【神经网络】(19) ConvNeXt 代码复现,网络解析,附Tensorflow完整代码
各位同学好,今天和大家分享一下如何使用 Tensorflow 构建 ConvNeXt 卷积神经网络模型。
论文地址:https://arxiv.org/pdf/2201.03545.pdf
完整代码在我的Gitee中:https://gitee.com/dgvv4/neural-network-model/tree/master/
21年Transformer频频跨界视觉领域,先是在图像分类上被谷歌ViT突破,后来在目标检测和图像分割又被微软Swin Transformer拿下。随着投身视觉Transformer研究的学者越来越多,三大任务榜单皆被Transformer或两种架构结合的模型占据头部,这时ConvNeXt代表卷积神经网络站了出来。

1. ConvNeXt Block 模块
1.1 基本结构

(1)ConvNeXt 使用了分组卷积的思想,和MobileNetV1中的深度卷积(Depthwise Conv)相同。输入特征图有多少个通道数,就有多少个卷积核,每个卷积核处理一个对应的通道,每个卷积核生成一张特征图。将所有生产的特征图在通道维度上堆叠,那么就有输入特征图的通道数和输出特征图的通道数相同。
(2)逆转残差结构,先1*1卷积升维,后1*1卷积降维。借鉴了MobileNetV2的逆转残差结构。在较小的模型上准确率由80.5%提升到了80.6%,在较大的模型上准确率由81.9%提升到82.6%。
可参考我之前的文章:https://blog.csdn.net/dgvv4/article/details/123476899
(3)更少的标准化层,使用 Layer Normalization 代替 Batch Normalization。作者借鉴了Transformer 的结构,只保留深度卷积之后的标准化层,替换后准确率得到小幅提高。
1.2 代码展示
下面代码中 gama 是对1*1降维卷积的输出特征图的数据进行缩放。gama 是一个可学习的变量,在网络训练过程中,反向传播优化gama的值。
gama 是一个一维向量,它的元素个数和输出特征图的通道数相同。向量中的每个元素处理一张对应的特征图,某张特征图的所有像素值依次和向量的某个元素相乘,达到缩放特征图数据的目的。
定义可训练参数 add_weight() 是 Layer类下面的一个方法,使用之前,先对Layer类实例化,layers.Layer()
#(2)ConvNeXt Block
def block(inputs, dropout_rate=0.2, layer_scale_init_value=1e-6):
'''
layer_scale_init_value 缩放比例gama的初始化值
'''
# 获取输入特征图的通道数
dim = inputs.shape[-1]
# 残差边
residual = inputs
# 7*7深度卷积
x = layers.DepthwiseConv2D(kernel_size=(7,7), strides=1, padding='same')(inputs)
# 标准化
x = layers.LayerNormalization()(x)
# 1*1标准卷积上升通道数4倍
x = layers.Conv2D(filters=dim*4, kernel_size=(1,1), strides=1, padding='same')(x)
# GELU激活函数
x = layers.Activation('gelu')(x)
# 1*1标准卷积下降通道数
x = layers.Conv2D(filters=dim, kernel_size=(1,1), strides=1, padding='same')(x)
# 创建可学习的向量gama,该函数用于向某一层添加权重变量,类实例化layers.Layer()
gama = layers.Layer().add_weight(shape=[dim], # 向量个数和输出特征图通道数量一致
initializer=tf.initializers.Constant(layer_scale_init_value), # 权重初始化
dtype=tf.float32, # 指定数据类型
trainable=True) # 可训练参数,可通过反向传播调整权重
