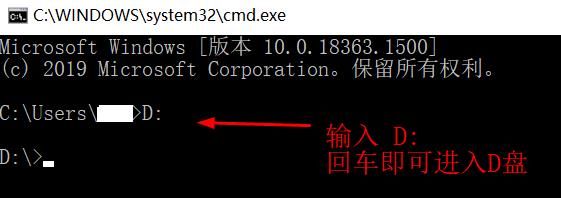
1、打开 CMD,进入到 Logstash 的 bin 目录下:
首先进入你本机安装 Logstash 的磁盘,比如我的是D盘。那就在 CMD 命令行上输入 D: 然后回车,效果如下:
2、然后 cd 进入到你安装 Logstash 的 bin 目录,在 CMD 命令行可以结合电脑键盘的 Tab 键,能智能识别输入,注意,每进入一层文件夹,都是使用斜杠 \ ,否则无法识别,比如我的:
D:\>cd work\Java\ElasticSearch\logstash\logstash\bin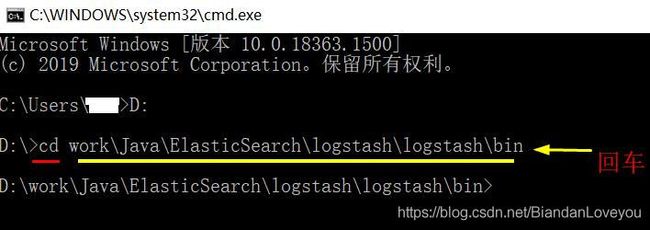
3、启动 Logstash 服务,命令行如下:在 bin 目录下,启动 logstash,加个 -f,然后使用我们的自定义配置文件,因为 bin 目录和 config 目录在同一级,在 bin 目录里需要返回到上一级(使用 ..\),才能找到我们的自定义配置文件。第一次启动需要等待比较久(30秒吧)
D:\work\Java\ElasticSearch\logstash\logstash\bin>logstash -f ..\config\my-logstash.conf
4、这时候,我们重启我们的微服务,就能看到 Logstash 的控制台实时输出我们的日志了:
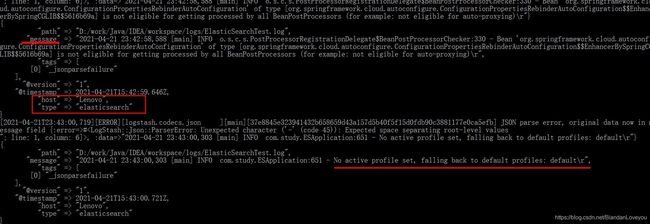
OK,我们使用 Kibana 管理后台查看:
我们在 Dev Tools 菜单下,输入 GET /es 就会自动识别 Logstash 创建的索引了。这个索引是每天都生成一个。

