【数据结构】限定性线性表——栈 (7000字超级详细 图文结合)C语言
目录
1 栈
1.1 栈的定义
1.2 栈的表示和实现
顺序栈
两栈共享技术(双端栈)
链栈
多栈运算
1.3 栈的应用举例
1. 括号匹配问题
2. 表达式求值
1.4 栈与递归
为了自己的目标和追求,也希望带给更多的人帮助。
1 栈
1.1 栈的定义
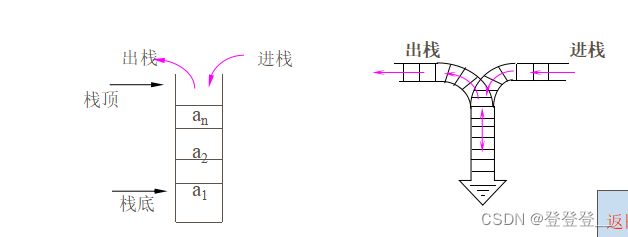
栈作为一种限定性线性表,是将线性表的插入和删除运算限制为仅在表的一端进行。通常将表中允许进行插入、删除操作的一端称为栈顶 (Top),表的另一端被称为栈底 (Bottom)。当栈中没有元素时称为空栈。栈的插入操作被形象地称为进栈或入栈,删除操作称为出栈或退栈。
进栈、出栈图例
根据栈定义,每次进栈的元素都被放在原栈顶元素之上而成为新的栈顶,而每次出栈的总是当前栈中“最新”的元素,即最后进栈的元素。因此,栈又称为后进先出的线性表。简称为LIFO表。如下图所示:
栈的抽象数据类型定义
数据元素:可以是任意类型的数据,但必须属于同一个数据对象。
关系:栈中数据元素之间是线性关系
基本操作:
1.InitStack(S) 2. ClearStack(S) 3. IsEmpty(S) 4. IsFull(S)
5. Push(S,x) 6. Pop(S,x) 7. GetTop(S,x)
1.2 栈的表示和实现
栈在计算机中主要有两种基本的存储结构:顺序存储结构和链式存储结构。
顺序存储的栈为顺序栈; 链式存储的栈为链栈。
顺序栈
顺序栈是用顺序存储结构实现的栈,即利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,同时由于栈的操作的特殊性,还必须附设一个位置指针top(栈顶指针)来动态地指示栈顶元素在顺序栈中的位置。通常以top = -1表示空栈。
栈的顺序存储结构定义如下 :
#define Stack_Size 50
typedef struct
{
StackElementType elem[Stack_Size]; /*用来存放栈中元素的一维数组*/
int top; /*用来存放栈顶元素的下标,top为-1表示空栈*/
}SeqStack;
顺序栈中的进栈和出栈图例:
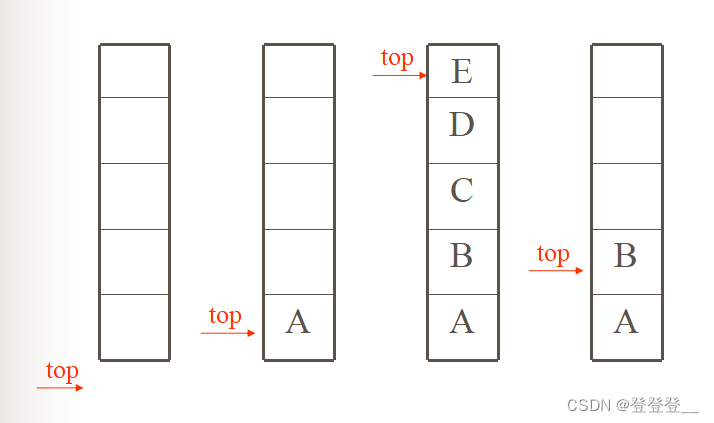
顺序栈基本操作的实现
1)初始化
void InitStack(SeqStack *S)
{/*构造一个空栈S*/
S->top= -1;
}
2)进栈
int Push(SeqStack * S, StackElementType x)
{
if(S->top== Stack_Size) return(FALSE); /*栈已满*/
S->top++;
S->elem[S->top]=x;
return(TRUE);
}
3)出栈
int Pop(SeqStack * S, StackElementType *x)
{ if(S->top==-1) /*栈为空*/
return(FALSE);
else
{*x= S->elem[S->top];
S->top--; /* 修改栈顶指针 */
return(TRUE);
}
}
4) 取栈顶元素
int GetTop(SeqStack S, StackElementType *x)
{ /* 将栈S的栈顶元素弹出,放到x所指的存储空间中,但栈顶指针保持不变 */
if(S->top==-1) /*栈为空*/
return(FALSE);
else
{*x = S->elem[S->top];
