数据湖(五):Hudi与Hive集成

大数据联盟地址:https://bbs.csdn.net/forums/lanson
文章目录
Hudi与Hive集成
一、配置HiveServer2
1、在Hive服务端配置hive-site.xml
2、在每台Hadoop 节点配置core-site.xml,记得发送到所有节点
3、重启HDFS ,Hive ,在Hive服务端启动Metastore 和 HiveServer2服务
4、在客户端通过beeline连接Hive
二、代码层面集成Hudi与Hive
1、COW模式-SparkSQL代码写入Hudi同时映射Hive表
2、MOR模式-SparkSQL代码写入Hudi同时映射Hive表
三、手动层面集成Hudi与Hive
四、SparkSQL操作映射的Hive表
Hudi与Hive集成
一、配置HiveServer2
Hudi与Hive集成原理是通过代码方式将数据写入到HDFS目录中,那么同时映射Hive表,让Hive表映射的数据对应到此路径上,这时Hudi需要通过JDBC方式连接Hive进行元数据操作,这时需要配置HiveServer2。
1、在Hive服务端配置hive-site.xml
#在Hive 服务端 $HIVE_HOME/conf/hive-site.xml中配置:
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
192.168.179.4
hive.zookeeper.quorum
node3:2181,node4:2181,node5:2181
注意:“hive.zookeeper.quorum”搭建hiveserver2HA使用配置项,可以不配置,如果不配置启动hiveServer2时一直连接本地zookeeper,导致大量错误日志(/tmp/root/hive.log),从而导致通过beeline连接当前node1节点的hiveserver2时不稳定,会有连接不上错误信息。
2、在每台Hadoop 节点配置core-site.xml,记得发送到所有节点
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
3、重启HDFS ,Hive ,在Hive服务端启动Metastore 和 HiveServer2服务
[root@node1 conf]# hive --service metastore &
[root@node1 conf]# hive --service hiveserver2 &4、在客户端通过beeline连接Hive
[root@node3 test]# beeline
beeline> !connect jdbc:hive2://node1:10000 root
Enter password for jdbc:hive2://node1:10000: **** #可以输入任意密码,没有验证
0: jdbc:hive2://node1:10000> show tables; 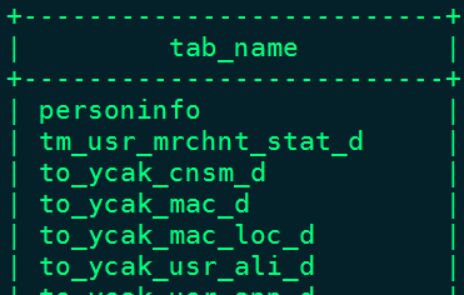
二、代码层面集成Hudi与Hive
我们可以通过SparkSQL将数据保存到Hudi中同时也映射到Hive表中。映射有两种模式,如果Hudi表是COPY_ON_WRITE类型,那么映射成的Hive表对应是指定的Hive表名,此表中存储着Hudi所有数据。
如果Hudi表类型是MERGE_ON_READ模式,那么映射的Hive表将会有2张,一张后缀为rt ,另一张表后缀为ro。后缀rt对应的Hive表中存储的是Base文件Parquet格式数据+*log* Avro格式数据,也就是全量数据。后缀为ro Hive表中存储的是存储的是Base文件对应的数据。
1)在pom.xml中加入一下依赖
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>1.2.1version>
dependency>
2)将对应依赖包放入Hive节点对应的lib目录下
将hudi-hadoop-mr-bundle-0.8.0.jar、parquet-column-1.10.1.jar、parquet-common-1.10.1.jar、parquet-format-2.4.0.jar、parquet-hadoop-1.10.1.jar包存入Hive lib目录下。由于Hudi表数据映射到Hive表后,Hive表底层存储格式为“HoodieParquetInputFormat”或者“HoodieParquetRealtimeInputFormat”,解析Parquet数据格式时使用到以上各个包。可以从Maven中下载以上包后,将这些包上传到所有Hive节点的lib目录下,包括服务端和客户端。
3)启动Hive MetaStore与Hive Server2服务
[root@node1 conf]# hive --service metastore &
[root@node1 conf]# hive --service hiveserver2 &4)将hive-site.xml放入项目resources目录中
后期Hudi映射Hive表后,会自动检查Hive元数据,这时需要找到配置文件连接Hive。
1、COW模式-SparkSQL代码写入Hudi同时映射Hive表
1)COW模式代码如下
//1.创建对象
val session: SparkSession = SparkSession.builder().master("local").appName("insertDataToHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//2.创建DataFrame
val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\jsondata.json")
import org.apache.spark.sql.functions._
//3.向Hudi中插入数据 - COW模式
insertDF
.write.format("hudi")
//设置写出模式,默认就是COW
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//指定分区列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
//并行度设置
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
//关于Hive设置
//指定HiveServer2 连接url
