不平衡数据-SMOTE综述
本文转载自:不平衡数据-SMOTE综述【SMOTE合成采样系列】
目录
引言
1.SMOTE 是什么
2.SMOTE 的原理
3.SMOTE 的改进算法
参考文献

引言
在机器学习中,使用常用算法进行分类时,如:逻辑回归、决策树、支持向量机、随机森林等,都假设数据集是平衡的,即:不同类别的数据在数量和质量上都是同等的。
然而,真实世界中大多数数据并不满足该要求,如:银行信用系统中,不守信用的客户是少数;又如:疾病诊断系统中,诊断为阳性的也是少数。倘若直接使用不平衡数据集并使用常用算法构建模型进行分类,结果是不理想的。
因此,解决不平衡数据带来的分类问题成了机器学习中的热点问题。
其常用解决方法大致可以分为三类:
(1)特征选择法:突出少数类的特征,从而提高算法对少数类的识别率。
(2)数据分布调整:使用欠采样、过采样、合成采样等方法调整使得少数类与多数类在数量和质量上同等,该方法可用于数据预处理阶段。
(3)模型训练算法调整:改进算法本身,加强算法对少数类的学习能力,从而提升少数类的识别率。
本文使用第二种方法,即:数据分布调整,主要介绍SMOTE合成采样及其变种算法。
通过阅读本文,你可以了解:
(1)SMOTE 是什么?
(2)SMOTE 的原理?
(3)SMOTE 的改进算法有哪些?
好啦,我们开始吧。

