Elasticsearch学习-ES中的一些组件介绍
ES是什么
Elastic Search简称ES, 是一个高性能的全文检索框架。它提供存储、搜索、大数据准实时分析等。一般用于提供复杂搜索的服务。
ES是基于Lucene进行二次开发的一个框架,首先Lucene是一个类库,业务系统中想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,除此之外,Lucene本身比较复杂,你需要深入了解检索的相关知识来理解它是如何工作的,而经过ES进行二次开发后,将这些复杂专业的细节内容进行了封装,可以让使用者以较低的学习成本来使用ES。
说了以上的介绍,你可能还不清楚使用ES的业务场景,可能会感觉直接使用关系型数据mysql是不是也可以满足需求,那么我们看一下下面几个需求场景:
1.业务数据量级是十亿,百亿级别。
2.需要提供复杂的全文检索能力。
3.具备复杂的数据分析能力。
对于以上3个需求,如果使用mysql等一些关系型数据库的话,实现起来会比较困难,需要复杂部署架构来实现海量的存储,同时还需要建立复杂的索引结构,才能实现部分全文检索能力,而且这套架构的扩展性和可维护性都比较差,具体可以参考下图:

而使用ES则可以很好的解决上述问题。但也并不是说,有了ES我们就不需要mysql了,在事务性操作的业务场景,ES是很难满足需求的,以为ES不具备事务性处理能力。ES只是在某些特殊业务场景的一种解决方案,和myql之间是互相补充的关系,而不是互相替代的关系。
ok,说了这么多,下面我们正式开始进入ES的内容学习中来。作为本系列的第一篇文章,我们先来学习一下ES中的一些基本组件和概念。
ES中的基本概念介绍
集群
ES之所以可以储存海量数据和高性能的检索,主要依托ES的集群架构,以及灵活的扩展性。在ES中的集群中,一个运行中的 Elastic Search 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据,保证每个节点负载均衡。
节点
在集群中的多个节点中,按照角色可以分为两种:主节点和从节点,通常来说,在一个集群中,有一个主节点多个从节点。主节点是集群中的所有节点中选举产生的。
当一个节点被选举成为主节点后, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。
索引和分片
索引在ES中既是一个名词也是一个动词。
作为名词时,索引是数据存储的逻辑单元,是一批数据的集合,类似于关系型数据中的数据表。
作为动词时,索引可以理解成将一条记录更新到索引中的过程,因为一条记录插入到一个索引的过程就是将这条记录建立倒排索引的过程。
索引中数据的存储,是以分片为单位,存放到分片上的。那么分片又是什么呢?
分片在ES中是一个底层的工作单元 ,它仅保存了索引全部数据中的一部分,每个分片是一个Lucene的实例,它本身就是一个完整的搜索引擎。 索引中的数据被存储和索引到分片内。但是当应用程序进行数据的存储和检索的时,是和索引进行打交道,而无需关心分片等细节。
在创建索引时,会设置该索引的分片数目,以及每个分片的副本个数,有经验的老铁一定很快就会意识到,副本机制是实现故障转移,保证数据高可用的一种常用手段,因为每个分区就是一个存储和计算的单元,所以通过调整一个索引的分片个数可以提升索引存储数据的容量和计算能力。
为了更好的利用集群中每个节点的硬件资源,索引的主分片和从分片,会被均匀的分布到不同的节点上。这样每个分片都可以充分利用所在节点的存储和计算资源。因为每个副分片上的数据,都是对主分片上数据的备份,所以一个索引可以存储的数据量取决于主分片的个数,以及每个主分片可以使用的硬件资源。
为了更好的理解集群,节点和分片之间的关系,我们在一个有两个节点的集群中创建一个3分区,1副本的索引:
PUT /myindex
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
分片在节点上的分布如下:

在上图中,有一个名字为mycluster的集群,集群中有两个节点,一个主节点和一个从节点。索引myindex有6个分区,3个主分片和3个副分片,均匀分布在的2个节点上。
集群的状态
ES集群的健康状态可以分为三种:green,yellow,red。
green表示所有的主分片和副本分片都正常运行,集群可以正常提供服务。
yellow表示所有主分片都正常运行,存在部分副分片非正常运行,集群可以正常提供服务。
red表示存在主分片非正常运行,集群无法提供服务。
可以通过命令
GET /_cluster/health
可以查看集群的健康状态
{
"cluster_name": "mycluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 3,
"number_of_data_nodes": 6,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
如果此时我们把上图中的slave_node关闭,此时查看集群的健康状态,会发现
status字段的值是red,因为主分片P1存储在slave_node上,此时不是所有主分片都正常。不过幸运的是,在其它节点上存在着主分片P1的完整副本, 所以master_node立即将P1的副分片R1,提升为主分片, 此时集群的状态将会为 yellow 。之所以变成yellow而不是green,是因为此时集群中只有一个主节点master_node,主分片P0,P1和P2的副分片无法正常运行(一个分片的主副分片无法分布在同一个节点上,存放在同一个节点上是没有意义的,无法起到故障转移的效果),此时集群中分片的分布如下:
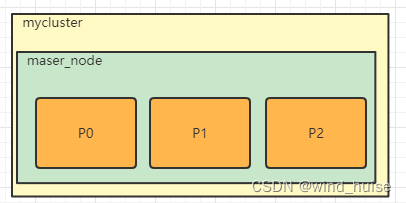
ES如何实现水平扩展
在上图中,每个节点上三个分片,也就是三个Lucene实例共用一个节点上的硬件资源,如果想要提升每个分片的数据处理性能,可以通过扩充节点个数,来提高每个分片可以使用的硬件资源,比如,我们可以向集群mycluster中在增加4个节点。当集群中存在6个节点时,每个节点上只分布一个分片,此时每个分片都会独享该节点上的所有资源,通过提升每个分片可利用的资源量来提升检索的性能,分片分布如下图:

如果此时检索性能仍不能满足需求,再单纯的增加节点,就不起作用了。因为一个分片只能在一个节点上运行,额外增加的节点将无法被使用。除非提升分片所在节点硬件配置。
因为在ES中,索引的分片副本数是可配置,所以可以增加索引分片的副本数,然后再扩充集群中节点的个数,这样可以减少每个分片处理的请求量,用更多的资源处理同样的请求量,来提升集群的检索性能,比如我们把索引myindex的分片副本调整为2:
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
此时索引的总分片个数就变成了9,此时我们把集群中的节点数扩充到9个,分片分布如下:
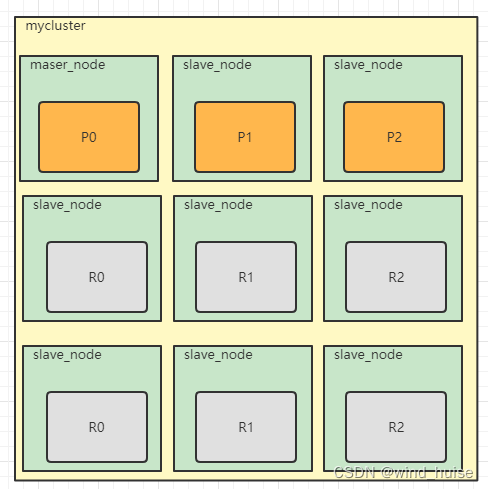
总结
上文中通过增加副本数,可以提升索引的检索性能,但是这里会有一个在分布式系统中通用的问题:副本越多,实现数据一致性的难度就越大,每次数据写入,保证所有副本数据一致的成本就会增加。从这里我们也可以发现,每个方案在某个场景下是一个好的方案,但是在另外的场景下可能会存在不足,也印证了软件系统中的一句名言:系统架构没有银弹,脱离业务场景的架构都是耍流氓。