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY,"jdbc:hive2://node1:10000")
//指定Hive 对应的库名
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY,"default")
//指定Hive映射的表名称
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY,"infos1")
//Hive表映射对的分区字段
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY,"loc")
//当设置为true时,注册/同步表到Apache Hive metastore,默认是false,这里就是自动创建表
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY,"true")
//如果分区格式不是yyyy/mm/dd ,需要指定解析类将分区列解析到Hive中
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY,classOf[MultiPartKeysValueExtractor].getName)
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")2)查询Hive中数据
hive> show tables;
infos1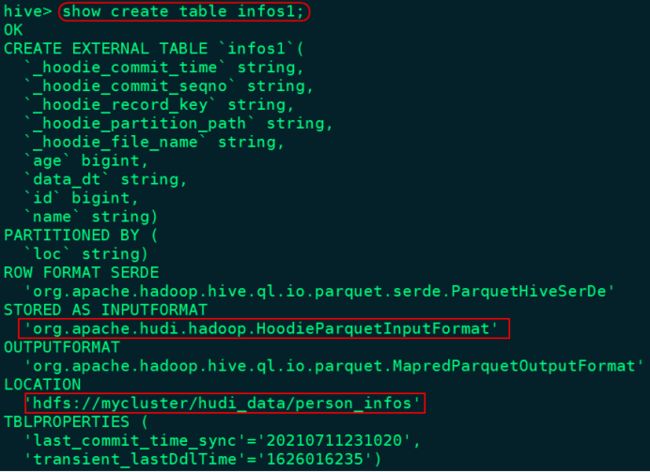
hive> set hive.cli.print.header=true;
hive> select * from infos1;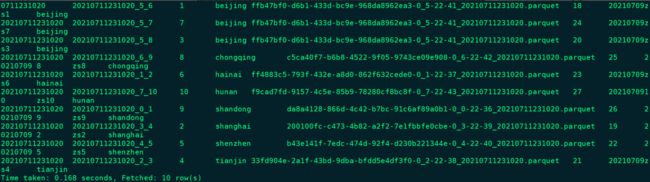
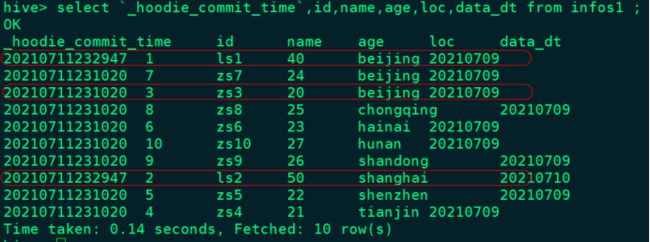
hive> select `_hoodie_commit_time`,id,name,age,loc,data_dt from infos1; 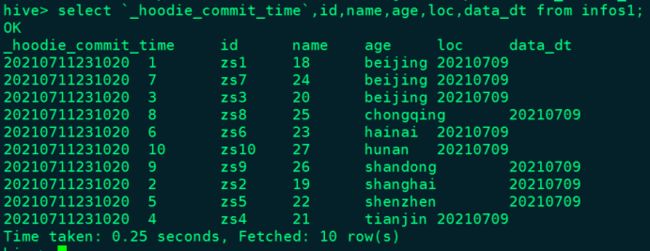
3)更新表中数据,再次查询Hive中的数据
//4.更新数据,查询Hive数据
//读取修改数据
val updateDataDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\updatedata.json")
//向Hudi 更新数据
updateDataDF.write.format("org.apache.hudi")
//设置写出模式,默认就是COW
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,"loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
//关于Hive设置
//指定HiveServer2 连接url
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY,"jdbc:hive2://node1:10000")
//指定Hive 对应的库名
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY,"default")
//指定Hive映射的表名称
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY,"infos1")
//Hive表映射对的分区字段
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY,"loc")
//当设置为true时,注册/同步表到Apache Hive metastore,默认是false,这里就是自动创建表
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY,"true")
//如果分区格式不是yyyy/mm/dd ,需要指定解析类将分区列解析到Hive中
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY,classOf[MultiPartKeysValueExtractor].getName)
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")每次查询都是查询最后一次数据结果
2、MOR模式-SparkSQL代码写入Hudi同时映射Hive表
1)MOR代码如下
//1.创建对象
val session: SparkSession = SparkSession.builder().master("local").appName("insertDataToHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//2.创建DataFrame
val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\jsondata.json")
import org.apache.spark.sql.functions._
//3.向Hudi中插入数据 - COW模式
insertDF
.write.format("hudi")
//设置写出模式,默认就是COW
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//指定分区列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
//并行度设置
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置,不能重复,重复会报错
.option(HoodieWriteConfig.TABLE_NAME, "person_infos2")
//关于Hive设置
//指定HiveServer2 连接url
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY,"jdbc:hive2://node1:10000")
//指定Hive 对应的库名
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY,"default")
//指定Hive映射的表名称