比如我们输入查询条件:
GET /es-2021.04.21/_search
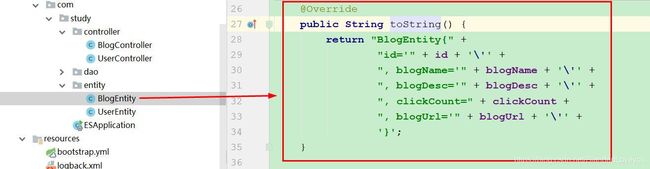
接下来,我们可以在微服务里增加一些操作 API 接口并输出一些日志,我们首先在 BlogEntity 实体类增加 toString方法,如图(快捷键 Alt+Insert 调出小窗口,找到 toString 方法):
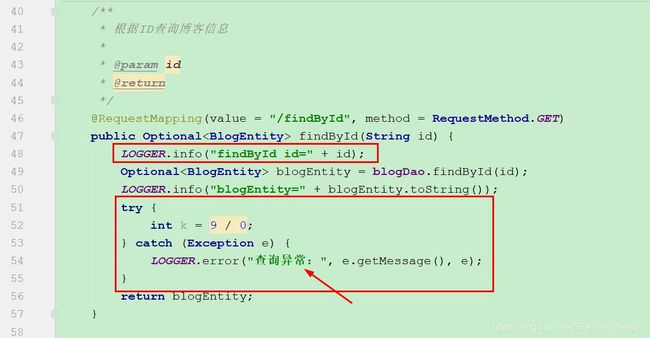
然后修改 controller 类:主要是增加一些日志信息:
完整代码如下:
package com.study.controller;
import com.google.common.collect.Lists;
import com.study.dao.BlogDao;
import com.study.entity.BlogEntity;
import jdk.nashorn.internal.parser.JSONParser;
import org.apache.commons.lang.StringUtils;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.web.PageableDefault;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import java.util.*;
/**
* @author biandan
* @description
* @signature 让天下没有难写的代码
* @create 2021-04-16 下午 11:33
*/
@RestController
@RequestMapping(value = "/blog")
public class BlogController {
private final static Logger LOGGER = LoggerFactory.getLogger(BlogController.class);
@Autowired
private BlogDao blogDao;
/**
* 根据ID查询博客信息
*
* @param id
* @return
*/
@RequestMapping(value = "/findById", method = RequestMethod.GET)
public Optional findById(String id) {
LOGGER.info("findById id=" + id);
Optional blogEntity = blogDao.findById(id);
LOGGER.info("blogEntity=" + blogEntity.toString());
try {
int k = 9 / 0;
} catch (Exception e) {
LOGGER.error("查询异常:", e.getMessage(), e);
}
return blogEntity;
}
/**
* 根据条件查询所有博客列表
*
* @param blogName 博客名称
* @param blogDesc 博客描述
* @param clickCount 点击数
* @return
*/
@RequestMapping(value = "/findAll", method = RequestMethod.POST)
public List findAll(String blogName, String blogDesc, Integer clickCount) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//模糊查询博客名称
if (StringUtils.isNotBlank(blogName)) {
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("blogName", blogName);
boolQueryBuilder.must(queryBuilder);
}
//模糊查询博客描述
if (StringUtils.isNotBlank(blogDesc)) {
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("blogDesc", blogDesc);
boolQueryBuilder.must(queryBuilder);
}
//根据点击数精确查询
if (null != clickCount) {
TermQueryBuilder queryBuilder = QueryBuilders.termQuery("clickCount", clickCount);
boolQueryBuilder.must(queryBuilder);
}
Iterable entities = blogDao.search(boolQueryBuilder);
//使用Google的工具包
List resultList = Lists.newArrayList(entities);
LOGGER.info("resultList =" + resultList.toString());
return resultList;
}
/**
* 分页查询
*
* @param blogName 博客名称
* @param blogDesc 博客描述
* @param clickCount 点击数量
* @param pageable 分页信息,我们可以设置默认值: page、value(每页查询数量)的值
* @return
*/
@RequestMapping(value = "/findByPage", method = RequestMethod.POST)
public Page findByPage(String blogName, String blogDesc, Integer clickCount, @PageableDefault(page = 0, value = 10) Pageable pageable) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//模糊查询博客名称
if (StringUtils.isNotBlank(blogName)) {
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("blogName", blogName);
boolQueryBuilder.must(queryBuilder);
}
//模糊查询博客描述
if (StringUtils.isNotBlank(blogDesc)) {
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("blogDesc", blogDesc);
boolQueryBuilder.must(queryBuilder);
}
//根据点击数精确查询
if (null != clickCount) {
TermQueryBuilder queryBuilder = QueryBuilders.termQuery("clickCount", clickCount);
boolQueryBuilder.must(queryBuilder);
}
Page search = blogDao.search(boolQueryBuilder, pageable);
return search;
}
}
重启微服务,我们使用 postman 测试根据 ID 查询博客的接口:
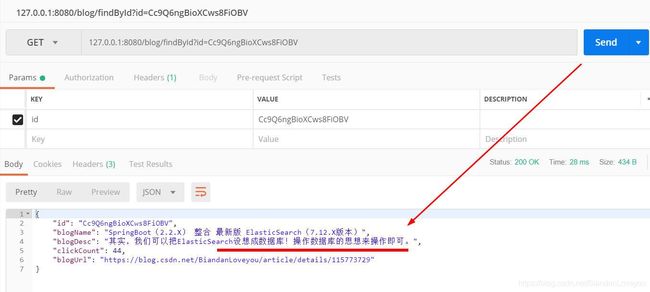
这时候,我们去 Logstash 的控制台,往上翻,可以看到这行日志:

我们去 Kibana 管理后台验证:
GET /es-2021.04.22/_search
{
"query": {
"match": {
"message": "数据库"
}
}}
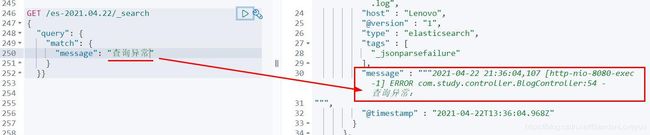
大部分使用 Kibana 的 Dev Tools 菜单,我们也可以使用 Discover,如图:

演示的代码地址:https://pan.baidu.com/s/1l4sCiR-VPQDuzvzzbBOJPg 提取码:1e3y