return(TRUE);
}
}
[注意]:
在实现GetTop操作时,也可将参数说明SeqStack *S 改为SeqStack S,也就是将传地址改为传值方式。传值比传地址容易理解,但传地址比传值更节省时间、空间。
两栈共享技术(双端栈)
主要利用了栈“栈底位置不变,而栈顶位置动态变化”的特性。首先为两个栈申请一个共享的一维数组空间S[M],将两个栈的栈底分别放在一维数组的两端,分别是0,M-1。
共享栈的空间示意为:top[0]和top[1]分别为两个栈顶指示器 。
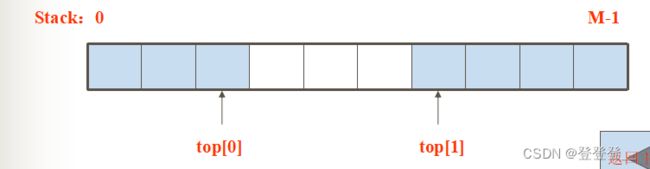
两栈共享的数据结构定义
#define M 100
typedef struct
{
StackElementType Stack[M];
StackElementType top[2]; /*top[0]和top[1]分别为两个栈顶指示器*/
}DqStack;
两栈共享的初始化操作算法
void InitStack(DqStack *S)
{
S->top[0]=-1;
S->top[1]=M;
}
两栈共享的进栈操作算法
int Push(DqStack *S, StackElementType x, int i)
{ /*把数据元素x压入i号堆栈*/
if(S->top[0]+1==S->top[1]) /*栈已满*/
return(FALSE);
switch(i)
{case 0:S->top[0]++; S->Stack[S->top[0]]=x; break;
case 1: S->top[1]--; S->Stack[S->top[1]]=x; break;
default: return(FALSE) /*参数错误*/
}
return(TRUE);
}
两栈共享的出栈操作算法
int Pop(DqStack *S, StackElementType *x, int i)
{ /* 从i 号堆栈中弹出栈顶元素并送到x中 */
switch(i)
{case 0: if(S->top[0]==-1) return(FALSE);
*x=S->Stack[S->top[0]]; S->top[0]--; break;
case 1:if(S->top[1]==M) return(FALSE);
*x=S->Stack[S->top[1]];S->top[1]++;break; default: return(FALSE);
}
return(TRUE);
}
链栈
链栈是采用链表作为存储结构实现的栈。为便于操作,采用带头结点的单链表实现栈。由于栈的插入和删除操作仅限制在表头位置进行,所以链表的表头指针就作为栈顶指针。
链栈的示意图为:

注意:链栈在使用完毕时,应该释放其空间。
链栈结构的用C语言定义
typedef struct node
{
StackElementType data;
struct node *next;
}LinkStackNode;
typedef LinkStackNode *LinkStack;
链栈的进栈操作
int Push(LinkStack top, StackElementType x)
/* 将数据元素x压入栈top中 */
{ LinkStackNode * temp;
temp=(LinkStackNode * )malloc(sizeof(LinkStackNode));
if(temp==NULL) return(FALSE); /* 申请空间失败 */
temp->data=x; temp->next=top->next;