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY,"infos2")
//Hive表映射对的分区字段
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY,"loc")
//当设置为true时,注册/同步表到Apache Hive metastore,默认是false,这里就是自动创建表
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY,"true")
//如果分区格式不是yyyy/mm/dd ,需要指定解析类将分区列解析到Hive中
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY,classOf[MultiPartKeysValueExtractor].getName)
.mode(SaveMode.Append)
.save("/hudi_data/person_infos2")
2)查询Hive表中的数据
hive> show tables; 
注意:infos2_ro 中存储的只是Base文件中数据(parquet列式存储结果)
infos2_rt 中存储的是Base文件(Parquet列式存储结果)+*log*(Avro行式存储结果)
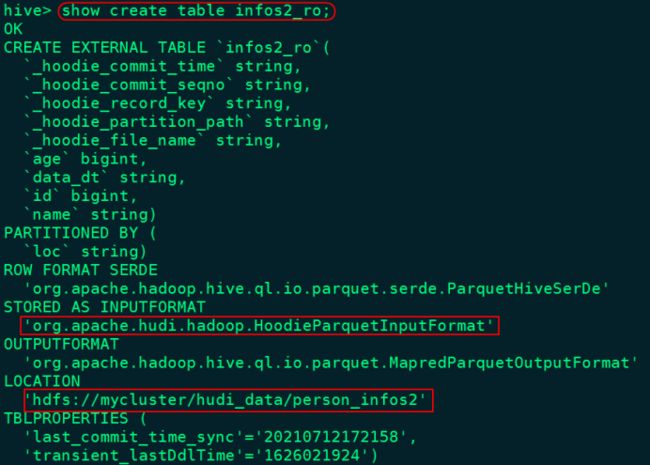
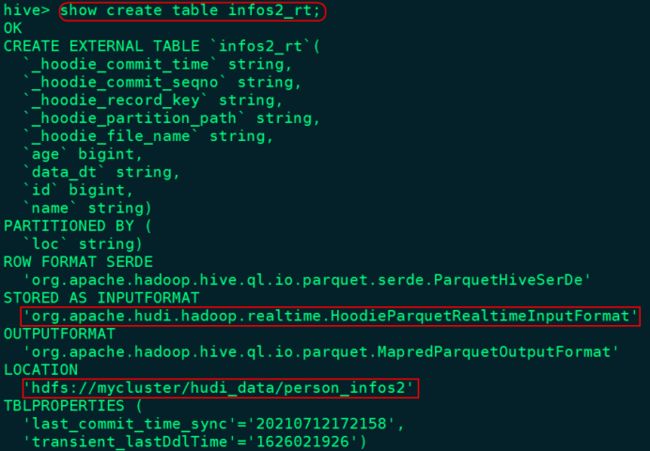
hive> select * from infos2_ro;目前只有Base文件数据,查询的就是全量数据
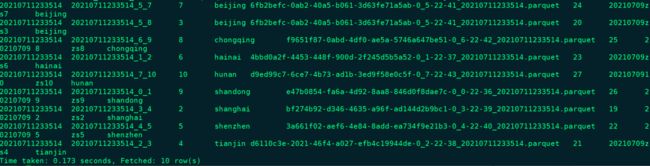
hive> select * from infos2_rt;目前只有Base文件数据,查询的就是全量数据

hive> select `_hoodie_commit_time`,id,name,age,loc,data_dt from infos2_ro; 
hive> select `_hoodie_commit_time`,id,name,age,loc,data_dt from infos2_rt;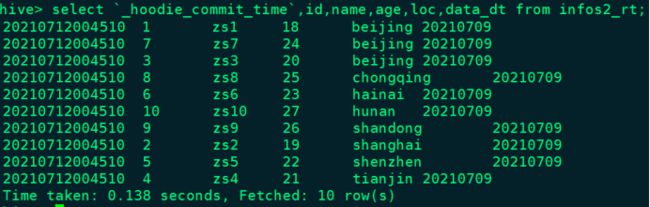
3)更新表中数据,再次查询Hive中的数据
//4.更新数据,查询Hive数据
//读取修改数据
val updateDataDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\updatedata.json")
//向Hudi 更新数据,注意,必须指定Hive对应配置
updateDataDF.write.format("org.apache.hudi")
//设置写出模式,默认就是COW
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,"loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos2")
//关于Hive设置
//指定HiveServer2 连接url
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY,"jdbc:hive2://node1:10000")
//指定Hive 对应的库名
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY,"default")
//指定Hive映射的表名称
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY,"infos2")
//Hive表映射对的分区字段
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY,"loc")
//当设置为true时,注册/同步表到Apache Hive metastore,默认是false,这里就是自动创建表
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY,"true")
//如果分区格式不是yyyy/mm/dd ,需要指定解析类将分区列解析到Hive中
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY,classOf[MultiPartKeysValueExtractor].getName)
.mode(SaveMode.Append)
.save("/hudi_data/person_infos2")查询Hive中对应两张表的数据结果
查询Base文件中的数据
hive> select `_hoodie_commit_time`,id,name,age,loc,data_dt from infos2_ro;
查询Base文件+log文件中数据,可以看到查询到的是修改后的结果数据
hive> select `_hoodie_commit_time`,id,name,age,loc,data_dt from infos2_rt;
三、手动层面集成Hudi与Hive
如果已经存在Hudi数据,我们也可以手动创建对应的Hive表来映射对应的Hudi数据,使用Hive SQL来操作Hudi。例如使用如下代码在HDFS中存储Hudi数据,这里采用MOR模式写入数据,方便后期测试:
1)向Hudi表中写入数据
//1.创建对象
val session: SparkSession = SparkSession.builder().master("local").appName("insertDataToHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//2.创建DataFrame
val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\jsondata.json")
import org.apache.spark.sql.functions._
//3.向Hudi中插入数据 - COW模式
insertDF
.write.format("hudi")
//设置写出模式,默认就是COW
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//指定分区列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
//并行度设置
