如何用web3j获取以太坊所有块和交易信息?
如何用web3j获取以太坊所有块和交易信息?
前文:
使用到的版本信息:Jdk 8 、web3j 4.1.1、springboot 2.1.1
在正式开始之前,先介绍一下今天用到的两个工具:
一、web3j:
github:https://github.com/web3j/web3j
官方的介绍是:web3j是一个轻量级的、高度模块化的、响应式的、类型安全的Java和Android库,用于处理智能契约和集成以太网络上的客户端(节点)。
通过web3j,我们可以使用java语言很容易的完成:获取以太坊数据、发起以太坊交易、调用以太坊合约等操作。
二、infura:
官网:https://infura.io/
要使用web3j来发起以太坊上的操作,肯定需要至少一个以太坊节点,你当然可以使用geth等方式自己搭建一个eth节点,但是到笔者写文章为止,eth块高已经超过1100万块。先不提geth坑爹的同步速度,使用geth同步一个fast节点到当前块高也需要接近1t的硬盘,更别提所需的机器高配置成本了。
如果你只想体验一下web3j或者作为开发环境,那大可不必上来就大费周章自己搭建一个以太坊节点,找一个开放的以太坊节点岂不妙哉,而infura就是一个出色的开放以太坊节点,它提供了标准的RPC API可供开发者调用。值得一提的是,infura在支持ETH API的同时也支持IPFS API,关于ipfs相关会在后续文章讨论到。
现在只需简单的注册即可使用免费的infura服务了(注册貌似要科学上网),登陆成功后点击右上角巨大的CREATE NEW OBJECT 后就可以为你新建一个项目了,所需的rpc url如下图所示:
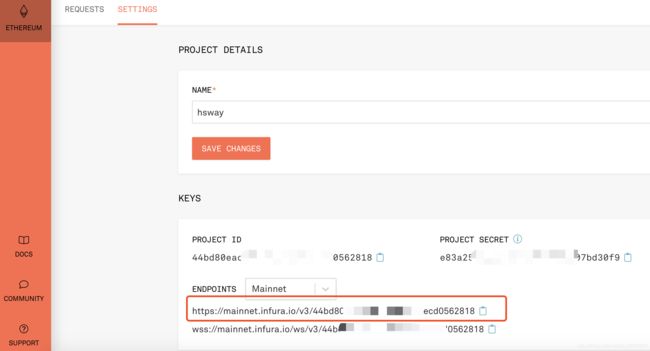
但需要注意的是,免费的infura只支持非常轻量级的rpc调用,对调用频率和次数都有限制,仅供开发阶段使用。如果真的像我们要完成的事情这样:获取以太坊所有块和交易信息,那infura的免费节点肯定是大大的不够用了(即使是付费版本可能也不够用),那时候就不得不自己搭建一个完整的以太坊节点了(只要配置够强,也只需要一晚上就同步完了啦)
正文
简单的介绍居然占据这么大的篇幅,正式开始主题,后续代码只介绍数据的获取,不涉及数据处理。
pom文件的maven依赖:
<dependency>
<groupId>org.web3j</groupId>
<artifactId>core</artifactId>
<version>4.1.1</version>
</dependency>
正式开始获取数据代码,碍于篇幅,web3j类源码会省略,建议读者打开idea结合源码阅读。
实例化web3j:
首先初始化web3j实例,用到的方法为 org.web3j.protocol.Web3j#build(org.web3j.protocol.Web3jService)
其中入参Web3jService是一个接口,他有很多种的实现类,包括http,websocket,ipc,我们使用到的是HttpService:
@Component
public class Web3jConfig {
// eth的rpc url 可使用上面提到的infura免费节点
@Value("${eth.chain.rpc}")
private String rpc;
private static Web3j web3j = null;
private synchronized Web3j init() {
if (!ObjectUtils.isEmpty(web3j)) {
return web3j;
}
// 实例化web3j
web3j = Web3j.build(new HttpService(rpc));
return web3j;
}
public Web3j getWeb3j() {
// 获取web3
if (!ObjectUtils.isEmpty(web3j)) {
return web3j;
}
return init();
}
}
获取块信息:
同步数据起始方法,初始化线程池、获取上次同步数据、开始获取block块信息:
// 线程池
private ThreadPoolExecutor executorService;
// 关闭程序时候记得调用dispose()
private Disposable subscribe;
@PostConstruct
public void scanInit() {
// 获取web3j实例
Web3j web3j = web3jConfig.getWeb3j();
// 线程池初始化
initExecutePool();
// 获取到上次同步最高块高
BigInteger max = searchIndex.ethBlockMaxNumber();
// 从上一次的最高块+1开始同步到最新块 注意第三个参数true代表获取全量的transaction数据
subscribe = web3j.replayPastBlocksFlowable(DefaultBlockParameter.valueOf(max.add(BigInteger.ONE)), DefaultBlockParameterName.LATEST, true)
.doOnError(e -> log.error("on error:{}", e.getMessage()))
// subscribe 获取到EthBlock, executeBlock 处理块信息
.subscribe(this::executeBlock, ex -> log.error("subscribe error:{}", ex.getMessage()))
;
}
获取transaction数据:
public void execute(Runnable r) {
executorService.execute(r);
}
public void executeBlock(EthBlock block) {
execute(() -> {
// 获取到所需的块信息
EthBlock.Block ethBlock = block.getBlock();
// transaction信息获取
executeTransaction(ethBlock.getTransactions());
});
}
获取log数据:
public void executeTransaction(List<EthBlock.TransactionResult> transactions) {
if (transactions.size() == 0) {
return;
}
try {
Web3j web3j = web3jConfig.getWeb3j();
for (EthBlock.TransactionResult<EthBlock.TransactionObject> transactionResult : transactions) {
EthBlock.TransactionObject transaction = transactionResult.get();
// log 数据的获取 记得过滤一下已经removed 的log数据
executeLog(receipt.getLogs());
// TransactionReceipt 数据获取
TransactionReceipt receipt = web3j.ethGetTransactionReceipt(transaction.getHash()).send().getResult();
}
} catch (IOException e) {
log.error("transaction input error, msg:{}", e.getMessage());
}
}
其实数据获取的代码其实并不复杂,主要是transaction和log的数据量会较大,后续的数据展示和分析会较难处理,eth的官方浏览器(https://etherscan.io/ 需)也只提供了最新500k的transaction的列表展示,作者最后的处理方式是每个块高的blcok、transaction、log数据打包bulk导入es中,直接使用es做后续的检索和数据分析,一个replicas节点的情况下,1100万块的索引数据量大概总共700g左右。
代码注释应该已经较为全面,如有疑问可留言讨论