Flink1.12.2集成hudi0.9.0+同步hive实践
目录
一、组件下载
二、Batch模式实施步骤:
2.1 启动flink-sql客户端
2.2 创建表
2.3插入数据
2.4 根据主键更新数据
三、stream模式实现步骤:
3.1 创建表
3.2 从批模式写入一条数据
3.3 隔几秒后在流模式可以读取到一条新增的数据
四.Hive 同步
4.1 hudi编译:
4.2. Hive 环境准备
1.启动hive元数据
2.在 Hive 服务器导入 Hudi 包
4.3. Hive 配置模版
3.1源表的建表语句:
3.1 hms mode 配置
3.2 jdbc mode 配置
4.4. Hive 查询
一、组件下载
Flink1.12.2 hudi0.9.0
Flink1.12.2 集成hudi0.9.0普通的测试直接用官方的发版的包就行.这个简单,我简单写一下.同步hive是重点.
二、Batch模式实施步骤:
导包 hudi-flink到flink lib目录下
2.1 启动flink-sql客户端
可以提前把hudi-flink-bundle_2.12-0.9.0-SNAPSHOT.jar拷贝到 $FLINK_HOME/lib目录下(我用的flink是scala2.12版本)
#HADOOP_HOME是解压二进制包后的hadoop根目录。
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
#启动flink单机集群
./bin/sql-client.sh embedded2.2 创建表
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/hudi/t1'
);
CREATE TABLE t3(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/hudi/t2',
'table.type' = 'MERGE_ON_READ',
'compaction.tasks'='5'
);2.3插入数据
INSERT INTO t1 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
#查询表数据,设置一下查询模式为tableau
set execution.result-mode=tableau;2.4 根据主键更新数据
INSERT INTO t1 VALUES ('id1','Danny',24,TIMESTAMP '1970-01-01 00:00:01','par1');id1的数据age由23变为了24
三、stream模式实现步骤:
3.1 创建表
CREATE TABLE t2(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/hudi/t1',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '4'
);
这里将 table option read.streaming.enabled 设置为 true,表明通过 streaming 的方式读取表数据;
opiton read.streaming.check-interval 指定了 source 监控新的 commits 的间隔为 4s;
option table.type 设置表类型为 MERGE_ON_READ,目前只有 MERGE_ON_READ 表支持 streaming 读3.2 从批模式写入一条数据
insert into t1 values ('id9','yangge',27,TIMESTAMP '1970-01-01 00:00:01','par5');3.3 隔几秒后在流模式可以读取到一条新增的数据
四.Hive 同步
4.1 hudi编译:
下载hudi0.9.0的源码,本地编译.
需要修改的地方,就一个将编译的hive的版本从2.3.1调整为2.3.6

执行以下命令打入 Hive 依赖:
mvn install -DskipTests -Drat.skip=true -Pflink-bundle-shade-hive2 注意事项:这很重要
不需要指定这个 -Pinclude-flink-sql-connector-hive
也不需要指定hadoop的版本 -Dhadoop.version=2.7.5
hadoop版本如果和源码的区别比较大,可以尝试指定
# 如果是 hive3 需要使用 profile -Pflink-bundle-shade-hive3
# 如果是 hive1 需要使用 profile -Pflink-bundle-shade-hive1
#注意1:hive1.x现在只能实现同步metadata到hive,而无法使用hive查询,如需查询可使用spark查询hive外表的方法查询。
#注意2: 使用-Pflink-bundle-shade-hive x,
需要修改profile中hive的版本为集群对应版本(只需修改profile里的hive版本)。
修改位置为packaging/hudi-flink-bundle/pom.xml最下面的对应profile段,
找到后修改profile中的hive版本为对应版本即可。特别注意:(这步注意了一次性成功)
现在版本的hudi,在编译的时候本身默认就已经集成的flink-SQL-connector-hive的包.会和Flink lib包下的flink-SQL-connector-hive冲突.所以,编译的过程中只修改hive的编译版本就行.
并且Flink的lib下面不能有flink-sql-connector-hive-2.3.6_2.11-1.12.2.jar
Flink lib包有如下几个就行
hive的包和flink-sql-connector-hive-2.3.6_2.11-1.12.2.jar都别加,这个很重要.