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME, "person_infos3")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos3")2)在Hive中创建对应的表数据
在Hive中创建表person3_ro,映射Base数据,相当于前面的ro表:
// 创建外部表,这种方式只会查询出来parquet数据文件中的内容,但是刚刚更新或者删除的数据不能查出来
CREATE EXTERNAL TABLE `person3_ro`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,`name` string,
`age` bigint,`data_dt` string)
PARTITIONED BY (`loc` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 'hdfs://mycluster/hudi_data/person_infos3';建好以上对应的表之后,由于有分区,还看不到数据,所以这里需要我们手动映射分区数据:
alter table person3_ro add if not exists partition(loc="beijing") location 'hdfs://mycluster/hudi_data/person_infos3/beijing';
alter table person3_ro add if not exists partition(loc='chongqing') location 'hdfs://mycluster/hudi_data/person_infos3/chongqing';
alter table person3_ro add if not exists partition(loc='hainai') location 'hdfs://mycluster/hudi_data/person_infos3/hainai';
alter table person3_ro add if not exists partition(loc='hunan') location 'hdfs://mycluster/hudi_data/person_infos3/hunan';
alter table person3_ro add if not exists partition(loc='shandong') location 'hdfs://mycluster/hudi_data/person_infos3/shandong';
alter table person3_ro add if not exists partition(loc='shanghai') location 'hdfs://mycluster/hudi_data/person_infos3/shanghai';
alter table person3_ro add if not exists partition(loc='shenzhen') location 'hdfs://mycluster/hudi_data/person_infos3/shenzhen';
alter table person3_ro add if not exists partition(loc='tianjin') location 'hdfs://mycluster/hudi_data/person_infos3/tianjin';查看表数据

在Hive中创建表person3_rt,映射Base+log数据,相当于rt表,并映射分区:
// 这种方式会将基于Parquet的基础列式文件、和基于行的Avro日志文件合并在一起呈现给用户。
CREATE EXTERNAL TABLE `person3_rt`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,`name` string,
`age` bigint,`data_dt` string)
PARTITIONED BY (`loc` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 'hdfs://mycluster/hudi_data/person_infos3'; 加载对应分区数据数据
alter table person3_rt add if not exists partition(loc="beijing") location 'hdfs://mycluster/hudi_data/person_infos3/beijing';
alter table person3_rt add if not exists partition(loc='chongqing') location 'hdfs://mycluster/hudi_data/person_infos3/chongqing';
alter table person3_rt add if not exists partition(loc='hainai') location 'hdfs://mycluster/hudi_data/person_infos3/hainai';
alter table person3_rt add if not exists partition(loc='hunan') location 'hdfs://mycluster/hudi_data/person_infos3/hunan';
alter table person3_rt add if not exists partition(loc='shandong') location 'hdfs://mycluster/hudi_data/person_infos3/shandong';
alter table person3_rt add if not exists partition(loc='shanghai') location 'hdfs://mycluster/hudi_data/person_infos3/shanghai';
alter table person3_rt add if not exists partition(loc='shenzhen') location 'hdfs://mycluster/hudi_data/person_infos3/shenzhen';
alter table person3_rt add if not exists partition(loc='tianjin') location 'hdfs://mycluster/hudi_data/person_infos3/tianjin';查看结果数据