top->next=temp; /* 修改当前栈顶指针 */
return(TRUE);
}
链栈的出栈操作
int Pop(LinkStack top, StackElementType *x)
{ /* 将栈top的栈顶元素弹出,放到x所指的存储空间中 */
LinkStackNode * temp; temp=top->next;
if(temp==NULL) /*栈为空*/
return(FALSE);
top->next=temp->next; *x=temp->data;
free(temp); /* 释放存储空间 */
return(TRUE);
}
多栈运算
将多个链栈的栈顶指针放在一个一维指针数组中来统一管理,从而实现同时管理和使用多个栈。
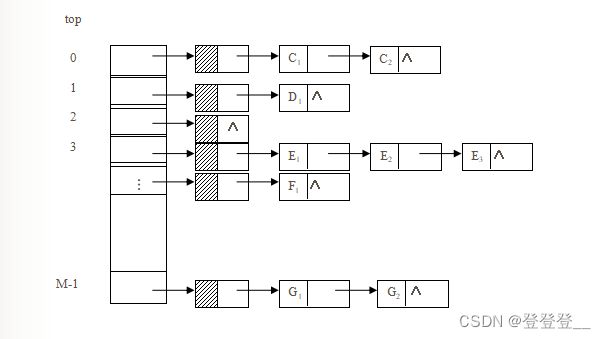
用c语言定义
#define M 10 /*M个链栈*/
typedef struct node
{
StackElementType data;
struct node *next;
}LinkStackNode, *LinkStack;
LinkStack top[M];
(1)第i号栈的进栈操作
int pushi(LinkStack top[M], int i, StackElementType x)
{/*将元素x进入第i号链栈*/
LinkStackNode *temp;
temp=(LinkStackNode * )malloc(sizeof(LinkStackNode));
if(temp==NULL) return(FALSE); /* 申请空间失败 */
temp->data=x;
temp->next=top[i]->next;
top[i]->next=temp; /* 修改当前栈顶指针 */
return(TRUE);
}
(2) 第i号栈元素的出栈操作
int Pop(LinkStack top[M], int i, StackElementType *x)
{ /* 将栈top的栈顶元素弹出,放到x所指的存储空间中 */
LinkStackNode *temp;
temp=top[i]->next;
if(temp==NULL) /*第i号栈为空栈*/
return(FALSE);
top[i]->next=temp->next;
*x=temp->data;
free(temp); /* 释放存储空间 */
return(TRUE);
}
1.3 栈的应用举例
1. 括号匹配问题
思想:在检验算法中设置一个栈,若读入的是左括号,则直接入栈,等待相匹配的同类右括号;若读入的是右括号,且与当前栈顶的左括号同类型,则二者匹配,将栈顶的左括号出栈,否则属于不合法的情况。另外,如果输入序列已读尽,而栈中仍有等待匹配的左括号,或者读入了一个右括号,而栈中已无等待匹配的左括号,均属不合法的情况。当输入序列和栈同时变为空时,说明所有括号完全匹配。
void BracketMatch(char *str)
{Stack S; int i; char ch;
InitStack(&S);
For(i=0; str[i]!='\0'; i++)
{switch(str[i])
{case '(':
case '[':
case '{':
Push(&S,str[i]); break;
case ')':
case ']':
case '}':
if(IsEmpty(S))
{ printf("\n右括号多余!"); return;}
else
{GetTop (&S,&ch);
if(Match(ch,str[i])) Pop(&S,&ch);