# layer scale 对特征图的每一个通道数据进行缩放,缩放比例gama
x = x * gama # [56,56,96]*[96]==>[56,56,96]
# Dropout层随机杀死神经元
x = layers.Dropout(rate=dropout_rate)(x)
# 残差连接输入和输出
x = layers.add([x, residual])
return x2. 主干网络
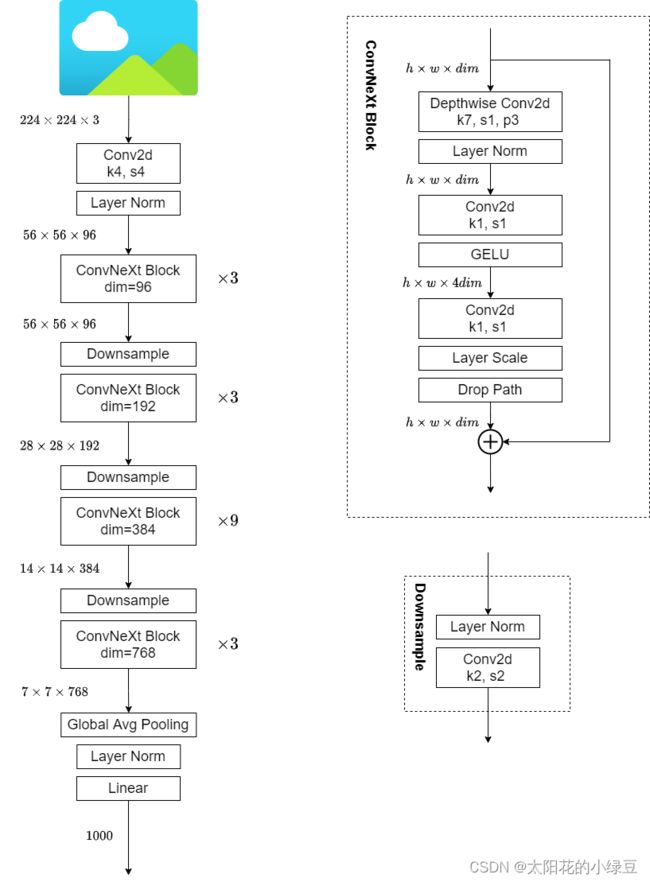
2.1 网络结构图
2.2 设计方案
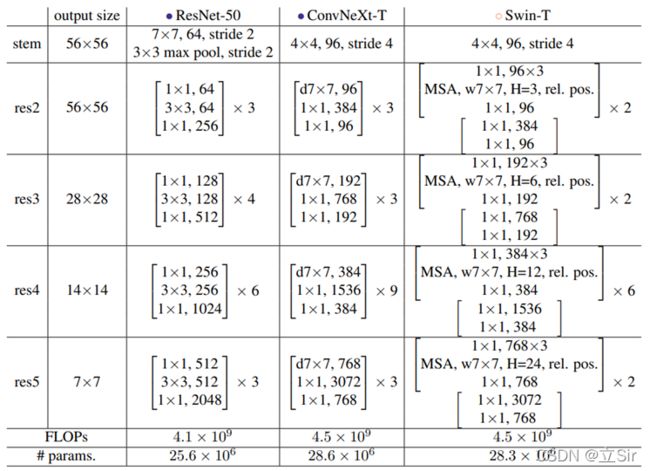
网络架构。如上图,在ResNet50网络中,res2到res5堆叠block的次数是(3, 4, 6, 3)比例大概是1:1:2:1,但在Swin Transformer中,比如Swin-T的比例是1:1:3:1,Swin-L的比例是1:1:9:1。很明显,在Swin Transformer中堆叠block的占比更高。所以作者就将ResNet50中的堆叠次数由(3, 4, 6, 3)调整成(3, 3, 9, 3),和Swin-T拥有相似的FLOPs。
下采样层的设计。ResNet网络的下采样都是通过将主分支上3x3的卷积层步距设置成2,残差边上1x1的卷积层的步长设置成2。但在Swin Transformer中是通过一个单独的Patch Merging实现的。作者借鉴Swin-T为ConvNext网络单独使用了一个下采样层,由一个Laryer Normalization 加上一个 kernel_size=2 且 strides=2 的卷积层构成。
2.3 完整代码展示
ConvNeXt使用的全部都是现有的结构和方法,没有任何结构或者方法的创新。而且代码也非常的精简,100多行代码就能搭建完成
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Model, layers
#(1)输入图像经过的第一个卷积块
def pre_Conv(inputs, out_channel):
# 4*4卷积+标准化
x = layers.Conv2D(filters=out_channel, # 输出特征图的通道数
kernel_size=(4,4),
strides=4, # 下采样
padding='same')(inputs)
x = layers.LayerNormalization()(x)
return x
#(2)ConvNeXt Block
def block(inputs, dropout_rate=0.2, layer_scale_init_value=1e-6):
'''
layer_scale_init_value 缩放比例gama的初始化值
'''
# 获取输入特征图的通道数
dim = inputs.shape[-1]
# 残差边
residual = inputs
# 7*7深度卷积
x = layers.DepthwiseConv2D(kernel_size=(7,7), strides=1, padding='same')(inputs)
# 标准化
x = layers.LayerNormalization()(x)
# 1*1标准卷积上升通道数4倍
x = layers.Conv2D(filters=dim*4, kernel_size=(1,1), strides=1, padding='same')(x)
# GELU激活函数
x = layers.Activation('gelu')(x)
# 1*1标准卷积下降通道数
x = layers.Conv2D(filters=dim, kernel_size=(1,1), strides=1, padding='same')(x)
# 创建可学习的向量gama,该函数用于向某一层添加权重变量,类实例化layers.Layer()
gama = layers.Layer().add_weight(shape=[dim], # 向量个数和输出特征图通道数量一致
initializer=tf.initializers.Constant(layer_scale_init_value), # 权重初始化
dtype=tf.float32, # 指定数据类型