3)使用代码修改Hudi表中的数据:
修改数据如下:
{"id":1,"name":"ls1","age":40,"loc":"beijing","data_dt":"20210709"}
{"id":2,"name":"ls2","age":50,"loc":"shanghai","data_dt":"20210710"}
{"id":3,"name":"ls3","age":60,"loc":"ttt","data_dt":"20210711"}//4.更新数据,查询Hive数据
//读取修改数据
val updateDataDF: DataFrame = session.read.json("file:///D:\\2018IDEA_space\\SparkOperateHudi\\data\\updatedata.json")
//向Hudi 更新数据
updateDataDF.write.format("org.apache.hudi")
//设置写出模式,默认就是COW
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,"loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos3")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos3")4)继续查询对应的两张Hive表数据
由于分区 “ttt”是新加入的分区,需要手动添加下分区才能在对应的Hive表中正常查询
alter table person3_ro add if not exists partition(loc="ttt") location 'hdfs://mycluster/hudi_data/person_infos3/ttt';
alter table person3_rt add if not exists partition(loc="ttt") location 'hdfs://mycluster/hudi_data/person_infos3/ttt';查询表person3_ro
hive> select * from person3_ro;
查询表person3_rt
hive> select * from person3_rt;
此外,我们也可以不需要每次都自己手动添加分区,而是创建好对应的Hive表后,在代码中向Hudi中写数据时,指定对应的Hive参数即可,这样写入的数据自动会映射到Hive中。
我们可以删除Hive对应的表数据重新创建以及第一次加载分区,再后续写入Hudi表数据时,代码如下,就不需要每次都手动加载Hive分区数据。
//5.更新数据,指定Hive配置项
//读取修改数据
val updateDataDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\updatedata.json")
//向Hudi 更新数据
updateDataDF.write.format("org.apache.hudi")
//设置写出模式,默认就是COW
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,"loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos3")
//关于Hive设置
//指定HiveServer2 连接url
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY,"jdbc:hive2://node1:10000")
//指定Hive 对应的库名
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY,"default")
//指定Hive映射的表名称
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY,"person3")
//Hive表映射对的分区字段
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY,"loc")
//当设置为true时,注册/同步表到Apache Hive metastore,默认是false,这里就是自动创建表
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY,"true")
//如果分区格式不是yyyy/mm/dd ,需要指定解析类将分区列解析到Hive中
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY,classOf[MultiPartKeysValueExtractor].getName)
.mode(SaveMode.Append)
.save("/hudi_data/person_infos3")查询Hive表 peson3_ro数据

查询Hive表 person3_rt数据

四、SparkSQL操作映射的Hive表
将Hudi数据映射到Hive后,我们可以使用SparkSQL来进行操作Hive表进行处理。操作代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("test")
.config("hive.metastore.uris", "thrift://node1:9083")
.enableHiveSupport()
.getOrCreate()
session.sql("use default")
session.sql(
"""
| select id,name,age,loc,data_dt from person3_rt
""".stripMargin).show()
session.sql(
"""
| select sum(age) as totalage from person3_rt
""".stripMargin).show()我们可以看到如果针对Hudi表中的数据进行修改,那么SpakSQL读取到的就是最新修改后的结果数据。
- 博客主页:https://lansonli.blog.csdn.net
- 欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
- 本文由 Lansonli 原创,首发于 CSDN博客
- 停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