1.SMOTE 是什么
SMOTE,根据 SMOTE 原文:Synthetic Minority Over-sampling Technique(合成少数类样本的过采样技术),很多人把它归类于过采样,我个人更喜欢称它为合成采样(怎么称呼都随便,各有所爱啦)
SMOTE 是一种合成采样技术,即从少数类样本出发,找到邻近样本,合成新的少数类样本,使少数类样本数与多数类样本数保持一致。
在 SMOTE 合成采样技术问世之前,过采样技术基本是通过复制样本来增加样本数量(如:随机过采样技术)。然而,通过简单的样本复制仅仅增加了样本数量,而不能提升样本质量,数据依旧是不平衡的,因此,分类器只能重复学习同样的特征,对分类性能的提升是很有限的。
SMOTE 则通过合成新样本的方法,算法可以从更多新样本中学习到更有利于少数类分类的内容,因此,SMOTE 一经问世就很火热,至今成了过采样的经典算法。
2.SMOTE 的原理
对于合成样本,考虑的问题是:
(1)如何合成
(2)合成多少
SMOTE 如何合成新样本:
很简单,就是对所有少数类样本使用 k 近邻寻找邻近样本,然后进行直线随机插值,实现样本的合成。其中,插值的位置是随机的,每个样本点插值的数量是均等的(多余的随机删掉)。
具体插值过程如下图所示:
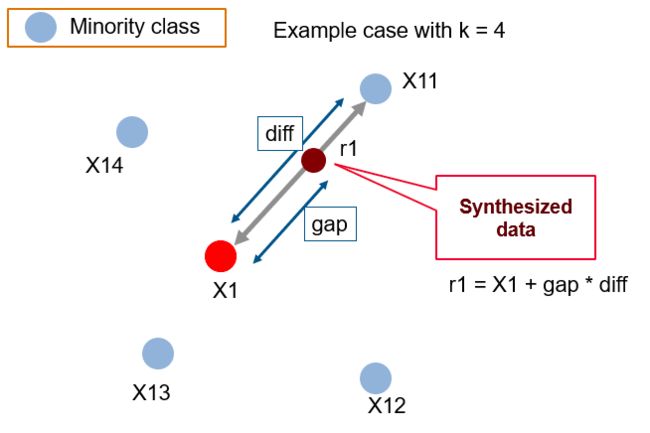
SMOTE 合成过程
图中设置 k 近邻中的 k=4,X1为少数类样本点,它找到了 X11,X12,X13,X14,这四个近邻样本点,在X1与X11之间的插值中,diff 是两样本点的距离,新生成的样本点 r1 在连接的直线上,gap 是 X1 到 X11 之间随机距离。通过公式: r1 = X1 + gap * diff 生成样本。
这就是 SMOTE 合成样本的过程。
针对于合成多少样本合适,主要还是需要依赖数据本身,不过,一般情况下都是1:1的方式合成样本最好,因为数据越平衡,其分类效果越好。
3.SMOTE 的改进算法
与之前随机过采样相比,SMOTE 合成样本更好,但同时 SMOTE 也存在一些不足,于是产生了很多改进算法。
其改进算法基本可以分为以下几类:
(1)在样本初始选择方面改进:
主要针对初始样本选择方面,SMOTE 选择了所有少数类样本作为插值的候选样本,但并不是所有少数类样本都适合插值,这种改进主要是针对噪声问题的,例如下图所示:
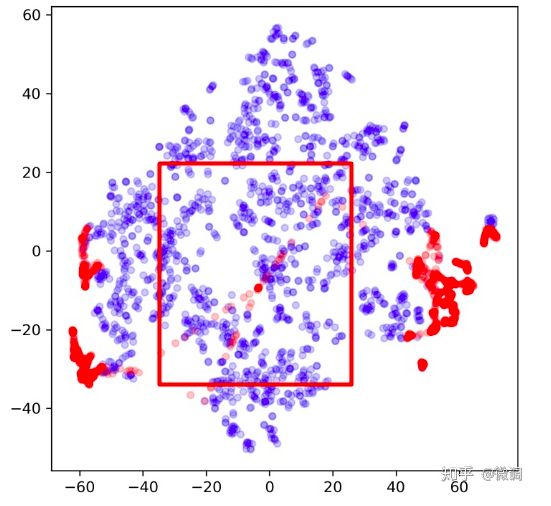
产生噪声点
如上图所示,SMOTE 可能会根据噪声点来插值,从而形成更多的噪声点。
这方面的改进比较有名的就是:Borderline-SMOTE 了。
该算法将少数类样本点分为:安全点、边缘点和危险点,三类,并且仅对边缘点进行插值,因为作者认为,边缘点在分类中作用更大,突出边缘点更有利于分类。
(2)与欠采样结合:
这种就很容易理解了,即:使用 SMOTE 合成更多少数类样本,结合对多数类的欠采样。
(3)插值类型的改进:
SMOTE 的插值很简单,使用的是随机线性插值法,因此具有盲目性,新生成样本不一定能精准的在合适的位置上。
其改进算法有,通过限制插值范围来改进插值的盲目性问题;或者使用特征加权来生成新样本;或者基于聚类来插值;或者基于图论来插值;或者基于分布插值。等等。
这些改进的插值技术,都是从插值类型出发来提高生成样本的质量。
(4)与特征选择或降维相结合:
先对样本集进行特征选择或降维操作,然后在新维度空间中使用 SMOTE 生成样本。例如:先进行 PCA,然后再使用 SMOTE 生成样本。
这种主要针对高维数据,通过降维后生成的样本更具有代表性。
(5)自适应生成样本:
该方法的原理是:通过学习难度自动调节样本权值来生成样本。使用该方法较为经典的算法有:ADASYN。
由于,目前没单独了解该算法,就不深入探讨了,请见谅。
(6)筛选出有噪声的样本:
主要针对 SMOTE 合成样本具有生成重叠样本和噪声样本的问题,使用某种噪声过滤技术,筛选出噪声样本,生成高质量的样本。可使用很多策略来过滤噪声,例如:使用贪婪滤波策略、基于集成技术的过滤策略、基于进化的过滤策略等等。
从以上改进算法可以看出,SMOTE 的发展已经很成熟了,改进算法也挺全面的。所以,可以安全使用,谨慎改进。

嘿嘿
我终于写完了,谢谢你看完了。
下篇文章,我将详细讲解 SMOTE 源码。
参考文献
[1]SMOTE: Synthetic Minority Over-sampling Technique.
[2]Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning.
[3]SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-year Anniversary.