else
{ printf("\n对应的左右括号不同类!"); return;}
}
}/*switch*/
}/*for*/
if(IsEmpty(S))
printf("\n括号匹配!");
else
printf("\n左括号多余!");
}
2. 表达式求值
1) 无括号算术表达式求值
无括号算术表达式的处理过程
2) 算术表达式处理规则
(1)规定优先级表;
(2) 设置两个栈:OVS(运算数栈)和OPTR(运算符栈);
(3) 自左向右扫描,遇操作符则与OPTR栈顶优先级比较:当前操作符>OPTR栈顶则进OPTR栈;当前操作符≤ OPTR栈顶,OVS栈顶、次顶和OPTR栈顶,退栈形成运算T(i), T(i)进OVS栈。
例:实现A/B↑C+D*E#的运算过程时栈区变化情况
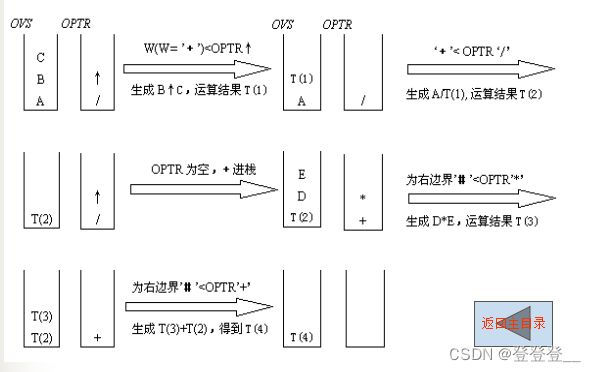
3) 带括号算术表达式
实现算符优先算法时需要使用两个工作栈:一个称作运算符栈operator;另一个称作操作数栈operand。 算法的基本过程如下:
A.初始化操作数栈operand和运算符栈operator,并将表达式起始符“#”压入运算符栈;
B.读入表达式中的每个字符,若是操作数则直接进入操作数栈operand,若是运算符,则与运算符栈operator的栈顶运算符进行优先权比较,并做如下处理:
(1) 若栈顶运算符的优先级低于刚读入的运算符,则让刚读入的运算符进operator栈;
(2) 若栈顶运算符的优先级高于刚读入的运算符,则将栈顶运算符退栈,送入θ,同时将操作数栈operand退栈两次,得到两个操作数a、b,对a、b进行θ运算后,将运算结果作为中间结果推入operand栈;
(3) 若栈顶运算符的优先级与刚读入的运算符的优先级相同,说明左右括号相遇,只需将栈顶运算符(左括号)退栈即可。
当operator栈的栈顶元素和当前读入的字符均为“#”时,说明表达式起始符“#”与表达式结束符“#”相遇,整个表达式求值完毕。
1.4 栈与递归的实现
递归 :在定义自身的同时又出现了对自身的调用。
直接递归函数:如果一个函数在其定义体内直接调用自己,则称直接递归函数。
间接递归函数:如果一个函数经过一系列的中间调用语句,通过其它函数间接调用自己,则称间接递归函数。
1.具有递归特性的问题
1)递归定义的数学函数
如二阶Fibonacci数列:

Ackerman函数可用一个简单的C语言函数描述:
int ack(int m,int n)
{
if(m==0) return n+1;
else if (n==0) return ack(m-1,1);
else return ack(m-1, ack(m,n-1));
}
2)递归数据结构的处理
一些数据结构,如广义表、二叉树、树等结构其本身均具有固有的递归特性,因此可以自然地采用递归法进行处理。
3)递归求解方法
许多问题的求解过程可以用递归分解的方法描述,一个典型的例子是著名的汉诺塔问题(hanoi)问题。
n阶Hanoi塔问题:假设有三个分别命名为X,Y和Z的塔座,在塔座X上插有n个直径大小各不相同、从小到大编号为1,2,... ,n的圆盘。现要求将塔座X上的n个圆盘移至塔座Z上,并仍按同样顺序叠排。
圆盘移动时必须遵循下列规则:
(1) 每次只能移动一个圆盘;
(2) 圆盘可以插在X,Y和Z中的任何一个塔座上;
(3) 任何时刻都不能将一个较大的圆盘压在较小的圆盘之上。
算法思想:
求解n阶Hanoi塔问题的递归算法
void hanoi(int n, char x, char y, char z)