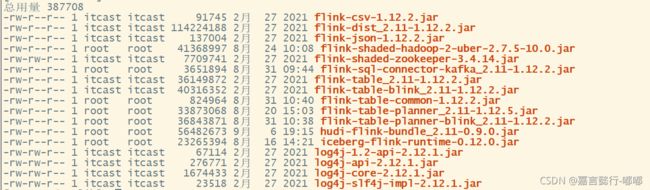
4.2. Hive 环境准备
Flink Client远程连接Hive的时候,要求Hive的 Hive-metastore 和 HiveServer2 两个服务都开启:
开启的命令: 在hive目录下执行:
1.启动hive元数据
nohup /export/servers/hive/bin/hive --service metastore &
nohup /export/servers/hive/bin/hive --service hiveserver2 &2.在 Hive 服务器导入 Hudi 包
在 Hive 服务器下创建 auxlib/ 文件夹,并把hudi install后packaging/hudi-hadoop-mr-bundle/target目录下的hudi-hadoop-mr-bundle.jar 放入其中,否则会报
FAILED: SemanticException Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat'注意:每次换包都需要重启hive的服务
解法:
1.将 hudi-hadoop-mr-bundle-0.9.0-SNAPSHOT.jar 添加到hive 目录下,
例如: cp /opt/software/hudi-hadoop-mr-bundle-0.9.0-SNAPSHOT.jar $HIVE_HOME/auxlib/
2.重启 Hive: // 按照需求选择合适的方式重启
nohup /export/servers/hive/bin/hive --service metastore &
nohup /export/servers/hive/bin/hive --service hiveserver2 &4.3. Hive 配置模版
Flink hive sync 现在支持两种 hive sync mode, 分别是 hms 和 jdbc 模式。 其中 hms 只需要配置 metastore uris;而 jdbc 模式需要同时配置 jdbc 属性 和 metastore uris,具体配置模版如下:
3.1源表的建表语句:
1.批表的建表语句
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/hudi/t1'
);
2.流表的建表语句
CREATE TABLE t2(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/hudi/t2',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210901151206' ,
'read.streaming.check-interval' = '4'
);3.1 hms mode 配置
1.批模式hms模式的建表语句:
CREATE TABLE t11(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' ='hdfs://node1:8020/hudi/t1',
'table.type'='COPY_ON_WRITE', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.mode' = 'hms', -- required, 将hive sync mode设置为hms, 默认jdbc
'hive_sync.metastore.uris' = 'thrift://node1:9083', -- required, metastore的端口
'hive_sync.table'='t11', -- required, hive 新建的表名
'hive_sync.db'='default' -- required, hive 新建的数据库名
);
2.流模式的hms模式的建表语句并且指定了并行度:
CREATE TABLE t12(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' ='hdfs://node1:8020/hudi/t1',
'table.type'='COPY_ON_WRITE', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.mode' = 'hms', -- required, 将hive sync mode设置为hms, 默认jdbc
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210901151206' ,
'read.streaming.check-interval' = '4',
'hive_sync.metastore.uris' = 'thrift://node1:9083' ,
'hive_sync.table'='t12', -- required, hive 新建的表名
'hive_sync.db'='default', -- required, hive 新建的数据库名
'write.tasks'='1',
'compaction.tasks'='1'
);
3.t2表的批模式hms模式的建表语句:
CREATE TABLE t13(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' ='hdfs://node1:8020/hudi/t2',
'table.type'='MERGE_ON_READ', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.mode' = 'hms', -- required, 将hive sync mode设置为hms, 默认jdbc
'hive_sync.metastore.uris' = 'thrift://node1:9083', -- required, metastore的端口
'hive_sync.table'='t13', -- required, hive 新建的表名
'hive_sync.db'='default' -- required, hive 新建的数据库名
);
4.t2表的流模式的hms模式的建表语句并且指定了并行度:
CREATE TABLE t14(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' ='hdfs://node1:8020/hudi/t2',
'table.type'='MERGE_ON_READ', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.mode' = 'hms', -- required, 将hive sync mode设置为hms, 默认jdbc
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210901151206' ,
'read.streaming.check-interval' = '4',