trainable=True) # 可训练参数,可通过反向传播调整权重
# layer scale 对特征图的每一个通道数据进行缩放,缩放比例gama
x = x * gama # [56,56,96]*[96]==>[56,56,96]
# Dropout层随机杀死神经元
x = layers.Dropout(rate=dropout_rate)(x)
# 残差连接输入和输出
x = layers.add([x, residual])
return x
#(3)下采样层
def downsampling(inputs, out_channel):
# 标准化+2*2卷积下采样
x = layers.LayerNormalization()(inputs)
x = layers.Conv2D(filters=out_channel, # 输出通道数个数
kernel_size=(2,2),
strides=2, # 下采样
padding='same')(x)
return x
#(4)卷积块,一个下采样层+多个block卷积层
def stage(x, num, out_channel, downsampe=True):
'''
num:重复执行多少次block ; out_channel代表下采样层输出通道数
downsampe:判断是否执行下采样层
'''
if downsampe is True:
x = downsampling(x, out_channel)
# 重复执行num次block,每次输出的通道数都相同
for _ in range(num):
x = block(x)
return x
#(5)主干网络
def convnext(input_shape, classes): # 输入图像shape和分类类别数
# 构造输入层
inputs = keras.Input(shape=input_shape)
# [224,224,3]==>[56,56,96]
x = pre_Conv(inputs, out_channel=96)
# [56,56,96]==>[56,56,96]
x = stage(x, num=3, out_channel=96, downsampe=False)
# [56,56,96]==>[28,28,192]
x = stage(x, num=3, out_channel=192, downsampe=True)
# [28,28,192]==>[14,14,384]
x = stage(x, num=9, out_channel=384, downsampe=True)
# [14,14,384]==>[7,7,768]
x = stage(x, num=3, out_channel=768, downsampe=True)
# [7,7,768]==>[None,768]
x = layers.GlobalAveragePooling2D()(x)
x = layers.LayerNormalization()(x)
# [None,768]==>[None,classes]
logits = layers.Dense(classes)(x) # 不经过softmax
# 构建网络
model = Model(inputs, logits)
return model
#(6)接收网络模型
if __name__ == '__main__':
# 构造网络,传入输入图像的shape,和最终输出的分类类别数
model = convnext(input_shape=[224,224,3], classes=1000)
model.summary() # 查看网络结构
网络参数如下
==================================================================================================
Total params: 28,582,504
Trainable params: 28,582,504
Non-trainable params: 0
__________________________________________________________________________________________________3. 网络模型图
感谢 太阳花的小绿豆 博主的模型图