/* 将塔座X上从上到下编号为1至n,且按直径由小到大叠放的n个圆盘,按规则搬到塔座Z上,Y用作辅助塔座。*/
{ if(n==1)
move(x,1,z); /*将编号为1的圆盘从x移动z*/
else
{
hanoi(n-1,x,z,y); /* 将X上编号为1至n-1的圆盘移到y,z作辅助塔 */
move(x,n,z); /* 将编号为n的圆盘从x移到z */
hanoi(n-1, y,x ,z); /* 将y上编号为1至n-1的圆盘移到z,x作辅助塔 */
}
}
下面给出三个盘子搬动时hanoi(3, A, B , C) 的递归调用过程

递归方法的优点 :

设计递归算法的方法:
递归算法就是在算法中直接或间接调用算法本身的算法。
使用递归算法的前提有两个:
⑴原问题可以层层分解为类似的的子问题,且子问题比原问题的规模更小。
⑵规模最小的子问题具有直接解。
设计递归算法的方法
⑴寻找分解方法
⑵设计递归出口
递归过程的实现
递归进层(i→i +1层)系统需要做三件事:
⑴ 保留本层参数与返回地址;
⑵ 为被调用函数的局部变量分配存储区,给下层参数赋值;
⑶ 将程序转移到被调函数的入口。
递归退层(i←i +1层)系统也应完成三件工作:
⑴ 保存被调函数的计算结果;
⑵ 释放被调函数的数据区,恢复上层参数;
⑶ 依照被调函数保存的返回地址,将控制转移回调用函数。
递归算法到非递归算法的转换
递归算法具有两个特性:
(1) 递归算法是一种分而治之、把复杂问题分解为简单问题的求解问题方法,对求解某些复杂问题,递归算法的分析方法是有效的。
(2)递归算法的效率较低。
1)消除递归的原因:
第一:有利于提高算法时空性能
第二:无应用递归语句的语言设施环境条件
第三:递归算法是一次执行完
消除递归方法有两类
一类是简单递归问题的转换,对于尾递归和单向递归的算法,可用循环结构的算法替代。
另一类是基于栈的方式,即将递归中隐含的栈机制转化为由用户直接控制的明显的栈。
2) 简单递归的消除
单向递归
单向递归是指递归函数中虽然有一处以上的递归调用语句,但各次递归调用语句的参数只和主调用函数有关,相互之间参数无关,并且这些递归调用语句处于算法的最后。
例如计算斐波那契数列的递归算法
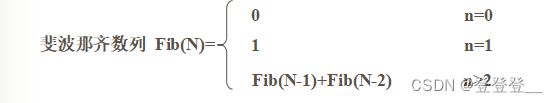
计算斐波那契数列的递归算法如下:
Fib(int n)
{
if(n= =0||n= =1) return n; /* 递归出口 */
else return Fib(n-1)+Fib(n-2); /* 递归调用 */
}
计算斐波那契数列的非递归算法:
int Fib(int n):
{ int x, y, z;
if(n= =0||n= =1)return n; /*计算 Fib (0)或Fib(1) */
else {
x=0, y=1; /* x= Fib (0) y= Fib (1) */
for ( i=2; i<= n; i++ )
{ z=y; /* z= Fib (i-1) */
y=x+y; /* y= Fib (i-1)+ Fib (i-2) 求Fib (i) */
x=z; /* x= Fib (i-1) */
}
return y ;
}
}
尾递归
尾递归是指递归调用语句只有一个,而且是处于算法的最后,尾递归是单向递归的特例。
求n!非递归算法 :
long Fact (int n)
{
int fac=1;
for(int i=1;i<=n;i++) /*依次计算f(1)… f(n)*/
fac=fac* i; /* f(i)= f(i-1)*i */
return fac;
}