'hive_sync.metastore.uris' = 'thrift://node1:9083' ,
'hive_sync.table'='t14', -- required, hive 新建的表名
'hive_sync.db'='default', -- required, hive 新建的数据库名
'write.tasks'='1',
'compaction.tasks'='1'
);
3.2 jdbc mode 配置
1.批模式 jdbc mode模式的建表语句:
CREATE TABLE t15(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' = 'hdfs://node1:8020/hudi/t1',
'table.type'='COPY_ON_WRITE', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.metastore.uris' = 'thrift://node1:9083', -- required, metastore的端口
'hive_sync.jdbc_url'='jdbc:hive2://node1:10000', -- required, hiveServer地址
'hive_sync.table'='t15', -- required, hive 新建的表名
'hive_sync.db'='default', -- required, hive 新建的数据库名
'hive_sync.username'='root', -- required, HMS 用户名
'hive_sync.password'='123456'
);
2.流模式 jdbc mode模式的建表语句带并行度:
CREATE TABLE t16(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' = 'hdfs://node1:8020/hudi/t1',
'table.type'='COPY_ON_WRITE', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.metastore.uris' = 'thrift://node1:9083', -- required, metastore的端口
'hive_sync.jdbc_url'='jdbc:hive2://node1:10000', -- required, hiveServer地址
'hive_sync.table'='t16', -- required, hive 新建的表名
'hive_sync.db'='default', -- required, hive 新建的数据库名
'hive_sync.username'='root', -- required, HMS 用户名
'hive_sync.password'='123456' ,
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210901151206' ,
'read.streaming.check-interval' = '4' ,
'write.tasks'='1',
'compaction.tasks'='1' -- required, HMS 密码
);
3.关于t2的批模式 jdbc mode模式的建表语句:
CREATE TABLE t17(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' ='hdfs://node1:8020/hudi/t2',
'table.type'='MERGE_ON_READ', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.metastore.uris' = 'thrift://node1:9083', -- required, metastore的端口
'hive_sync.jdbc_url'='jdbc:hive2://node1:10000', -- required, hiveServer地址
'hive_sync.table'='t17', -- required, hive 新建的表名
'hive_sync.db'='default', -- required, hive 新建的数据库名
'hive_sync.username'='root', -- required, HMS 用户名
'hive_sync.password'='123456' ,
'write.tasks'='1',
'compaction.tasks'='1'
);
4.关于t2的流模式 jdbc mode模式的建表语句:
CREATE TABLE t18(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector'='hudi',
'path' ='hdfs://node1:8020/hudi/t2',
'table.type'='MERGE_ON_READ', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
'hive_sync.enable'='true', -- required,开启hive同步功能
'hive_sync.metastore.uris' = 'thrift://node1:9083', -- required, metastore的端口
'hive_sync.jdbc_url'='jdbc:hive2://node1:10000', -- required, hiveServer地址
'hive_sync.table'='t18', -- required, hive 新建的表名
'hive_sync.db'='default', -- required, hive 新建的数据库名
'hive_sync.username'='root', -- required, HMS 用户名
'hive_sync.password'='123456' ,
'write.tasks'='1',
'compaction.tasks'='1',
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210901151206' ,
'read.streaming.check-interval' = '4'
);jobmanger移动要出现这个日志才算是同步hive成功
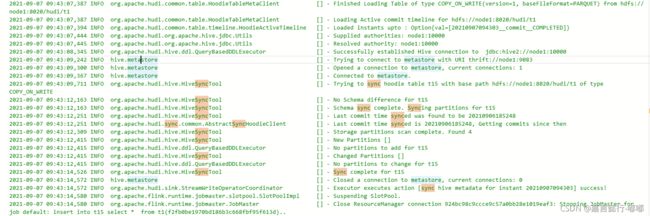
注意:在FlinkSQL建hive同步表,数据不会自动同步,还需要手动记性insert into插入
比如:
insert into t15 select * from t1;4.4. Hive 查询
使用 beeline 查询时需要手动设置:
set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;自动同步以后在beebline客户点查询的效果是这样的.

想加入博主Flink交流区群的小伙伴,可以把自己的微信号留言在下方,博主拉你们进群.(学习互助分享群)